mirror of
https://github.com/NanjingForestryUniversity/supermachine-tobacco.git
synced 2025-11-08 14:23:55 +00:00
Compare commits
84 Commits
perfect_ve
...
master
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
3b89dff026 | ||
|
|
c391cfa7d9 | ||
|
|
192bb8db99 | ||
|
|
c4191be192 | ||
|
|
f2c614dbcf | ||
|
|
2af3d8091f | ||
|
|
edd3b0f9c8 | ||
|
|
36735a3d4f | ||
|
|
7366830c41 | ||
|
|
b2f5cf276c | ||
|
|
e74aad7b36 | ||
|
|
e62fdf3630 | ||
|
|
6f2a9a1643 | ||
|
|
210c7354cf | ||
|
|
12870b3880 | ||
|
|
a803b1c905 | ||
| 127e57eca5 | |||
|
|
75ee16a9ad | ||
| b81c000d5a | |||
| 55c879d0d4 | |||
|
|
9b544a38d4 | ||
| 10a0a2b23a | |||
|
|
4bf6f50c61 | ||
| 5435723b4c | |||
|
|
b752bea8d4 | ||
|
|
74d2d031a3 | ||
| d01c689c7f | |||
| 6bdc464ca9 | |||
| 5754c74167 | |||
| 84199c1d75 | |||
| fa5f695d2c | |||
| a5ef5c9e11 | |||
| 1f62ba2e4e | |||
|
|
96085c3c49 | ||
|
|
bd3f677a83 | ||
| 15a126a3ea | |||
| 3cdafcd6fd | |||
| 483a78d423 | |||
| fd6671d3d4 | |||
| 92948f73d7 | |||
|
|
49b2ea4be7 | ||
|
|
30041c1aed | ||
|
|
15a465a6d1 | ||
| f561e631dd | |||
| 565589eb7d | |||
|
|
dcbc2f49eb | ||
| 4495d7f706 | |||
| 621b21651f | |||
| 9c6efbd937 | |||
| dd1e828d3e | |||
| 37d8dc43b0 | |||
|
|
677650ff48 | ||
|
|
d17baceac4 | ||
| 34d9e9a676 | |||
| 4d6fd3cd3a | |||
| 6831ffddff | |||
| 63c1f5cf22 | |||
|
|
14878662c1 | ||
| 5a34a5a7bd | |||
| e6ea7812d7 | |||
| bdbfd094e1 | |||
| 9e752003ae | |||
| dcc04f0667 | |||
| e58de3d57d | |||
| 8de85c2220 | |||
|
|
8c6007bc76 | ||
| 660711f6e6 | |||
| 7c469f9bf5 | |||
|
|
fe5eececc2 | ||
|
|
0e297c892c | ||
| e4cedc2516 | |||
|
|
cd4e12c46c | ||
|
|
8caffa55bc | ||
| d7f374d93c | |||
| 39d3aa4b59 | |||
| 65c988bb05 | |||
|
|
4c61c911e3 | ||
|
|
294bcda0d2 | ||
| 6f28756c1a | |||
| 54dd39daa8 | |||
| 5085fdbf1e | |||
| 1a19246dc3 | |||
|
|
144b88543d | ||
|
|
d29d465c7c |
4
.gitignore
vendored
4
.gitignore
vendored
@ -3,7 +3,9 @@
|
|||||||
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
|
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
|
||||||
|
|
||||||
data/*
|
data/*
|
||||||
models/*
|
weights/*
|
||||||
|
|
||||||
|
.idea/*
|
||||||
# User-specific stuff
|
# User-specific stuff
|
||||||
.idea/**/workspace.xml
|
.idea/**/workspace.xml
|
||||||
.idea/**/tasks.xml
|
.idea/**/tasks.xml
|
||||||
|
|||||||
File diff suppressed because one or more lines are too long
@ -12,7 +12,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 3,
|
"execution_count": 7,
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
@ -30,7 +30,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 4,
|
"execution_count": 8,
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"train_from_existed = False # 是否从现有数据训练,如果是的话,那就从dataset_file训练,否则就用data_dir里头的数据\n",
|
"train_from_existed = False # 是否从现有数据训练,如果是的话,那就从dataset_file训练,否则就用data_dir里头的数据\n",
|
||||||
@ -45,7 +45,7 @@
|
|||||||
"show_samples = False # 是否展示样本\n",
|
"show_samples = False # 是否展示样本\n",
|
||||||
"\n",
|
"\n",
|
||||||
"# 定义一些训练量\n",
|
"# 定义一些训练量\n",
|
||||||
"threshold = 2 # 正样本周围多大范围内的还算是正样本\n",
|
"threshold = 3 # 正样本周围多大范围内的还算是正样本\n",
|
||||||
"node_num = 20 # 如果使用ELM作为分类器物,有多少的节点\n",
|
"node_num = 20 # 如果使用ELM作为分类器物,有多少的节点\n",
|
||||||
"negative_sample_num = None # None或者一个数字,对应生成的负样本数量"
|
"negative_sample_num = None # None或者一个数字,对应生成的负样本数量"
|
||||||
],
|
],
|
||||||
@ -70,7 +70,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 5,
|
"execution_count": 9,
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"dataset = read_labeled_img(data_dir, color_dict=color_dict, is_ps_color_space=False)\n",
|
"dataset = read_labeled_img(data_dir, color_dict=color_dict, is_ps_color_space=False)\n",
|
||||||
@ -99,7 +99,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 6,
|
"execution_count": 4,
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"if len(dataset) > 1:\n",
|
"if len(dataset) > 1:\n",
|
||||||
@ -130,7 +130,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 7,
|
"execution_count": 5,
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"# 对数据进行预处理\n",
|
"# 对数据进行预处理\n",
|
||||||
@ -147,13 +147,13 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 8,
|
"execution_count": 6,
|
||||||
"outputs": [
|
"outputs": [
|
||||||
{
|
{
|
||||||
"name": "stderr",
|
"name": "stderr",
|
||||||
"output_type": "stream",
|
"output_type": "stream",
|
||||||
"text": [
|
"text": [
|
||||||
"38411it [02:01, 316.59it/s] \n"
|
"152147it [42:48, 59.24it/s] \n"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
@ -162,12 +162,12 @@
|
|||||||
"text": [
|
"text": [
|
||||||
" precision recall f1-score support\n",
|
" precision recall f1-score support\n",
|
||||||
"\n",
|
"\n",
|
||||||
" 0 1.00 1.00 1.00 11523\n",
|
" 0 1.00 1.00 1.00 45644\n",
|
||||||
" 1 1.00 1.00 1.00 9603\n",
|
" 1 1.00 1.00 1.00 38037\n",
|
||||||
"\n",
|
"\n",
|
||||||
" accuracy 1.00 21126\n",
|
" accuracy 1.00 83681\n",
|
||||||
" macro avg 1.00 1.00 1.00 21126\n",
|
" macro avg 1.00 1.00 1.00 83681\n",
|
||||||
"weighted avg 1.00 1.00 1.00 21126\n",
|
"weighted avg 1.00 1.00 1.00 83681\n",
|
||||||
"\n"
|
"\n"
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
|
|||||||
@ -23,10 +23,6 @@
|
|||||||
"import scipy.io\n",
|
"import scipy.io\n",
|
||||||
"import cv2\n",
|
"import cv2\n",
|
||||||
"import numpy as np\n",
|
"import numpy as np\n",
|
||||||
"import pickle\n",
|
|
||||||
"from sklearn.tree import DecisionTreeClassifier\n",
|
|
||||||
"# %matplotlib notebook\n",
|
|
||||||
"from main_test import pony_run\n",
|
|
||||||
"from models import AnonymousColorDetector\n",
|
"from models import AnonymousColorDetector\n",
|
||||||
"from utils import lab_scatter"
|
"from utils import lab_scatter"
|
||||||
],
|
],
|
||||||
|
|||||||
717
05_model_training.ipynb
Normal file
717
05_model_training.ipynb
Normal file
@ -0,0 +1,717 @@
|
|||||||
|
{
|
||||||
|
"cells": [
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 训练像素模型\n",
|
||||||
|
"用这个文件可以训练出需要使用的光谱像素点模型"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 1,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"ename": "NotImplementedError",
|
||||||
|
"evalue": "开发时和机器上部署的路径不同,请注意选择rgb_tobacco_model_path、rgb_background_model_path、ai_path后删除本行",
|
||||||
|
"output_type": "error",
|
||||||
|
"traceback": [
|
||||||
|
"\u001B[1;31m---------------------------------------------------------------------------\u001B[0m",
|
||||||
|
"\u001B[1;31mNotImplementedError\u001B[0m Traceback (most recent call last)",
|
||||||
|
"Input \u001B[1;32mIn [1]\u001B[0m, in \u001B[0;36m<cell line: 3>\u001B[1;34m()\u001B[0m\n\u001B[0;32m 1\u001B[0m \u001B[38;5;28;01mimport\u001B[39;00m \u001B[38;5;21;01mnumpy\u001B[39;00m \u001B[38;5;28;01mas\u001B[39;00m \u001B[38;5;21;01mnp\u001B[39;00m\n\u001B[0;32m 2\u001B[0m \u001B[38;5;28;01mimport\u001B[39;00m \u001B[38;5;21;01mpickle\u001B[39;00m\n\u001B[1;32m----> 3\u001B[0m \u001B[38;5;28;01mfrom\u001B[39;00m \u001B[38;5;21;01mutils\u001B[39;00m \u001B[38;5;28;01mimport\u001B[39;00m read_envi_ascii\n\u001B[0;32m 4\u001B[0m \u001B[38;5;66;03m# from config import Config\u001B[39;00m\n\u001B[0;32m 5\u001B[0m \u001B[38;5;28;01mfrom\u001B[39;00m \u001B[38;5;21;01mmodels\u001B[39;00m \u001B[38;5;28;01mimport\u001B[39;00m ManualTree\n",
