| tests | ||
| .gitignore | ||
| 01_dataset.ipynb | ||
| 02_classification.ipynb | ||
| 02_classification.py | ||
| 03_data_update.ipynb | ||
| 04_multi_classification.ipynb | ||
| 05_model_training.ipynb | ||
| config.py | ||
| efficient_ui.py | ||
| elm.py | ||
| LICENSE | ||
| main_test.py | ||
| main.py | ||
| models.py | ||
| README.md | ||
| transmit.py | ||
| utils.py | ||
| valve_test.py | ||
烟梗彩色相机识别
2022年7月18日开始开发的项目,使用彩色相机进行烟梗颜色的识别。
如何进行模型训练和部署?
-
使用01_dataset.ipynb 进行数据集的分析文件格式需要设置为这种形式:
dataset ├── label │ ├── img1.bmp │ └── ... └── img ├── img1.bmp └── ... -
使用02_classification.ipynb进行训练
-
使用03_data_update.ipynb进行数据的更新与添加
-
使用
main_test.py文件进行读图测试 -
部署,复制
utils.py、models.py、main.py、models/、config.py这5个文件或文件夹,运行main.py来提供预测服务。
如何进行参数调节?
所有的参数均位于项目文件夹下的config.py当中。
class Config:
# 文件相关参数
nRows, nCols, nBands = 256, 1024, 22
nRgbRows, nRgbCols, nRgbBands = 1024, 4096, 3
# 需要设置的谱段等参数
selected_bands = [127, 201, 202, 294]
bands = [127, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210,
211, 212, 213, 214, 215, 216, 217, 218, 219, 294]
is_yellow_min = np.array([0.10167048, 0.1644719, 0.1598884, 0.31534621])
is_yellow_max = np.array([0.212984, 0.25896924, 0.26509268, 0.51943593])
is_black_threshold = np.asarray([0.1369, 0.1472, 0.1439, 0.1814])
black_yellow_bands = [0, 2, 3, 21]
green_bands = [i for i in range(1, 21)]
# 光谱模型参数
blk_size = 4 # 必须是2的倍数,不然会出错
pixel_model_path = r"./models/pixel_2022-08-02_15-22.model"
blk_model_path = r"./models/rf_4x4_c22_20_sen8_9.model"
spec_size_threshold = 3 # 光谱大小阈值
# rgb模型参数
rgb_tobacco_model_path = r"models/tobacco_dt_2022-08-05_10-38.model"
rgb_background_model_path = r"models/background_dt_2022-08-09_16-08.model"
threshold_low, threshold_high = 10, 230 # 亮度最高值和最低值
threshold_s = 190 # 饱和度最高值允许值,超过该饱和度会被当作杂质
rgb_size_threshold = 4 # RGB大小阈值(在运行时会被界面修改)
# mask parameter
target_size = (1024, 1024) # (Width, Height) of mask
valve_merge_size = 2 # 每两个喷阀当中有任意一个出现杂质则认为都是杂质
valve_horizontal_padding = 3 # 喷阀横向膨胀的尺寸,应该是奇数,3时表示左右各膨胀1
max_open_valve_limit = 25 # 最大同时开启喷阀限制,按照电流计算,当前的喷阀可以开启的喷阀 600W的电源 / 12V电源 = 50A, 一个阀门1A
# save part
offset_vertical = 0
# logging
root_dir = os.path.split(os.path.realpath(__file__))[0]
训练的原理
为了应对工业环境当中负样本少的特点,我们结合颜色有限空间的特性对我们的训练过程进行了优化,核心的优化方式在于制造负样本。
传统的负样本是怎么来的?
传统方法中,我们通过收集负样本,得到这样的结果:
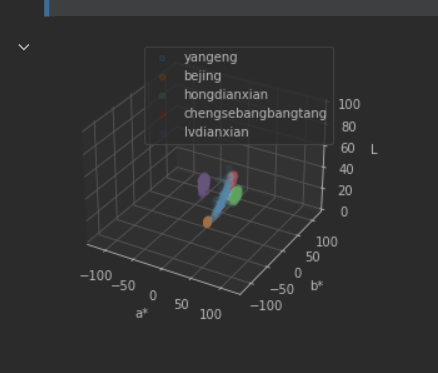
这张图里,负样本是紫色、红色和绿色区域,正样本则是蓝色区域。如果用这样的数据进行训练,我们得到的模型一定是欠约束的,因为我们不知道没有负样本的区域上,模型到底会表现出怎样的结果,所有我们想到,去手动制造负样本。
负样本是怎么造出来的?
