# 木地板分色识别项目
## 训练数据准备
请在使用前在同一文件夹下创建data文件夹,所需的文件目录如下:
```bash
.
├── README.md
├── classifer.py
├── data
│ ├── dark
│ ├── light
│ └── middle
```
上上面所示的三个文件夹下分别放置三种不同色彩的木板图片就可以训练了。
当然不要放除了图片外的东西,不然程序会出错哦。
## 色彩提取
下图为色彩提取效果:
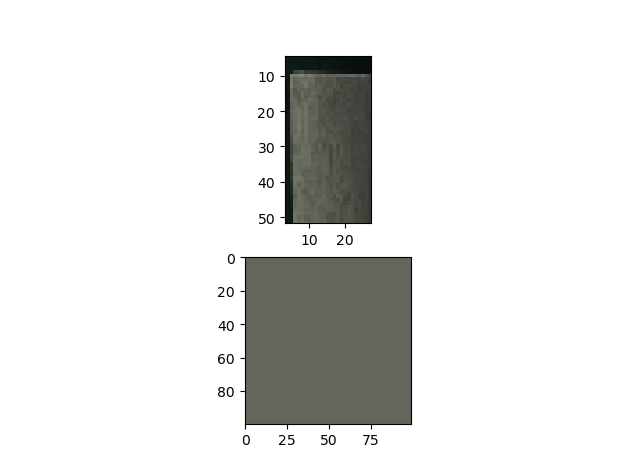
我们利用概率的方法以随机对抗随机,然后使用二项分布的概率分位点即可获得任意纯度下的木板色彩。
但是纯度过高有时反而会难以反映木板的颜色,所以关于纯度的取舍还需调整。目前的纯度要求0.99999下,该木板的分类效果好像可以有较好的表现,反正之后再调整嘛~
## 色彩分布
我们可以明显发现,在进行了色彩提纯后,色彩的区分度在lab空间下的ab平面还是很具备可分性的,所以直接用logistic regression这样的线性方法就够了。
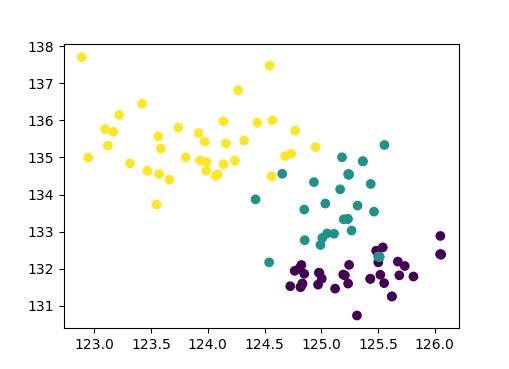
在classifer中还有6处简单的TODO, 交给老孙完成了,加油!

最终通过选择多次特征的组合,找到了效果比较好的特征 1 2 6 7 8 或 1 2 6 7
在数据集上的测试准确率为: 97.05%
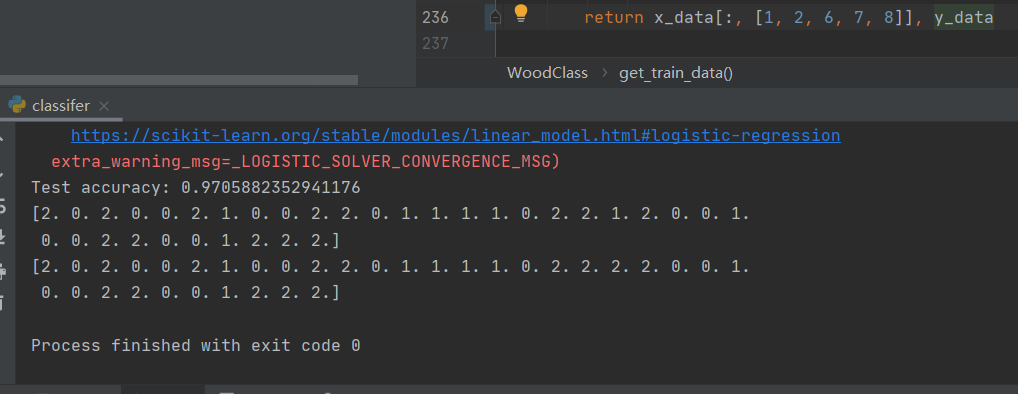
## 开机自启动
启动文件 xxx.bat 放在路径
```bash
C:\Users\你的用户名\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup
```
示例如下
```bash
@echo off
if "%1" == "h" goto begin
mshta vbscript:createobject("wscript.shell").run("""%~0"" h",0)(window.close)&&exit
:begin
call C:\Users\FEIJINTI\miniconda3\Scripts\activate.bat C:\Users\FEIJINTI\miniconda3
call conda activate cv
cd C:\Users\FEIJINTI\OneDrive - macrosolid\PycharmProjects\start_test
python 1.py
pause
```
其中第一段是为了不显示cmd窗口
第二段根据需求修改环境名以及启动程序
## 代码加密
安装
```bash
pip install jmpy3
```
```bash
# -*- coding: utf-8 -*-
"""
py文件加密为so或pyd
python代码 加密|加固
参数说明:
-i | --input_file_path 待加密文件或文件夹路径,可是相对路径或绝对路径
-o | --output_file_path 加密后的文件输出路径,默认在input_file_path下创建dist文件夹,存放加密后的文件
-I | --ignore_files 不需要加密的文件或文件夹,逗号分隔
-m | --except_main_file 不加密包含__main__的文件(主文件加密后无法启动), 值为0、1。 默认为1
报错:
AttributeError: 'str' object has no attribute 'decode'
找到报错文件:_msvccompiler.py
参考:https://blog.csdn.net/qq_43192819/article/details/108981008
128行代码修改为:.encode().decode('utf-16le', errors='replace')
"""
from jmpy.encrypt_py import start_encrypt
# 需要加密的py文件
input_file_path = "test.py"
# 直接运行
start_encrypt(input_file_path=input_file_path, output_file_path=None, ignore_files=None, except_main_file=0)