|
||||||
|
"File \u001B[1;32m~\\OneDrive - macrosolid\\PycharmProjects\\tobacco_color\\utils\\__init__.py:20\u001B[0m, in \u001B[0;36m<module>\u001B[1;34m\u001B[0m\n\u001B[0;32m 17\u001B[0m \u001B[38;5;28;01mfrom\u001B[39;00m \u001B[38;5;21;01mmatplotlib\u001B[39;00m \u001B[38;5;28;01mimport\u001B[39;00m pyplot \u001B[38;5;28;01mas\u001B[39;00m plt\n\u001B[0;32m 18\u001B[0m \u001B[38;5;28;01mimport\u001B[39;00m \u001B[38;5;21;01mre\u001B[39;00m\n\u001B[1;32m---> 20\u001B[0m \u001B[38;5;28;01mfrom\u001B[39;00m \u001B[38;5;21;01mconfig\u001B[39;00m \u001B[38;5;28;01mimport\u001B[39;00m Config\n\u001B[0;32m 23\u001B[0m \u001B[38;5;28;01mdef\u001B[39;00m \u001B[38;5;21mnatural_sort\u001B[39m(l):\n\u001B[0;32m 24\u001B[0m \u001B[38;5;124;03m\"\"\"\u001B[39;00m\n\u001B[0;32m 25\u001B[0m \u001B[38;5;124;03m 自然排序\u001B[39;00m\n\u001B[0;32m 26\u001B[0m \u001B[38;5;124;03m :param l: 待排序\u001B[39;00m\n\u001B[0;32m 27\u001B[0m \u001B[38;5;124;03m :return:\u001B[39;00m\n\u001B[0;32m 28\u001B[0m \u001B[38;5;124;03m \"\"\"\u001B[39;00m\n",
|
||||||
|
"File \u001B[1;32m~\\OneDrive - macrosolid\\PycharmProjects\\tobacco_color\\config.py:6\u001B[0m, in \u001B[0;36m<module>\u001B[1;34m\u001B[0m\n\u001B[0;32m 1\u001B[0m \u001B[38;5;28;01mimport\u001B[39;00m \u001B[38;5;21;01mos\u001B[39;00m\n\u001B[0;32m 3\u001B[0m \u001B[38;5;28;01mimport\u001B[39;00m \u001B[38;5;21;01mnumpy\u001B[39;00m \u001B[38;5;28;01mas\u001B[39;00m \u001B[38;5;21;01mnp\u001B[39;00m\n\u001B[1;32m----> 6\u001B[0m \u001B[38;5;28;01mclass\u001B[39;00m \u001B[38;5;21;01mConfig\u001B[39;00m:\n\u001B[0;32m 7\u001B[0m \u001B[38;5;66;03m# 文件相关参数\u001B[39;00m\n\u001B[0;32m 8\u001B[0m nRows, nCols, nBands \u001B[38;5;241m=\u001B[39m \u001B[38;5;241m256\u001B[39m, \u001B[38;5;241m1024\u001B[39m, \u001B[38;5;241m22\u001B[39m\n\u001B[0;32m 9\u001B[0m nRgbRows, nRgbCols, nRgbBands \u001B[38;5;241m=\u001B[39m \u001B[38;5;241m1024\u001B[39m, \u001B[38;5;241m4096\u001B[39m, \u001B[38;5;241m3\u001B[39m\n",
|
||||||
|
"File \u001B[1;32m~\\OneDrive - macrosolid\\PycharmProjects\\tobacco_color\\config.py:31\u001B[0m, in \u001B[0;36mConfig\u001B[1;34m()\u001B[0m\n\u001B[0;32m 28\u001B[0m spec_size_threshold \u001B[38;5;241m=\u001B[39m \u001B[38;5;241m3\u001B[39m\n\u001B[0;32m 30\u001B[0m \u001B[38;5;66;03m# rgb模型参数\u001B[39;00m\n\u001B[1;32m---> 31\u001B[0m \u001B[38;5;28;01mraise\u001B[39;00m \u001B[38;5;167;01mNotImplementedError\u001B[39;00m(\u001B[38;5;124m\"\u001B[39m\u001B[38;5;124m开发时和机器上部署的路径不同,请注意选择rgb_tobacco_model_path、rgb_background_model_path、ai_path后删除本行\u001B[39m\u001B[38;5;124m\"\u001B[39m)\n\u001B[0;32m 32\u001B[0m \u001B[38;5;66;03m# rgb_tobacco_model_path = r\"weights/tobacco_dt_2022-08-27_14-43.model\" # 开发时的路径\u001B[39;00m\n\u001B[0;32m 33\u001B[0m \u001B[38;5;66;03m# rgb_tobacco_model_path = r\"/home/dt/tobacco-color/weights/tobacco_dt_2022-08-27_14-43.model\" # 机器上部署的路径\u001B[39;00m\n\u001B[0;32m 34\u001B[0m \u001B[38;5;66;03m# rgb_background_model_path = r\"weights/background_dt_2022-08-22_22-15.model\" # 开发时的路径\u001B[39;00m\n\u001B[0;32m 35\u001B[0m \u001B[38;5;66;03m# rgb_background_model_path = r\"/home/dt/tobacco-color/weights/background_dt_2022-08-22_22-15.model\" # 机器上部署的路径\u001B[39;00m\n\u001B[0;32m 36\u001B[0m threshold_low, threshold_high \u001B[38;5;241m=\u001B[39m \u001B[38;5;241m10\u001B[39m, \u001B[38;5;241m230\u001B[39m\n",
|
||||||
|
"\u001B[1;31mNotImplementedError\u001B[0m: 开发时和机器上部署的路径不同,请注意选择rgb_tobacco_model_path、rgb_background_model_path、ai_path后删除本行"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"import numpy as np\n",
|
||||||
|
"import pickle\n",
|
||||||
|
"from utils import read_envi_ascii\n",
|
||||||
|
"from config import Config\n",
|
||||||
|
"from models import ManualTree"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 一些变量"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 4,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"data_path = r'data/envi20220802.txt'\n",
|
||||||
|
"name_dict = {'tobacco': 1, 'yantou':2, 'kazhi':3, 'bomo':4, 'jiaodai':5, 'background':0}"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 构建数据集"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 5,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"data = read_envi_ascii(data_path)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 6,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
"zibian (569, 448)\n",
|
||||||
|
"tobacco (1457, 448)\n",
|
||||||
|
"yantou (354, 448)\n",
|
||||||
|
"kazhi (449, 448)\n",
|
||||||
|
"bomo (1154, 448)\n",
|
||||||
|
"jiaodai (566, 448)\n",
|
||||||
|
"background (1235, 448)\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"_ = [print(class_name, d.shape) for class_name, d in data.items()]"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 7,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"data_x = [d for class_name, d in data.items() if class_name in name_dict.keys()]\n",
|
||||||
|
"data_y = [np.ones((d.shape[0], ))*name_dict[class_name] for class_name, d in data.items() if class_name in name_dict.keys()]\n",
|
||||||
|
"data_x, data_y = np.concatenate(data_x), np.concatenate(data_y)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 取出需要的22个特征谱段"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 8,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
"这些是现在的数据: (5215, 448) (5215,)\n",
|
||||||
|
"截取其中需要的部分后: (5215, 22) (5215,)\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"print(\"这些是现在的数据: \", data_x.shape, data_y.shape)\n",
|
||||||
|
"data_x_cut = data_x[..., Config.bands]\n",
|
||||||
|
"print(\"截取其中需要的部分后: \", data_x_cut.shape, data_y.shape)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 进行样本平衡"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 9,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
"这是重采样后的数据: (8742, 22) (8742,)\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"from imblearn.over_sampling import RandomOverSampler\n",
|
||||||
|
"ros = RandomOverSampler(random_state=0)\n",
|
||||||
|
"x_resampled, y_resampled = ros.fit_resample(data_x_cut, data_y)\n",
|
||||||
|
"print('这是重采样后的数据: ', x_resampled.shape, y_resampled.shape)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 进行模型训练\n",
|
||||||
|
"分出一部分数据进行训练"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 10,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from models import DecisionTree\n",
|
||||||
|