我们对于一个给定的色彩空间进行随机的生成一些数据,然后判断它是否是给定的正样本附近,如果是在附近,那么我们就把这些点看作是正样本,如果离得比较远,那么就会被当作是负样本。
训练的结果
添加负样本后进行训练,模型就会被约束在我们给定的样本范围内,就像下图看到的这样。
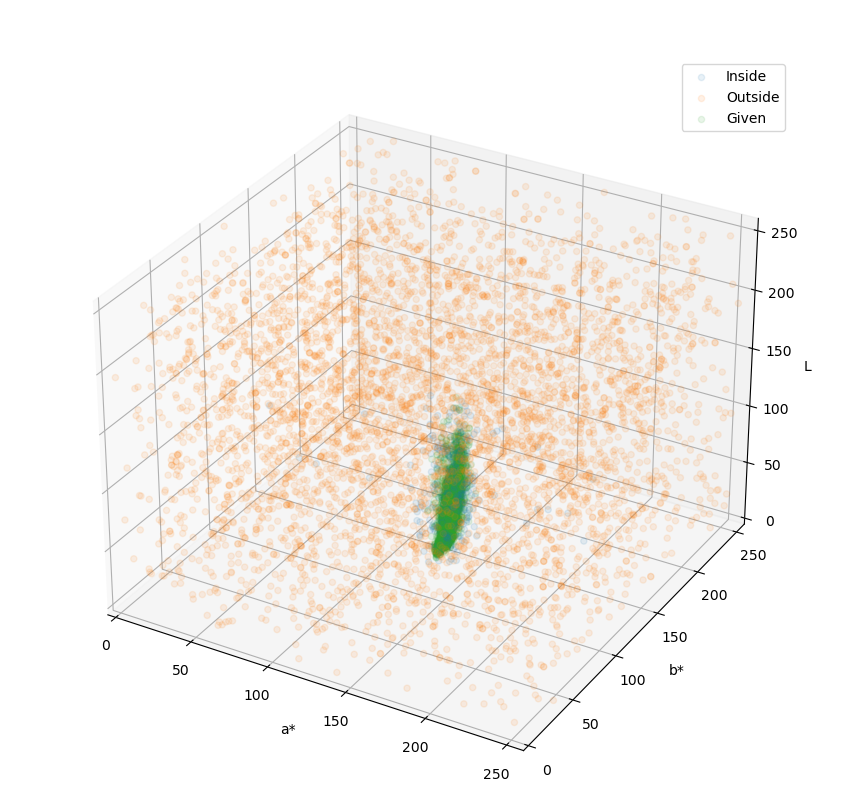
在这里,绿色就是目标(烟梗)的色彩范围,橙色的和蓝色则表明了模型的判定范围,模型认为蓝色的区域就是烟梗,而橙色的区域就不是烟梗。
可以看到,蓝色区域与绿色区域是高度重叠的,并且蓝色比绿色区域要大一些的,这正是我们想要的效果。这表明模型对于烟梗的颜色有适度的宽容,允许色彩有一定的偏差,但大体上是要达到烟梗颜色范围内的。
这样的好处在于,即使出现了新的杂质,只要这些杂质的色彩不在模型的宽容范围内(蓝色范围内),那么都会被判定为杂质。
我们甚至可以直接将需要的目标色彩(烟梗的颜色)和背景的颜色直接合并到一类,这样还可以节省后续的各种逻辑判断、与、或、非等操作。
预测出来的结果也相对理想,就像下边两张图展示的这样。
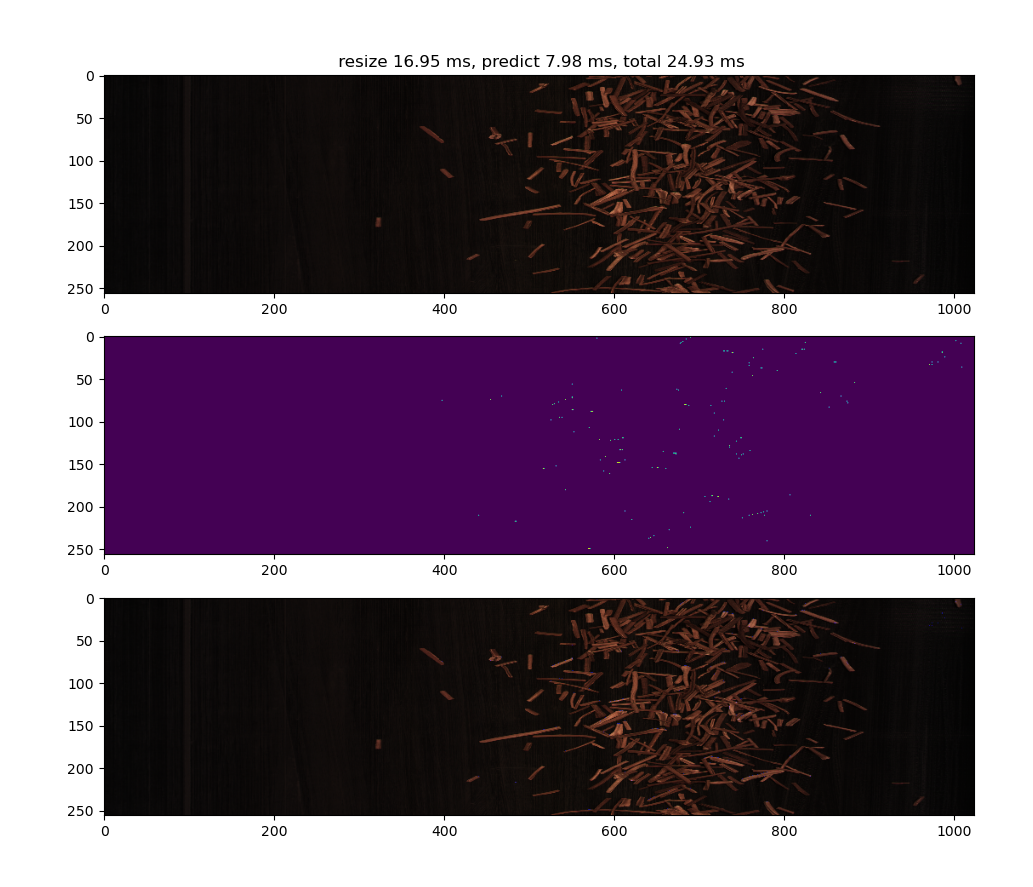
上图里可以看到烟梗和背景的错误识别点还是存在的,只是较为零散。

而从这张图就可以看出各类杂质识别还是没问题的。
接下来我们更换采集所使用的镜头,得到更宽广的视角范围并观察其变化。
镜头的影响
我们现有的镜头包括广角和窄角两个,这两个镜头有着不同的成像效果,如下图所示。
| 视角 | 广角镜头 | 窄角镜头 |
|---|---|---|
| 普通视角 |  |
 |
| 放大视角 |  |
 |
可以看到,镜头的影响有两方面
- 镜头会影响到物体的亮度,广角镜头下的物体看起来更暗
- 镜头会影响到物体的色彩,广角镜头下物体的色彩相比于窄角镜头的色彩饱和度要差很多,色相也有一定的偏移。
综合这两点来看,在条件允许的情况下应该选择窄角镜头。
但是我们这里的传送带非常宽,我们也只有1个相机,不像陶朗一样一条线有29个相机,或者合肥的一条线4~8个相机,所以我们只能冒险试试了。