```
## 现场运行环境
下载在requirements.txt
```bash
matplotlib==3.5.3
numpy==1.21.6
opencv_contrib_python==4.7.0.72
opencv_python==4.7.0.72
scikit_learn==1.0.2
scipy==1.7.3
SQLAlchemy==2.0.19
```
## 通讯协议
OSI5~7层,基于单播TCP/IP,一包数据由8'haa打头,8'hbb结束,共6个字段:
| 起始 | 长度1 | 长度2 | 长度3 | 长度4 | 类型1 | 类型2 | 类型3 | 类型4 | 数据1 | 数据2 | ... | 数据i | 校验1 | 校验2 | 结束 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :--: | :---: | :---: | :---: | :---: |
| 8'haa | 8'hzz | 8'hzz | 8'hzz | 8'hzz | 8'hzz | 8'hzz | 8'hzz | 8'hzz | 8'hzz | 8'hzz | ... | 8'hzz | 8'hff | 8'hff | 8'hbb |
### 起始
1字节,8'haa
### 长度
一个32位无符号数length,长度 = 数据字节数i + 4 。
`长度1`指length[31:24],`长度2`指length[23:16],`长度3`指length[15:8],`长度4`指length[7:0]
### 类型&数据
ASCII字符,比如`类型1`为' '(空格),`类型2`为' '(空格),`类型3`为'I',`类型4`为'M',代表图像数据包
- **图像数据包' '' ''I''M'**,`数据1`~`数据i`包含了图像的行数rows、列数cols、谱段bands,$i-4=rows \times cols \times 3$具体如下:
| 行数1 | 行数2 | 列数1 | 列数2 | 谱段1 | 谱段2 | 图像数据1 | ... | 图像数据(i-4) |
| ---------- | --------- | ---------- | --------- |-------------|------------| --------- | ---- | ------------- |
| rows[15:8] | rows[7:0] | cols[15:8] | cols[7:0] | bands[15:8] | bands[7:0] | | ... | |
(此处设计在实际使用中吴大佬并未使用)接收方应当在收到图像数据包后发送' ''A''I''M'包表示已经收到,如下:
| 起始 | 长度1 | 长度2 | 长度3 | 长度4 | 类型1 | 类型2 | 类型3 | 类型4 | 数据1 | 校验1 | 校验2 | 结束 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| 8'haa | 8'd0 | 8'd0 | 8'd0 | 8'd5 | ' ' | 'A' | 'I' | 'M' | 8'hff | 8'hff | 8'hff | 8'hbb |
图像数据包的接收方应当在完成预测后发送包含预测结果`数据1`的' ''D''I''M'包,如下:
| 起始 | 长度1 | 长度2 | 长度3 | 长度4 | 类型1 | 类型2 | 类型3 | 类型4 | 数据 | 校验1 | 校验2 | 结束 |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |:-----:| :---: | :---: | :---: |
| 8'haa | 8'd0 | 8'd0 | 8'd0 | 8'd5 | ' ' | 'D' | 'I' | 'M' | 预测结果 | 8'hff | 8'hff | 8'hbb |
数据中每一个中心点坐标的格式为:
| 横坐标 | 纵坐标 | 标签类型 | 分隔符号 |
|-----|-----|---------|--------------|
| x, | y, | labels, | | |
### 校验
2字节,`校验1`为8'hff,`校验2`为8'hff
### 结束
1字节,8'hbb