"from sklearn.model_selection import train_test_split"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 11,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"train_x, test_x, train_y, test_y = train_test_split(x_resampled, y_resampled, test_size=0.2)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 12,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"tree = DecisionTree(class_weight={1:20})"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 13,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"tree = tree.fit(train_x, train_y)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 模型评估"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 多分类精度"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 14,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"pred_y = tree.predict(test_x)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 15,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
" precision recall f1-score support\n",
|
||||||
|
"\n",
|
||||||
|
" 0.0 1.00 1.00 1.00 312\n",
|
||||||
|
" 1.0 0.98 0.97 0.98 289\n",
|
||||||
|
" 2.0 0.97 1.00 0.99 312\n",
|
||||||
|
" 3.0 0.95 0.99 0.97 278\n",
|
||||||
|
" 4.0 0.98 0.92 0.95 288\n",
|
||||||
|
" 5.0 0.98 0.98 0.98 270\n",
|
||||||
|
"\n",
|
||||||
|
" accuracy 0.98 1749\n",
|
||||||
|
" macro avg 0.98 0.98 0.98 1749\n",
|
||||||
|
"weighted avg 0.98 0.98 0.98 1749\n",
|
||||||
|
"\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"from sklearn.metrics import classification_report\n",
|
||||||
|
"\n",
|
||||||
|
"print(classification_report(y_pred=pred_y, y_true=test_y))"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 二分类精度"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 16,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"test_y[test_y <= 1] = 0\n",
|
||||||
|
"test_y[test_y > 1] = 1\n",
|
||||||
|
"pred_y = tree.predict_bin(test_x)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 17,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
" precision recall f1-score support\n",
|
||||||
|
"\n",
|
||||||
|
" 0.0 1.00 1.00 1.00 598\n",
|
||||||
|
" 1.0 1.00 1.00 1.00 1151\n",
|
||||||
|
"\n",
|
||||||
|
" accuracy 1.00 1749\n",
|
||||||
|
" macro avg 1.00 1.00 1.00 1749\n",
|
||||||
|
"weighted avg 1.00 1.00 1.00 1749\n",
|
||||||
|
"\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"print(classification_report(y_true=pred_y, y_pred=pred_y))"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 模型保存"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 18,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import datetime\n",
|
||||||
|
"\n",
|
||||||
|
"path = datetime.datetime.now().strftime(f\"models/pixel_%Y-%m-%d_%H-%M.model\")\n",
|
||||||
|
"with open(path, 'wb') as f:\n",
|
||||||
|
" pickle.dump(tree, f)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 8,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"from models import DecisionTree\n",
|
||||||
|
"from sklearn.model_selection import train_test_split"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 9,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"train_x, test_x, train_y, test_y = train_test_split(x_resampled, y_resampled, test_size=0.2)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 11,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"tree = DecisionTree(class_weight={1:20})"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 12,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"tree = tree.fit(train_x, train_y)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 模型评估"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 多分类精度"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 13,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"pred_y = tree.predict(test_x)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 14,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
" precision recall f1-score support\n",
|
||||||
|
"\n",
|
||||||
|
" 0.0 1.00 1.00 1.00 304\n",
|
||||||
|
" 1.0 0.97 0.98 0.97 275\n",
|
||||||
|
" 2.0 0.98 1.00 0.99 297\n",
|
||||||
|
" 3.0 0.95 0.99 0.97 293\n",
|
||||||
|
" 4.0 0.98 0.91 0.95 316\n",
|
||||||
|
" 5.0 0.98 0.98 0.98 264\n",
|
||||||
|
"\n",
|
||||||
|
" accuracy 0.98 1749\n",
|
||||||
|
" macro avg 0.98 0.98 0.98 1749\n",
|
||||||
|
"weighted avg 0.98 0.98 0.98 1749\n",
|
||||||
|
"\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"from sklearn.metrics import classification_report\n",
|
||||||
|
"\n",
|
||||||
|
"print(classification_report(y_pred=pred_y, y_true=test_y))"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 二分类精度"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 19,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"test_y[test_y <= 1] = 0\n",
|
||||||
|
"test_y[test_y > 1] = 1\n",
|
||||||
|
"pred_y = tree.predict_bin(test_x)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 20,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"name": "stdout",
|
||||||
|
"output_type": "stream",
|
||||||
|
"text": [
|
||||||
|
" precision recall f1-score support\n",
|
||||||
|
"\n",
|
||||||
|
" 0.0 1.00 1.00 1.00 582\n",
|
||||||
|
" 1.0 1.00 1.00 1.00 1167\n",
|
||||||
|
"\n",
|
||||||
|
" accuracy 1.00 1749\n",
|
||||||
|
" macro avg 1.00 1.00 1.00 1749\n",
|
||||||
|
"weighted avg 1.00 1.00 1.00 1749\n",
|
||||||
|
"\n"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"print(classification_report(y_true=pred_y, y_pred=pred_y))"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"# 模型保存"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%% md\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 22,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [
|
||||||
|
"import datetime\n",
|
||||||
|
"\n",
|
||||||
|
"path = datetime.datetime.now().strftime(f\"models/pixel_%Y-%m-%d_%H-%M.model\")\n",
|
||||||
|
"with open(path, 'wb') as f:\n",
|
||||||
|
" pickle.dump(tree, f)"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": null,
|
||||||
|
"outputs": [],
|
||||||
|
"source": [],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"kernelspec": {
|
||||||
|
"display_name": "Python 3",
|
||||||
|
"language": "python",
|
||||||
|
"name": "python3"
|
||||||
|
},
|
||||||
|
"language_info": {
|
||||||
|
"codemirror_mode": {
|
||||||
|
"name": "ipython",
|
||||||
|
"version": 2
|
||||||
|
},
|
||||||
|
"file_extension": ".py",
|
||||||
|
"mimetype": "text/x-python",
|
||||||
|
"name": "python",
|
||||||
|
"nbconvert_exporter": "python",
|
||||||
|
"pygments_lexer": "ipython2",
|
||||||
|
"version": "2.7.6"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"nbformat": 4,
|
||||||
|
"nbformat_minor": 0
|
||||||
|
}
|
||||||
661
LICENSE
Normal file
661
LICENSE
Normal file
@ -0,0 +1,661 @@
|
|||||||
|
GNU AFFERO GENERAL PUBLIC LICENSE
|
||||||
|
Version 3, 19 November 2007
|
||||||
|
|
||||||
|
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/>
|
||||||
|
Everyone is permitted to copy and distribute verbatim copies
|
||||||
|
of this license document, but changing it is not allowed.