尝试的结果很糟糕,可以看到如下图所示:
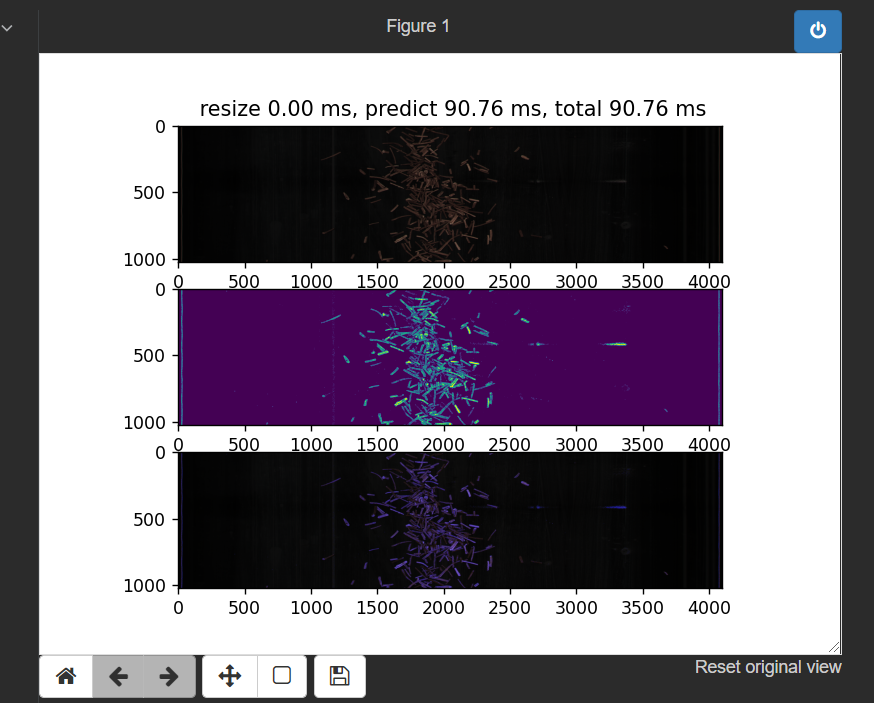
几乎所有的烟梗都被当成了杂质。
为了探究这个问题,我们回到色彩空间中进行观察,可以看到这样的结果:
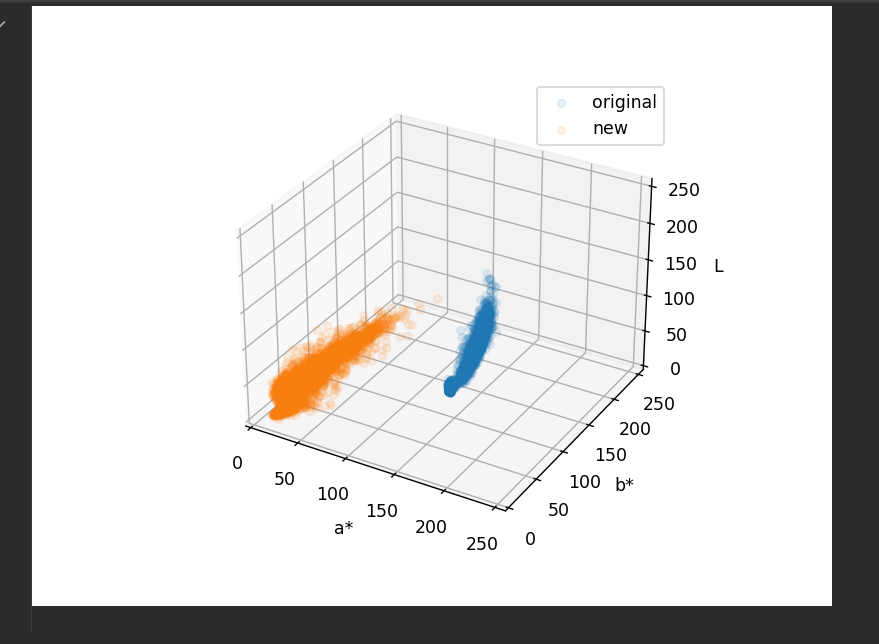
在新的镜头下,数据的分布和原本的数据已经发生了巨大的变化,根本就不是同一种东西,这就是为什么分类结果会出错了。 这种情况的出现也和拍摄矫正不到位有关,具体细节询问周超。
预测过程的后处理(异色问题)
问题的发现
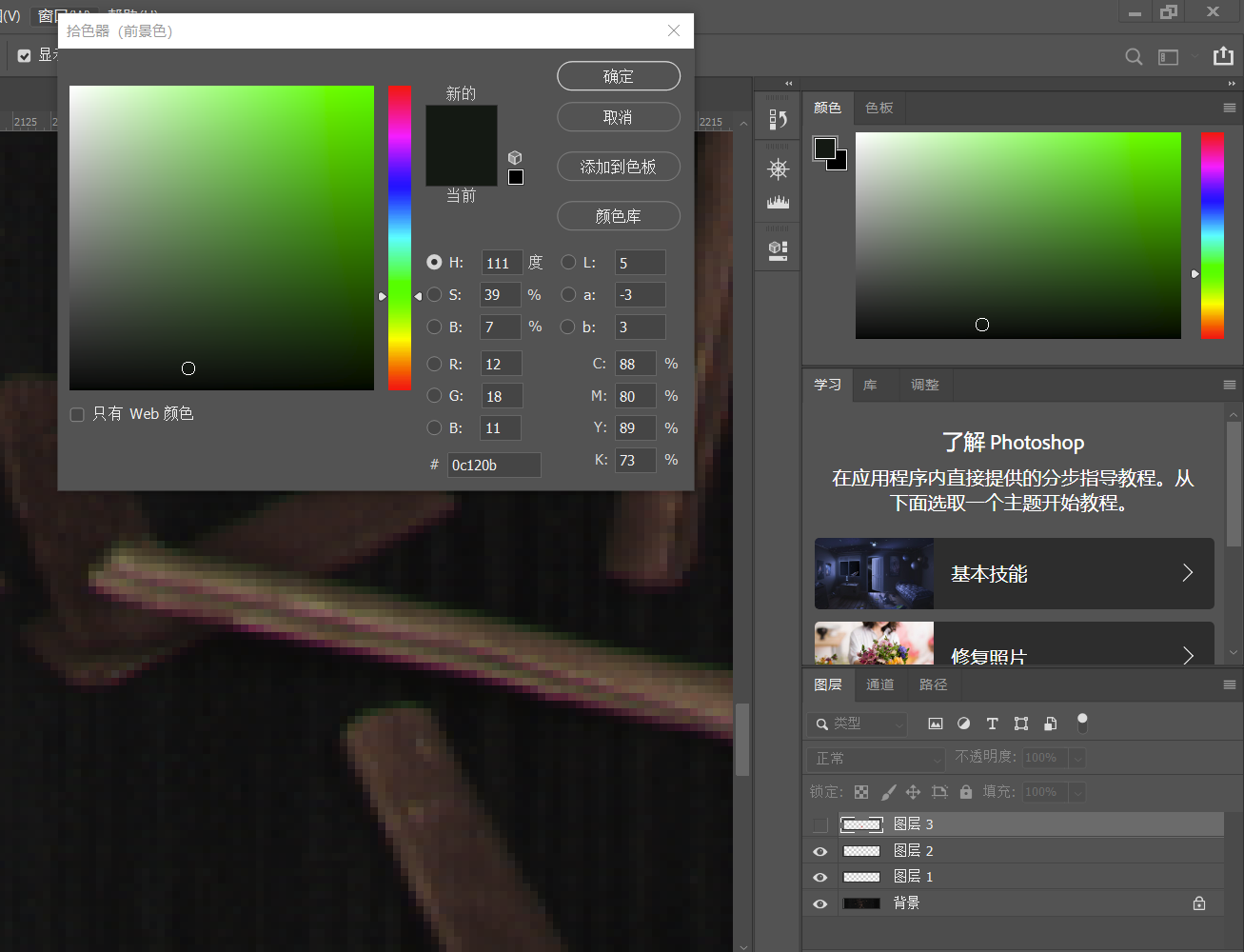
在摄影过程中,由于相机、镜头和拍摄物体多方面的原因会出现色散边的现象,就像上图这样本来应该黄色的烟梗,边缘却变成了暗绿色或紫色的。
这是由于不同波长的光折射率不同,到达成像单元的位置会出现细小的偏差,而我们的成像单元又比较的细小,举例来说,这可能使得物体上同样的点发出的红光到了1号像素,而发出的绿光本来应该也射到1号像素却射到了相邻的2号像素,这就导致色彩不对了。
根据资料,一般的解决方案是对于不同波长的光进行折射率补偿,使用抗色散镜头。但是由于条件有限,我们这里就只能用算法的形式硬抗这些误差了。
解决方案
- 一方面,用像素块的结果进行求和,像素块求和结果大于阈值的时候判定为杂质,这个方案目前正在使用,可以有效去除小块的错误识别点,也不会因为腐蚀操作导致缺损。
- 另一方面,进行烟梗结果的膨胀,去掉紫边。
模型的更新
如何应对新的目标物?
我们可以认为镜头的更换会直接让色彩发生特别离谱的变化,如果出现这样的情况,我们应该直接抛弃旧的数据,训练新的模型。这样也能获得相对不错的分类结果。
所以我们今天晚上要丢弃旧的数据,进行这个新的模型的训练。
在对这个模型进行重新训练后,获得的新模型识别结果如下图所示:
| 类别 | 图像 |
|---|---|
| 原图 |  |
| 识别结果 |  |
| 模型约束情况 | 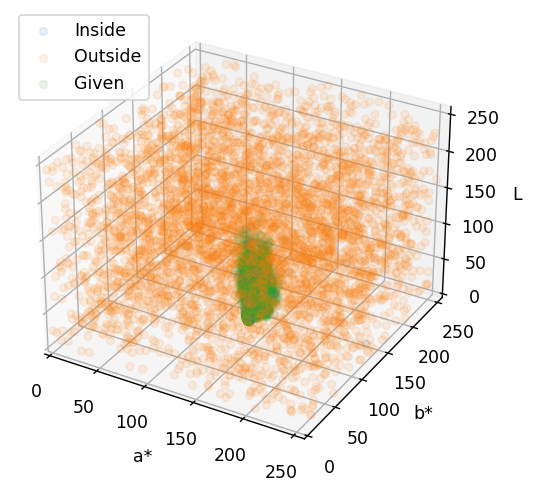 |
图像的对齐
引入了RGB和光谱图像的原因,这里牵扯到图像对齐的问题。
对齐检测算法
理论大概是这样,但是这不重要啦,简单来说就是偏差平面里头计算响应强度,这是当时的草稿。
实现以后这里可以看到对齐的结果,算法实现在main_test.py里头的calculate_delta():
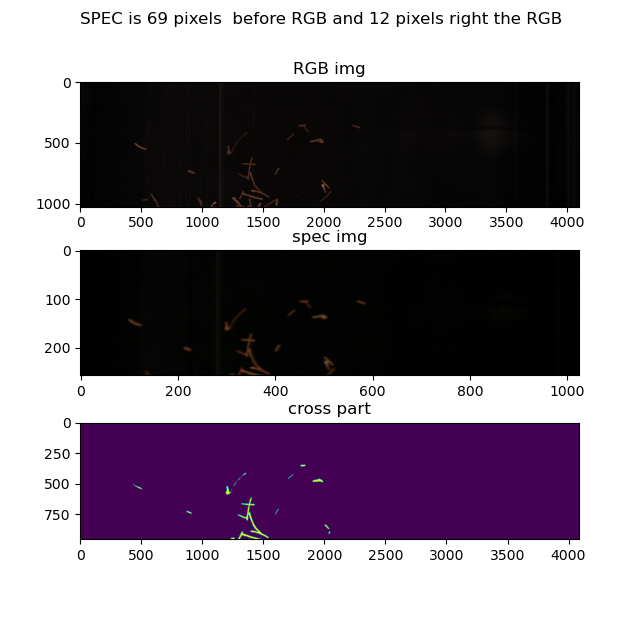
根据这张图片的换算结果可以得知光谱图像比RGB图像超前了69个像素,大概2.02厘米的样子。
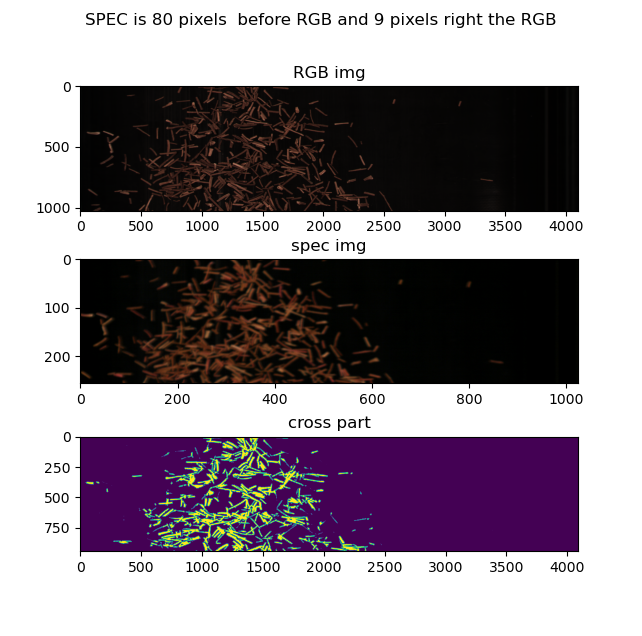
根据这张图片,可以得知,图像上下偏差是2.3厘米
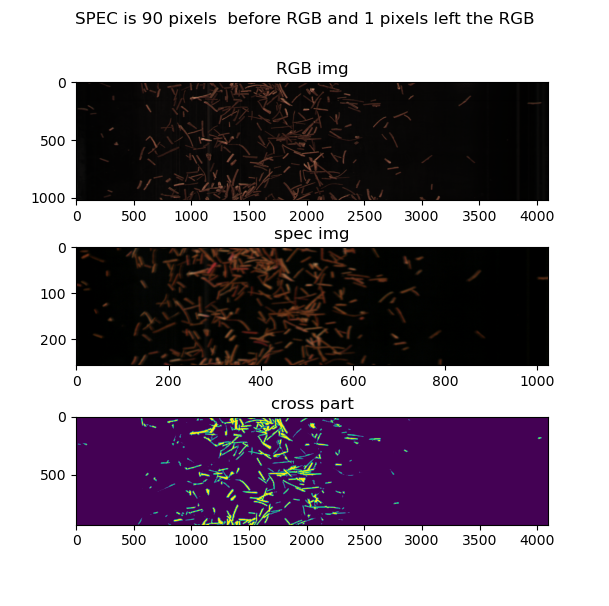
这张图片里的上下偏差则达到了2.6厘米左右。
图像拍摄脉冲触发问题
2022年7月30日我们进行了二次实验,本来以为会得到一个恒定的偏差结果,但是,情况并不像我们想的那样:

从这张图可以看到,两张图的偏差大概是上下10像素,RGB偏上,左右偏差19像素,RGB偏左,
但是!RGB图像明显是扭曲的,这显然是由于触发导致的。
从其他图片来看:

明显也存在图像扭曲的情况,偏差情况是:
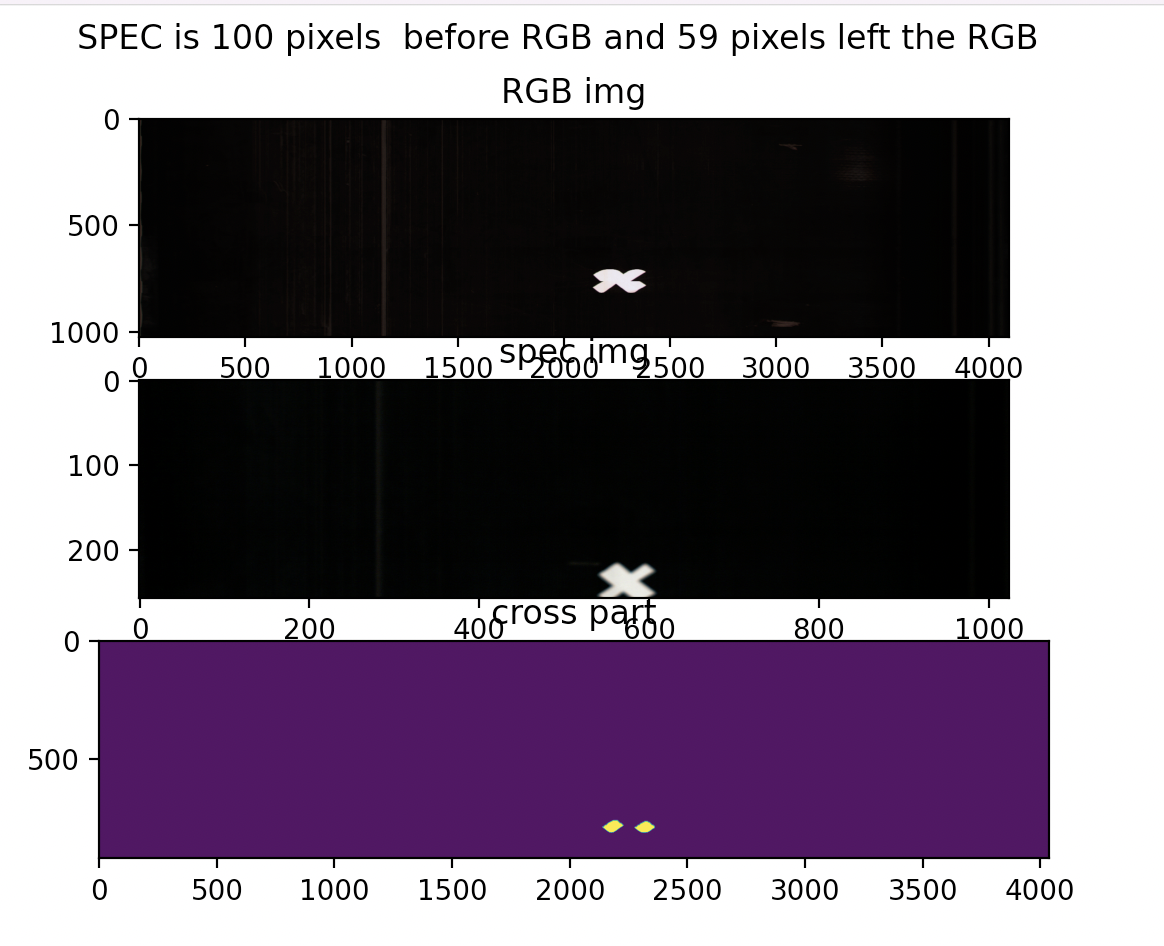 这张图上下已经对不上了,用它计算的偏差不具备参考价值。
这张图上下已经对不上了,用它计算的偏差不具备参考价值。

偏差的影响,也可从这幅图当中看到,这幅图的上下偏差达到了惊人的200像素,明显考虑是触发有问题了,不然偏差值至少是恒定的。
结论是考虑RGB相机的触发存在一定问题。
喷阀检查相关
喷阀检验脚本
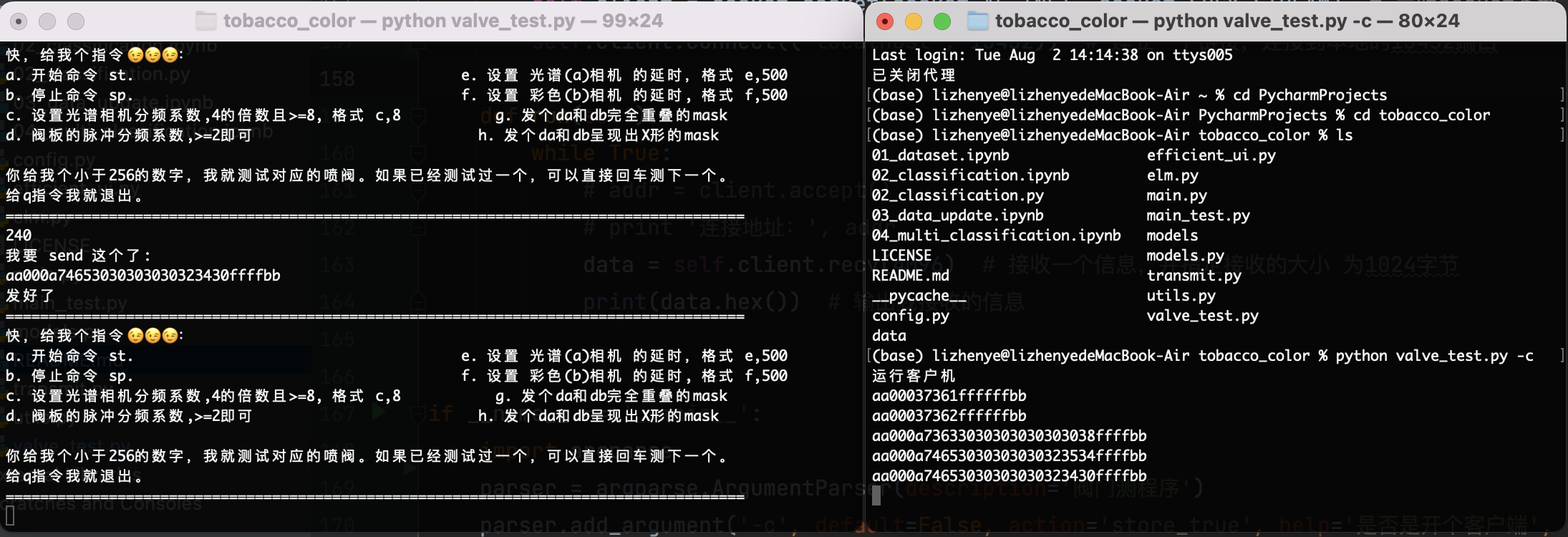
为了能够有效的对喷阀进行检查,我写了一个用于测试的小socket,这个小socket的使用方式是这样的:
开启服务端:
python valve_test.py
然后按照要求进行输入就可以了,我还在里头藏了个彩蛋,你猜猜是啥。