|
||||||
|
|
||||||
|
Preamble
|
||||||
|
|
||||||
|
The GNU Affero General Public License is a free, copyleft license for
|
||||||
|
software and other kinds of works, specifically designed to ensure
|
||||||
|
cooperation with the community in the case of network server software.
|
||||||
|
|
||||||
|
The licenses for most software and other practical works are designed
|
||||||
|
to take away your freedom to share and change the works. By contrast,
|
||||||
|
our General Public Licenses are intended to guarantee your freedom to
|
||||||
|
share and change all versions of a program--to make sure it remains free
|
||||||
|
software for all its users.
|
||||||
|
|
||||||
|
When we speak of free software, we are referring to freedom, not
|
||||||
|
price. Our General Public Licenses are designed to make sure that you
|
||||||
|
have the freedom to distribute copies of free software (and charge for
|
||||||
|
them if you wish), that you receive source code or can get it if you
|
||||||
|
want it, that you can change the software or use pieces of it in new
|
||||||
|
free programs, and that you know you can do these things.
|
||||||
|
|
||||||
|
Developers that use our General Public Licenses protect your rights
|
||||||
|
with two steps: (1) assert copyright on the software, and (2) offer
|
||||||
|
you this License which gives you legal permission to copy, distribute
|
||||||
|
and/or modify the software.
|
||||||
|
|
||||||
|
A secondary benefit of defending all users' freedom is that
|
||||||
|
improvements made in alternate versions of the program, if they
|
||||||
|
receive widespread use, become available for other developers to
|
||||||
|
incorporate. Many developers of free software are heartened and
|
||||||
|
encouraged by the resulting cooperation. However, in the case of
|
||||||
|
software used on network servers, this result may fail to come about.
|
||||||
|
The GNU General Public License permits making a modified version and
|
||||||
|
letting the public access it on a server without ever releasing its
|
||||||
|
source code to the public.
|
||||||
|
|
||||||
|
The GNU Affero General Public License is designed specifically to
|
||||||
|
ensure that, in such cases, the modified source code becomes available
|
||||||
|
to the community. It requires the operator of a network server to
|
||||||
|
provide the source code of the modified version running there to the
|
||||||
|
users of that server. Therefore, public use of a modified version, on
|
||||||
|
a publicly accessible server, gives the public access to the source
|
||||||
|
code of the modified version.
|
||||||
|
|
||||||
|
An older license, called the Affero General Public License and
|
||||||
|
published by Affero, was designed to accomplish similar goals. This is
|
||||||
|
a different license, not a version of the Affero GPL, but Affero has
|
||||||
|
released a new version of the Affero GPL which permits relicensing under
|
||||||
|
this license.
|
||||||
|
|
||||||
|
The precise terms and conditions for copying, distribution and
|
||||||
|
modification follow.
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
0. Definitions.
|
||||||
|
|
||||||
|
"This License" refers to version 3 of the GNU Affero General Public License.
|
||||||
|
|
||||||
|
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||||
|
works, such as semiconductor masks.
|
||||||
|
|
||||||
|
"The Program" refers to any copyrightable work licensed under this
|
||||||
|
License. Each licensee is addressed as "you". "Licensees" and
|
||||||
|
"recipients" may be individuals or organizations.
|
||||||
|
|
||||||
|
To "modify" a work means to copy from or adapt all or part of the work
|
||||||
|
in a fashion requiring copyright permission, other than the making of an
|
||||||
|
exact copy. The resulting work is called a "modified version" of the
|
||||||
|
earlier work or a work "based on" the earlier work.
|
||||||
|
|
||||||
|
A "covered work" means either the unmodified Program or a work based
|
||||||
|
on the Program.
|
||||||
|
|
||||||
|
To "propagate" a work means to do anything with it that, without
|
||||||
|
permission, would make you directly or secondarily liable for
|
||||||
|
infringement under applicable copyright law, except executing it on a
|
||||||
|
computer or modifying a private copy. Propagation includes copying,
|
||||||
|
distribution (with or without modification), making available to the
|
||||||
|
public, and in some countries other activities as well.
|
||||||
|
|
||||||
|
To "convey" a work means any kind of propagation that enables other
|
||||||
|
parties to make or receive copies. Mere interaction with a user through
|
||||||
|
a computer network, with no transfer of a copy, is not conveying.
|
||||||
|
|
||||||
|
An interactive user interface displays "Appropriate Legal Notices"
|
||||||
|
to the extent that it includes a convenient and prominently visible
|
||||||
|
feature that (1) displays an appropriate copyright notice, and (2)
|
||||||
|
tells the user that there is no warranty for the work (except to the
|
||||||
|
extent that warranties are provided), that licensees may convey the
|
||||||
|
work under this License, and how to view a copy of this License. If
|
||||||
|
the interface presents a list of user commands or options, such as a
|
||||||
|
menu, a prominent item in the list meets this criterion.
|
||||||
|
|
||||||
|
1. Source Code.
|
||||||
|
|
||||||
|
The "source code" for a work means the preferred form of the work
|
||||||
|
for making modifications to it. "Object code" means any non-source
|
||||||
|
form of a work.
|
||||||
|
|
||||||
|
A "Standard Interface" means an interface that either is an official
|
||||||
|
standard defined by a recognized standards body, or, in the case of
|
||||||
|
interfaces specified for a particular programming language, one that
|
||||||
|
is widely used among developers working in that language.
|
||||||
|
|
||||||
|
The "System Libraries" of an executable work include anything, other
|
||||||
|
than the work as a whole, that (a) is included in the normal form of
|
||||||
|
packaging a Major Component, but which is not part of that Major
|
||||||
|
Component, and (b) serves only to enable use of the work with that
|
||||||
|
Major Component, or to implement a Standard Interface for which an
|
||||||
|
implementation is available to the public in source code form. A
|
||||||
|
"Major Component", in this context, means a major essential component
|
||||||
|
(kernel, window system, and so on) of the specific operating system
|
||||||
|
(if any) on which the executable work runs, or a compiler used to
|
||||||
|
produce the work, or an object code interpreter used to run it.
|
||||||
|
|
||||||
|
The "Corresponding Source" for a work in object code form means all
|
||||||
|
the source code needed to generate, install, and (for an executable
|
||||||
|
work) run the object code and to modify the work, including scripts to
|
||||||
|
control those activities. However, it does not include the work's
|
||||||
|
System Libraries, or general-purpose tools or generally available free
|
||||||
|
programs which are used unmodified in performing those activities but
|
||||||
|
which are not part of the work. For example, Corresponding Source
|
||||||
|
includes interface definition files associated with source files for
|
||||||
|
the work, and the source code for shared libraries and dynamically
|
||||||
|
linked subprograms that the work is specifically designed to require,
|
||||||
|
such as by intimate data communication or control flow between those
|
||||||
|
subprograms and other parts of the work.
|
||||||
|
|
||||||
|
The Corresponding Source need not include anything that users
|
||||||
|
can regenerate automatically from other parts of the Corresponding
|
||||||
|
Source.
|
||||||
|
|
||||||
|
The Corresponding Source for a work in source code form is that
|
||||||
|
same work.
|
||||||
|
|
||||||
|
2. Basic Permissions.
|
||||||
|
|
||||||
|
All rights granted under this License are granted for the term of
|
||||||
|
copyright on the Program, and are irrevocable provided the stated
|
||||||
|
conditions are met. This License explicitly affirms your unlimited
|
||||||
|
permission to run the unmodified Program. The output from running a
|
||||||
|
covered work is covered by this License only if the output, given its
|
||||||
|
content, constitutes a covered work. This License acknowledges your
|
||||||
|
rights of fair use or other equivalent, as provided by copyright law.
|
||||||
|
|
||||||
|
You may make, run and propagate covered works that you do not
|
||||||
|
convey, without conditions so long as your license otherwise remains
|
||||||
|
in force. You may convey covered works to others for the sole purpose
|
||||||
|
of having them make modifications exclusively for you, or provide you
|
||||||
|
with facilities for running those works, provided that you comply with
|
||||||
|
the terms of this License in conveying all material for which you do
|
||||||
|
not control copyright. Those thus making or running the covered works
|
||||||
|
for you must do so exclusively on your behalf, under your direction
|
||||||
|
and control, on terms that prohibit them from making any copies of
|
||||||
|
your copyrighted material outside their relationship with you.
|
||||||
|
|
||||||
|
Conveying under any other circumstances is permitted solely under
|
||||||
|
the conditions stated below. Sublicensing is not allowed; section 10
|
||||||
|
makes it unnecessary.
|
||||||
|
|
||||||
|
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||||
|
|
||||||
|
No covered work shall be deemed part of an effective technological
|
||||||
|
measure under any applicable law fulfilling obligations under article
|
||||||
|
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||||
|
similar laws prohibiting or restricting circumvention of such
|
||||||
|
measures.
|
||||||
|
|
||||||
|
When you convey a covered work, you waive any legal power to forbid
|
||||||
|
circumvention of technological measures to the extent such circumvention
|
||||||
|
is effected by exercising rights under this License with respect to
|
||||||
|
the covered work, and you disclaim any intention to limit operation or
|
||||||
|
modification of the work as a means of enforcing, against the work's
|
||||||
|
users, your or third parties' legal rights to forbid circumvention of
|
||||||
|
technological measures.
|
||||||
|
|
||||||
|
4. Conveying Verbatim Copies.
|
||||||
|
|
||||||
|
You may convey verbatim copies of the Program's source code as you
|
||||||
|
receive it, in any medium, provided that you conspicuously and
|
||||||
|
appropriately publish on each copy an appropriate copyright notice;
|
||||||
|
keep intact all notices stating that this License and any
|
||||||
|
non-permissive terms added in accord with section 7 apply to the code;
|
||||||
|
keep intact all notices of the absence of any warranty; and give all
|
||||||
|
recipients a copy of this License along with the Program.
|
||||||
|
|
||||||
|
You may charge any price or no price for each copy that you convey,
|
||||||
|
and you may offer support or warranty protection for a fee.
|
||||||
|
|
||||||
|
5. Conveying Modified Source Versions.
|
||||||
|
|
||||||
|
You may convey a work based on the Program, or the modifications to
|
||||||
|
produce it from the Program, in the form of source code under the
|
||||||
|
terms of section 4, provided that you also meet all of these conditions:
|
||||||
|
|
||||||
|
a) The work must carry prominent notices stating that you modified
|
||||||
|
it, and giving a relevant date.
|
||||||
|
|
||||||
|
b) The work must carry prominent notices stating that it is
|
||||||
|
released under this License and any conditions added under section
|
||||||
|
7. This requirement modifies the requirement in section 4 to
|
||||||
|
"keep intact all notices".
|
||||||
|
|
||||||
|
c) You must license the entire work, as a whole, under this
|
||||||
|
License to anyone who comes into possession of a copy. This
|
||||||
|
License will therefore apply, along with any applicable section 7
|
||||||
|
additional terms, to the whole of the work, and all its parts,
|
||||||
|
regardless of how they are packaged. This License gives no
|
||||||
|
permission to license the work in any other way, but it does not
|
||||||
|
invalidate such permission if you have separately received it.
|
||||||
|
|
||||||
|
d) If the work has interactive user interfaces, each must display
|
||||||
|
Appropriate Legal Notices; however, if the Program has interactive
|
||||||
|
interfaces that do not display Appropriate Legal Notices, your
|
||||||
|
work need not make them do so.
|
||||||
|
|
||||||
|
A compilation of a covered work with other separate and independent
|
||||||
|
works, which are not by their nature extensions of the covered work,
|
||||||
|
and which are not combined with it such as to form a larger program,
|
||||||
|
in or on a volume of a storage or distribution medium, is called an
|
||||||
|
"aggregate" if the compilation and its resulting copyright are not
|
||||||
|
used to limit the access or legal rights of the compilation's users
|
||||||
|
beyond what the individual works permit. Inclusion of a covered work
|
||||||
|
in an aggregate does not cause this License to apply to the other
|
||||||
|
parts of the aggregate.
|
||||||
|
|
||||||
|
6. Conveying Non-Source Forms.
|
||||||
|
|
||||||
|
You may convey a covered work in object code form under the terms
|
||||||
|
of sections 4 and 5, provided that you also convey the
|
||||||
|
machine-readable Corresponding Source under the terms of this License,
|
||||||
|
in one of these ways:
|
||||||
|
|
||||||
|
a) Convey the object code in, or embodied in, a physical product
|
||||||
|
(including a physical distribution medium), accompanied by the
|
||||||
|
Corresponding Source fixed on a durable physical medium
|
||||||
|
customarily used for software interchange.
|
||||||
|
|
||||||
|
b) Convey the object code in, or embodied in, a physical product
|
||||||
|
(including a physical distribution medium), accompanied by a
|
||||||
|
written offer, valid for at least three years and valid for as
|
||||||
|
long as you offer spare parts or customer support for that product
|
||||||
|
model, to give anyone who possesses the object code either (1) a
|
||||||
|
copy of the Corresponding Source for all the software in the
|
||||||
|
product that is covered by this License, on a durable physical
|
||||||
|
medium customarily used for software interchange, for a price no
|
||||||
|
more than your reasonable cost of physically performing this
|
||||||
|
conveying of source, or (2) access to copy the
|
||||||
|
Corresponding Source from a network server at no charge.
|
||||||
|
|
||||||
|
c) Convey individual copies of the object code with a copy of the
|
||||||
|
written offer to provide the Corresponding Source. This
|
||||||
|
alternative is allowed only occasionally and noncommercially, and
|
||||||
|
only if you received the object code with such an offer, in accord
|
||||||
|
with subsection 6b.