如果想要开客户端,可以加个参数,就像这样:
python valve_test.py -c
这个客户端啥也不会干,只会做去显示相应的收到的指令。
同时运行这两个可以在本地看到测试结果,不用看zynq那边的结果:
仅使用RGB或SPEC预测以调节延时
只使用RGB或者SPEC预测时,使用如下代码:
只使用rgb:
python main.py -oc
只使用SPEC
python main.py -os
同时开启喷阀数量限制
由于喷阀的电源有限,所以必须对同时开启的喷阀数量加以限制,否则会造成流在导线上的电流过大,就像是在烧水。
最大允许开启的喷阀数量$n$和电源功率$p$之间的关系如下:
n = \frac{p}{12}
这里$12 V \cdot A$是对应喷阀的电压和电流的乘积,建议在这个基础之上再进行数量除以$2$的操作,因为我们不可合并rgb和spec两个mask,所以如果当出现杂质时,仅对一个mask的最大值进行限定存在风险。
代码加密
本来想使用pyarmor,但是它在加密过程中一直重复不停的进行下载,这太麻烦了,而且还要考虑到兼容性问题,所以果断放弃,后来发现简单的方案是这样的,把python编译成字节码就行:
简单方案
这方案的好处在于不需要联网,但是破解成本比较低。
python -m compileall -f -q -b "tobacco_color"
然后接下来找到所有的.py文件并删除就可以了:
find . -name "*.py" -type f -print -exec rm -rf {} \;
这个看起来好危险,我还是觉得到目录下一个个删除比较好。
JMPY的方案
安装
pip install jmpy3
加密
jmpy -i "tobacco_color" [-o output dir]
加密后的文件默认存储在 dist/project_name/ 下
最后,根据测试的pyarmor并没有起到让人满意的加密效果,这令人很担忧,所以我暂时不购买测试。
开机自启动
要带有图形化界面的开机自启动不能把程序放到init.d底下,不然的话图形化界面还没起来就启动程序,会崩掉。