|
||||||
|
|
||||||
|
d) Convey the object code by offering access from a designated
|
||||||
|
place (gratis or for a charge), and offer equivalent access to the
|
||||||
|
Corresponding Source in the same way through the same place at no
|
||||||
|
further charge. You need not require recipients to copy the
|
||||||
|
Corresponding Source along with the object code. If the place to
|
||||||
|
copy the object code is a network server, the Corresponding Source
|
||||||
|
may be on a different server (operated by you or a third party)
|
||||||
|
that supports equivalent copying facilities, provided you maintain
|
||||||
|
clear directions next to the object code saying where to find the
|
||||||
|
Corresponding Source. Regardless of what server hosts the
|
||||||
|
Corresponding Source, you remain obligated to ensure that it is
|
||||||
|
available for as long as needed to satisfy these requirements.
|
||||||
|
|
||||||
|
e) Convey the object code using peer-to-peer transmission, provided
|
||||||
|
you inform other peers where the object code and Corresponding
|
||||||
|
Source of the work are being offered to the general public at no
|
||||||
|
charge under subsection 6d.
|
||||||
|
|
||||||
|
A separable portion of the object code, whose source code is excluded
|
||||||
|
from the Corresponding Source as a System Library, need not be
|
||||||
|
included in conveying the object code work.
|
||||||
|
|
||||||
|
A "User Product" is either (1) a "consumer product", which means any
|
||||||
|
tangible personal property which is normally used for personal, family,
|
||||||
|
or household purposes, or (2) anything designed or sold for incorporation
|
||||||
|
into a dwelling. In determining whether a product is a consumer product,
|
||||||
|
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||||
|
product received by a particular user, "normally used" refers to a
|
||||||
|
typical or common use of that class of product, regardless of the status
|
||||||
|
of the particular user or of the way in which the particular user
|
||||||
|
actually uses, or expects or is expected to use, the product. A product
|
||||||
|
is a consumer product regardless of whether the product has substantial
|
||||||
|
commercial, industrial or non-consumer uses, unless such uses represent
|
||||||
|
the only significant mode of use of the product.
|
||||||
|
|
||||||
|
"Installation Information" for a User Product means any methods,
|
||||||
|
procedures, authorization keys, or other information required to install
|
||||||
|
and execute modified versions of a covered work in that User Product from
|
||||||
|
a modified version of its Corresponding Source. The information must
|
||||||
|
suffice to ensure that the continued functioning of the modified object
|
||||||
|
code is in no case prevented or interfered with solely because
|
||||||
|
modification has been made.
|
||||||
|
|
||||||
|
If you convey an object code work under this section in, or with, or
|
||||||
|
specifically for use in, a User Product, and the conveying occurs as
|
||||||
|
part of a transaction in which the right of possession and use of the
|
||||||
|
User Product is transferred to the recipient in perpetuity or for a
|
||||||
|
fixed term (regardless of how the transaction is characterized), the
|
||||||
|
Corresponding Source conveyed under this section must be accompanied
|
||||||
|
by the Installation Information. But this requirement does not apply
|
||||||
|
if neither you nor any third party retains the ability to install
|
||||||
|
modified object code on the User Product (for example, the work has
|
||||||
|
been installed in ROM).
|
||||||
|
|
||||||
|
The requirement to provide Installation Information does not include a
|
||||||
|
requirement to continue to provide support service, warranty, or updates
|
||||||
|
for a work that has been modified or installed by the recipient, or for
|
||||||
|
the User Product in which it has been modified or installed. Access to a
|
||||||
|
network may be denied when the modification itself materially and
|
||||||
|
adversely affects the operation of the network or violates the rules and
|
||||||
|
protocols for communication across the network.
|
||||||
|
|
||||||
|
Corresponding Source conveyed, and Installation Information provided,
|
||||||
|
in accord with this section must be in a format that is publicly
|
||||||
|
documented (and with an implementation available to the public in
|
||||||
|
source code form), and must require no special password or key for
|
||||||
|
unpacking, reading or copying.
|
||||||
|
|
||||||
|
7. Additional Terms.
|
||||||
|
|
||||||
|
"Additional permissions" are terms that supplement the terms of this
|
||||||
|
License by making exceptions from one or more of its conditions.
|
||||||
|
Additional permissions that are applicable to the entire Program shall
|
||||||
|
be treated as though they were included in this License, to the extent
|
||||||
|
that they are valid under applicable law. If additional permissions
|
||||||
|
apply only to part of the Program, that part may be used separately
|
||||||
|
under those permissions, but the entire Program remains governed by
|
||||||
|
this License without regard to the additional permissions.
|
||||||
|
|
||||||
|
When you convey a copy of a covered work, you may at your option
|
||||||
|
remove any additional permissions from that copy, or from any part of
|
||||||
|
it. (Additional permissions may be written to require their own
|
||||||
|
removal in certain cases when you modify the work.) You may place
|
||||||
|
additional permissions on material, added by you to a covered work,
|
||||||
|
for which you have or can give appropriate copyright permission.
|
||||||
|
|
||||||
|
Notwithstanding any other provision of this License, for material you
|
||||||
|
add to a covered work, you may (if authorized by the copyright holders of
|
||||||
|
that material) supplement the terms of this License with terms:
|
||||||
|
|
||||||
|
a) Disclaiming warranty or limiting liability differently from the
|
||||||
|
terms of sections 15 and 16 of this License; or
|
||||||
|
|
||||||
|
b) Requiring preservation of specified reasonable legal notices or
|
||||||
|
author attributions in that material or in the Appropriate Legal
|
||||||
|
Notices displayed by works containing it; or
|
||||||
|
|
||||||
|
c) Prohibiting misrepresentation of the origin of that material, or
|
||||||
|
requiring that modified versions of such material be marked in
|
||||||
|
reasonable ways as different from the original version; or
|
||||||
|
|
||||||
|
d) Limiting the use for publicity purposes of names of licensors or
|
||||||
|
authors of the material; or
|
||||||
|
|
||||||
|
e) Declining to grant rights under trademark law for use of some
|
||||||
|
trade names, trademarks, or service marks; or
|
||||||
|
|
||||||
|
f) Requiring indemnification of licensors and authors of that
|
||||||
|
material by anyone who conveys the material (or modified versions of
|
||||||
|
it) with contractual assumptions of liability to the recipient, for
|
||||||
|
any liability that these contractual assumptions directly impose on
|
||||||
|
those licensors and authors.
|
||||||
|
|
||||||
|
All other non-permissive additional terms are considered "further
|
||||||
|
restrictions" within the meaning of section 10. If the Program as you
|
||||||
|
received it, or any part of it, contains a notice stating that it is
|
||||||
|
governed by this License along with a term that is a further
|
||||||
|
restriction, you may remove that term. If a license document contains
|
||||||
|
a further restriction but permits relicensing or conveying under this
|
||||||
|
License, you may add to a covered work material governed by the terms
|
||||||
|
of that license document, provided that the further restriction does
|
||||||
|
not survive such relicensing or conveying.
|
||||||
|
|
||||||
|
If you add terms to a covered work in accord with this section, you
|
||||||
|
must place, in the relevant source files, a statement of the
|
||||||
|
additional terms that apply to those files, or a notice indicating
|
||||||
|
where to find the applicable terms.
|
||||||
|
|
||||||
|
Additional terms, permissive or non-permissive, may be stated in the
|
||||||
|
form of a separately written license, or stated as exceptions;
|
||||||
|
the above requirements apply either way.
|
||||||
|
|
||||||
|
8. Termination.
|
||||||
|
|
||||||
|
You may not propagate or modify a covered work except as expressly
|
||||||
|
provided under this License. Any attempt otherwise to propagate or
|
||||||
|
modify it is void, and will automatically terminate your rights under
|
||||||
|
this License (including any patent licenses granted under the third
|
||||||
|
paragraph of section 11).
|
||||||
|
|
||||||
|
However, if you cease all violation of this License, then your
|
||||||
|
license from a particular copyright holder is reinstated (a)
|
||||||
|
provisionally, unless and until the copyright holder explicitly and
|
||||||
|
finally terminates your license, and (b) permanently, if the copyright
|
||||||
|
holder fails to notify you of the violation by some reasonable means
|
||||||
|
prior to 60 days after the cessation.
|
||||||
|
|
||||||
|
Moreover, your license from a particular copyright holder is
|
||||||
|
reinstated permanently if the copyright holder notifies you of the
|
||||||
|
violation by some reasonable means, this is the first time you have
|
||||||
|
received notice of violation of this License (for any work) from that
|
||||||
|
copyright holder, and you cure the violation prior to 30 days after
|
||||||
|
your receipt of the notice.
|
||||||
|
|
||||||
|
Termination of your rights under this section does not terminate the
|
||||||
|
licenses of parties who have received copies or rights from you under
|
||||||
|
this License. If your rights have been terminated and not permanently
|
||||||
|
reinstated, you do not qualify to receive new licenses for the same
|
||||||
|
material under section 10.
|
||||||
|
|
||||||
|
9. Acceptance Not Required for Having Copies.
|
||||||
|
|
||||||
|
You are not required to accept this License in order to receive or
|
||||||
|
run a copy of the Program. Ancillary propagation of a covered work
|
||||||
|
occurring solely as a consequence of using peer-to-peer transmission
|
||||||
|
to receive a copy likewise does not require acceptance. However,
|
||||||
|
nothing other than this License grants you permission to propagate or
|
||||||
|
modify any covered work. These actions infringe copyright if you do
|
||||||
|
not accept this License. Therefore, by modifying or propagating a
|
||||||
|
covered work, you indicate your acceptance of this License to do so.
|
||||||
|
|
||||||
|
10. Automatic Licensing of Downstream Recipients.
|
||||||
|
|
||||||
|
Each time you convey a covered work, the recipient automatically
|
||||||
|
receives a license from the original licensors, to run, modify and
|
||||||
|
propagate that work, subject to this License. You are not responsible
|
||||||
|
for enforcing compliance by third parties with this License.
|
||||||
|
|
||||||
|
An "entity transaction" is a transaction transferring control of an
|
||||||
|
organization, or substantially all assets of one, or subdividing an
|
||||||
|
organization, or merging organizations. If propagation of a covered
|
||||||
|
work results from an entity transaction, each party to that
|
||||||
|
transaction who receives a copy of the work also receives whatever
|
||||||
|
licenses to the work the party's predecessor in interest had or could
|
||||||
|
give under the previous paragraph, plus a right to possession of the
|
||||||
|
Corresponding Source of the work from the predecessor in interest, if
|
||||||
|
the predecessor has it or can get it with reasonable efforts.
|
||||||
|
|
||||||
|
You may not impose any further restrictions on the exercise of the
|
||||||
|
rights granted or affirmed under this License. For example, you may
|
||||||
|
not impose a license fee, royalty, or other charge for exercise of
|
||||||
|
rights granted under this License, and you may not initiate litigation
|
||||||
|
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||||
|
any patent claim is infringed by making, using, selling, offering for
|
||||||
|
sale, or importing the Program or any portion of it.
|
||||||
|
|
||||||
|
11. Patents.
|
||||||
|
|
||||||
|
A "contributor" is a copyright holder who authorizes use under this
|
||||||
|
License of the Program or a work on which the Program is based. The
|
||||||
|
work thus licensed is called the contributor's "contributor version".
|
||||||
|
|
||||||
|
A contributor's "essential patent claims" are all patent claims
|
||||||
|
owned or controlled by the contributor, whether already acquired or
|
||||||
|
hereafter acquired, that would be infringed by some manner, permitted
|
||||||
|
by this License, of making, using, or selling its contributor version,
|
||||||
|
but do not include claims that would be infringed only as a
|
||||||
|
consequence of further modification of the contributor version. For
|
||||||
|
purposes of this definition, "control" includes the right to grant
|
||||||
|
patent sublicenses in a manner consistent with the requirements of
|
||||||
|
this License.
|
||||||
|
|
||||||
|
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||||
|
patent license under the contributor's essential patent claims, to
|
||||||
|
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||||
|
propagate the contents of its contributor version.
|
||||||
|
|
||||||
|
In the following three paragraphs, a "patent license" is any express
|
||||||
|
agreement or commitment, however denominated, not to enforce a patent
|
||||||
|
(such as an express permission to practice a patent or covenant not to
|
||||||
|
sue for patent infringement). To "grant" such a patent license to a
|
||||||
|
party means to make such an agreement or commitment not to enforce a
|
||||||
|
patent against the party.
|
||||||
|
|
||||||
|
If you convey a covered work, knowingly relying on a patent license,
|
||||||
|
and the Corresponding Source of the work is not available for anyone
|
||||||
|
to copy, free of charge and under the terms of this License, through a
|
||||||
|
publicly available network server or other readily accessible means,
|
||||||
|
then you must either (1) cause the Corresponding Source to be so
|
||||||
|
available, or (2) arrange to deprive yourself of the benefit of the
|
||||||
|
patent license for this particular work, or (3) arrange, in a manner
|
||||||
|
consistent with the requirements of this License, to extend the patent
|
||||||
|
license to downstream recipients. "Knowingly relying" means you have
|
||||||
|
actual knowledge that, but for the patent license, your conveying the
|
||||||
|
covered work in a country, or your recipient's use of the covered work
|
||||||
|
in a country, would infringe one or more identifiable patents in that
|
||||||
|
country that you have reason to believe are valid.
|
||||||
|
|
||||||
|
If, pursuant to or in connection with a single transaction or
|
||||||
|
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||||
|
covered work, and grant a patent license to some of the parties
|
||||||
|
receiving the covered work authorizing them to use, propagate, modify
|
||||||
|
or convey a specific copy of the covered work, then the patent license
|
||||||
|
you grant is automatically extended to all recipients of the covered
|
||||||
|
work and works based on it.
|
||||||
|
|
||||||
|
A patent license is "discriminatory" if it does not include within
|
||||||
|
the scope of its coverage, prohibits the exercise of, or is
|
||||||
|
conditioned on the non-exercise of one or more of the rights that are
|
||||||
|
specifically granted under this License. You may not convey a covered
|
||||||
|
work if you are a party to an arrangement with a third party that is
|
||||||
|
in the business of distributing software, under which you make payment
|
||||||
|
to the third party based on the extent of your activity of conveying
|
||||||
|
the work, and under which the third party grants, to any of the
|
||||||
|
parties who would receive the covered work from you, a discriminatory
|
||||||
|
patent license (a) in connection with copies of the covered work
|
||||||
|
conveyed by you (or copies made from those copies), or (b) primarily
|
||||||
|
for and in connection with specific products or compilations that
|
||||||
|
contain the covered work, unless you entered into that arrangement,
|
||||||
|
or that patent license was granted, prior to 28 March 2007.
|
||||||
|
|
||||||
|
Nothing in this License shall be construed as excluding or limiting
|
||||||
|
any implied license or other defenses to infringement that may
|
||||||
|
otherwise be available to you under applicable patent law.