以.Desktop文件形式
-
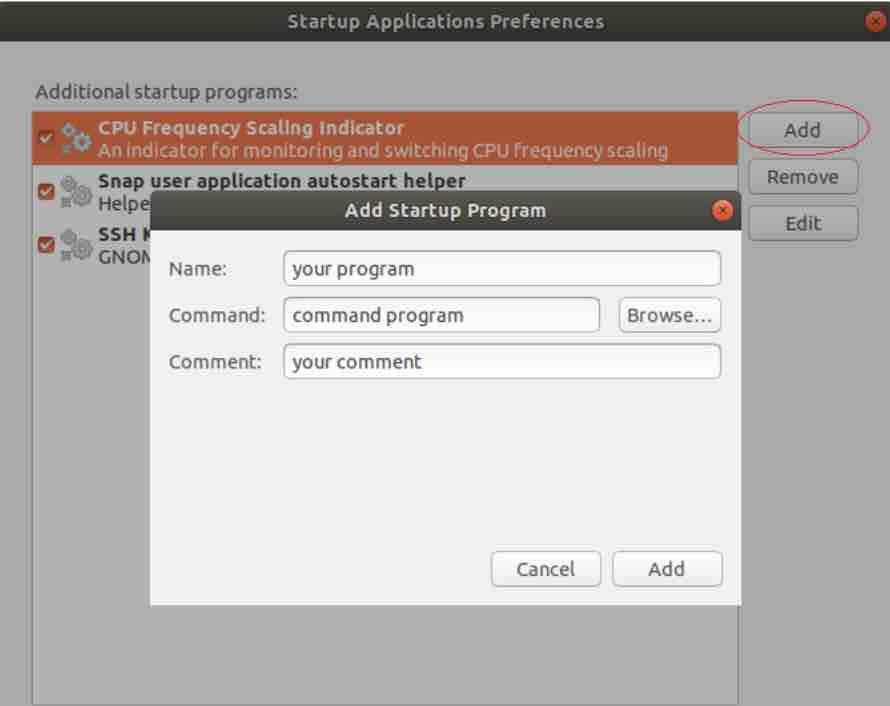
首先写一个
~/run.sh,内容如下:conda activate tobacco/deepo python /home/<user_name>/tobacco_color/main.py -os # 这里的os表示only spectral,还有oc,不加就是都用上。 -
然后,写一个.desktop文件
[Desktop Entry] Type=Application Name=Tobacco Exec=/home/<user_name>/run.sh Icon=/home/<user_name>/Pictures/albert # 图标 Comment=烟草识别程序 X-GNOME-Autostart-enabled=true -
把这个.desktop文件放到自启动目录下:
/home/<user_name>/.config/autostart
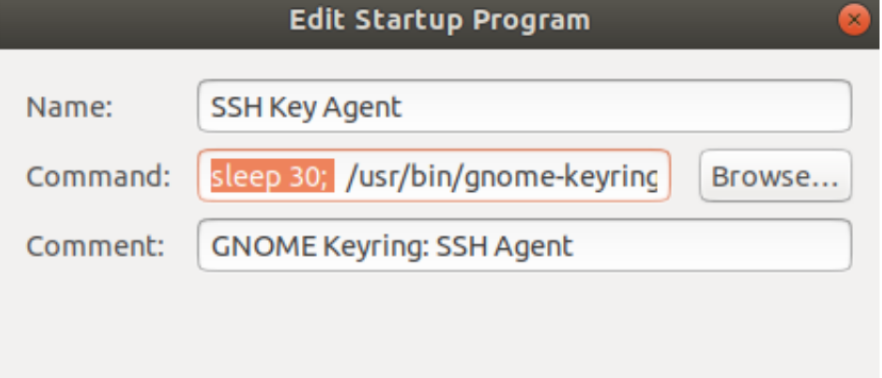
图形化形式
上一步当中run.sh是无论如何都要有的
中文里边叫开机自启动,
甚至可以加入延时:
模拟运行与文件转换
模拟运行
需要模拟运行的话可以使用main_test.py脚本进行。模拟运行的方法如下:
python main_test.py /path/to/test
其中/path/to/test填写C程序抓取的运行时数据。运行后的数据如下:
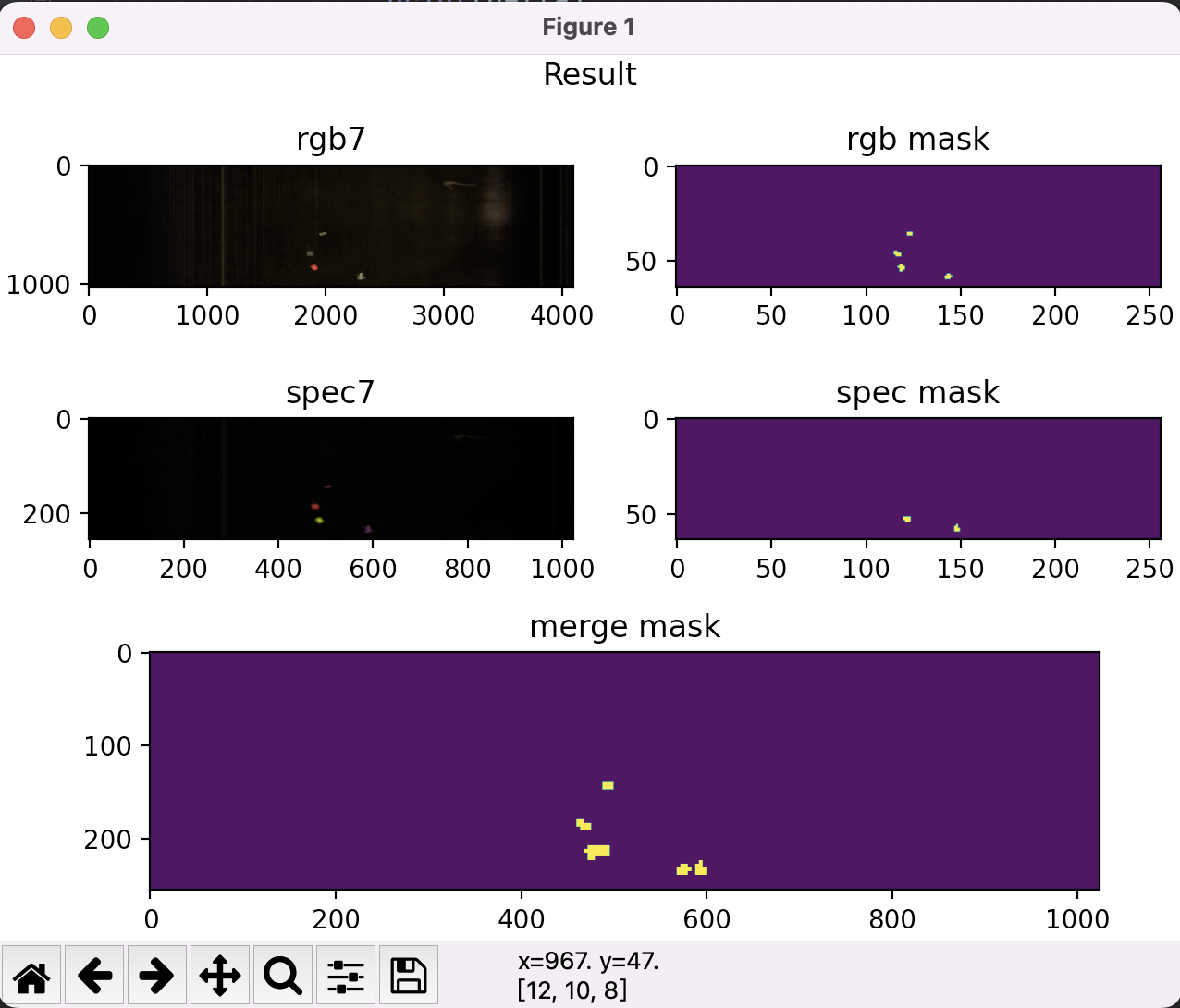
转换保存下来的buffer文件
脚本用法:
python main_test.py /path/to/convert -convert_dir /output/dir -s
这里path/to/convert填写转换的buffer文件夹,文件夹需要是只有rgb和spec文件/output/dir填输出文件夹,如果输出文件夹不存在就会创建。如果不加-s(--silent)静默参数就会顺便显示预测的结果。
转换后的图片经过测试可以正常在ENVI中打开:
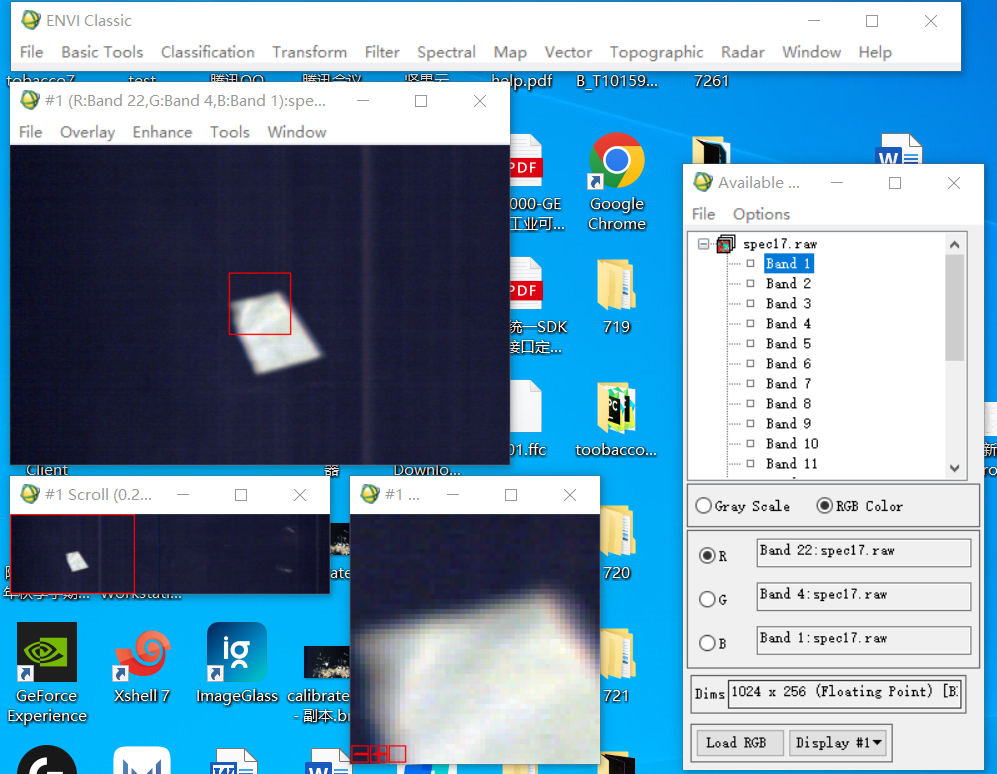
多线程读取与多进程预测
多线程与进程总体结构图
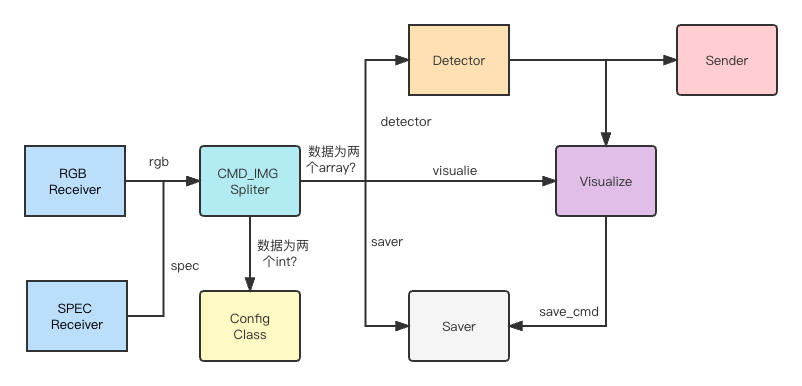
多线程读取
为了能够避免IO的等待,我们使用了开销相对较小的线程来实现多线程的数据读取。
因为很多时候我们需要读图测试,所以我们写了一个FileReceiver类,用法大概就像测试文件里这样:
def test_file_receiver(self):
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
image_queue = ImgQueue()
file_receiver = FileReceiver(job_name='rgb img receive', input_dir='../data', output_queue=image_queue,
speed=0.5, name_pattern=None)
virtual_data = np.zeros((1024, 4096, 3), dtype=np.uint8)
file_receiver.start(need_time=True, virtual_data=virtual_data)
for i in range(10):
data = image_queue.get()
time_record = data[0]
logging.info(f'Spent {(time.time() - time_record) * 1000:.2f}ms to get image with shape {data[-1].shape}')
self.assertEqual(data[-1].shape, (1024, 4096, 3))
file_receiver.stop()
测试结果如下所示:
2022-08-17 23:46:09,742 - root - INFO - rgb img receive thread start. 2022-08-17 23:46:09,754 - root - INFO - Spent 0.04ms to get image with shape (1024, 4096, 3) 2022-08-17 23:46:10,259 - root - INFO - sleep 0.5s ... 2022-08-17 23:46:10,276 - root - INFO - Spent 0.92ms to get image with shape (1024, 4096, 3) 2022-08-17 23:46:10,780 - root - INFO - sleep 0.5s ... 2022-08-17 23:46:10,789 - root - INFO - Spent 0.79ms to get image with shape (1024, 4096, 3) 2022-08-17 23:46:11,293 - root - INFO - sleep 0.5s ... 2022-08-17 23:46:11,301 - root - INFO - Spent 0.81ms to get image with shape (1024, 4096, 3) 2022-08-17 23:46:11,802 - root - INFO - sleep 0.5s ... 2022-08-17 23:46:11,810 - root - INFO - Spent 0.77ms to get image with shape (1024, 4096, 3) 2022-08-17 23:46:12,314 - root - INFO - sleep 0.5s ... 2022-08-17 23:46:12,315 - root - INFO - rgb img receive thread stop.
这里我们得到了一个惊人的数据传递速度,只花了将近1ms,这速度看着很不错哦。接下来我们把这东西变成多进程。