|
||||||
|
|
||||||
|
12. No Surrender of Others' Freedom.
|
||||||
|
|
||||||
|
If conditions are imposed on you (whether by court order, agreement or
|
||||||
|
otherwise) that contradict the conditions of this License, they do not
|
||||||
|
excuse you from the conditions of this License. If you cannot convey a
|
||||||
|
covered work so as to satisfy simultaneously your obligations under this
|
||||||
|
License and any other pertinent obligations, then as a consequence you may
|
||||||
|
not convey it at all. For example, if you agree to terms that obligate you
|
||||||
|
to collect a royalty for further conveying from those to whom you convey
|
||||||
|
the Program, the only way you could satisfy both those terms and this
|
||||||
|
License would be to refrain entirely from conveying the Program.
|
||||||
|
|
||||||
|
13. Remote Network Interaction; Use with the GNU General Public License.
|
||||||
|
|
||||||
|
Notwithstanding any other provision of this License, if you modify the
|
||||||
|
Program, your modified version must prominently offer all users
|
||||||
|
interacting with it remotely through a computer network (if your version
|
||||||
|
supports such interaction) an opportunity to receive the Corresponding
|
||||||
|
Source of your version by providing access to the Corresponding Source
|
||||||
|
from a network server at no charge, through some standard or customary
|
||||||
|
means of facilitating copying of software. This Corresponding Source
|
||||||
|
shall include the Corresponding Source for any work covered by version 3
|
||||||
|
of the GNU General Public License that is incorporated pursuant to the
|
||||||
|
following paragraph.
|
||||||
|
|
||||||
|
Notwithstanding any other provision of this License, you have
|
||||||
|
permission to link or combine any covered work with a work licensed
|
||||||
|
under version 3 of the GNU General Public License into a single
|
||||||
|
combined work, and to convey the resulting work. The terms of this
|
||||||
|
License will continue to apply to the part which is the covered work,
|
||||||
|
but the work with which it is combined will remain governed by version
|
||||||
|
3 of the GNU General Public License.
|
||||||
|
|
||||||
|
14. Revised Versions of this License.
|
||||||
|
|
||||||
|
The Free Software Foundation may publish revised and/or new versions of
|
||||||
|
the GNU Affero General Public License from time to time. Such new versions
|
||||||
|
will be similar in spirit to the present version, but may differ in detail to
|
||||||
|
address new problems or concerns.
|
||||||
|
|
||||||
|
Each version is given a distinguishing version number. If the
|
||||||
|
Program specifies that a certain numbered version of the GNU Affero General
|
||||||
|
Public License "or any later version" applies to it, you have the
|
||||||
|
option of following the terms and conditions either of that numbered
|
||||||
|
version or of any later version published by the Free Software
|
||||||
|
Foundation. If the Program does not specify a version number of the
|
||||||
|
GNU Affero General Public License, you may choose any version ever published
|
||||||
|
by the Free Software Foundation.
|
||||||
|
|
||||||
|
If the Program specifies that a proxy can decide which future
|
||||||
|
versions of the GNU Affero General Public License can be used, that proxy's
|
||||||
|
public statement of acceptance of a version permanently authorizes you
|
||||||
|
to choose that version for the Program.
|
||||||
|
|
||||||
|
Later license versions may give you additional or different
|
||||||
|
permissions. However, no additional obligations are imposed on any
|
||||||
|
author or copyright holder as a result of your choosing to follow a
|
||||||
|
later version.
|
||||||
|
|
||||||
|
15. Disclaimer of Warranty.
|
||||||
|
|
||||||
|
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||||
|
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||||
|
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||||
|
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||||
|
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||||
|
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||||
|
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||||
|
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||||
|
|
||||||
|
16. Limitation of Liability.
|
||||||
|
|
||||||
|
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||||
|
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||||
|
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||||
|
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||||
|
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||||
|
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||||
|
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||||
|
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||||
|
SUCH DAMAGES.
|
||||||
|
|
||||||
|
17. Interpretation of Sections 15 and 16.
|
||||||
|
|
||||||
|
If the disclaimer of warranty and limitation of liability provided
|
||||||
|
above cannot be given local legal effect according to their terms,
|
||||||
|
reviewing courts shall apply local law that most closely approximates
|
||||||
|
an absolute waiver of all civil liability in connection with the
|
||||||
|
Program, unless a warranty or assumption of liability accompanies a
|
||||||
|
copy of the Program in return for a fee.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
How to Apply These Terms to Your New Programs
|
||||||
|
|
||||||
|
If you develop a new program, and you want it to be of the greatest
|
||||||
|
possible use to the public, the best way to achieve this is to make it
|
||||||
|
free software which everyone can redistribute and change under these terms.
|
||||||
|
|
||||||
|
To do so, attach the following notices to the program. It is safest
|
||||||
|
to attach them to the start of each source file to most effectively
|
||||||
|
state the exclusion of warranty; and each file should have at least
|
||||||
|
the "copyright" line and a pointer to where the full notice is found.
|
||||||
|
|
||||||
|
<one line to give the program's name and a brief idea of what it does.>
|
||||||
|
Copyright (C) <year> <name of author>
|
||||||
|
|
||||||
|
This program is free software: you can redistribute it and/or modify
|
||||||
|
it under the terms of the GNU Affero General Public License as published
|
||||||
|
by the Free Software Foundation, either version 3 of the License, or
|
||||||
|
(at your option) any later version.
|
||||||
|
|
||||||
|
This program is distributed in the hope that it will be useful,
|
||||||
|
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||||
|
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||||
|
GNU Affero General Public License for more details.
|
||||||
|
|
||||||
|
You should have received a copy of the GNU Affero General Public License
|
||||||
|
along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||||
|
|
||||||
|
Also add information on how to contact you by electronic and paper mail.
|
||||||
|
|
||||||
|
If your software can interact with users remotely through a computer
|
||||||
|
network, you should also make sure that it provides a way for users to
|
||||||
|
get its source. For example, if your program is a web application, its
|
||||||
|
interface could display a "Source" link that leads users to an archive
|
||||||
|
of the code. There are many ways you could offer source, and different
|
||||||
|
solutions will be better for different programs; see section 13 for the
|
||||||
|
specific requirements.
|
||||||
|
|
||||||
|
You should also get your employer (if you work as a programmer) or school,
|
||||||
|
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||||
|
For more information on this, and how to apply and follow the GNU AGPL, see
|
||||||
|
<http://www.gnu.org/licenses/>.
|
||||||
212
README.md
212
README.md
@ -3,7 +3,7 @@
|
|||||||
2022年7月18日开始开发的项目,使用彩色相机进行烟梗颜色的识别。
|
2022年7月18日开始开发的项目,使用彩色相机进行烟梗颜色的识别。
|
||||||
|
|
||||||
## 如何进行模型训练和部署?
|
## 如何进行模型训练和部署?
|
||||||
1. 项目当中需要包含`data`和`models`这两个文件夹,请下载到当前文件夹下,这是链接:[data](https://macrosolid-my.sharepoint.com/personal/feijinti_miaow_fun/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Ffeijinti%5Fmiaow%5Ffun%2FDocuments%2FPycharmProjects%2Ftobacco%5Fcolor%2Fdata&ga=1), [models](https://macrosolid-my.sharepoint.com/:f:/g/personal/feijinti_miaow_fun/EiyBjWEX90JGn8S-e5Kh7N8B1GWvfvDcNbpleWDTwkDm1w?e=wyL4EF)
|
1. 项目需要包含`data`和`weights`这两个文件夹,请从[release](https://github.com/NanjingForestryUniversity/supermachine-tobacco/releases)中下载到当前文件夹下,对于训练过的所有可用模型和部署的已加密程序,已归档到[这里](https://macrosolid-my.sharepoint.com/:f:/g/personal/lab_miaow_fun/Es4_iGy0mtBKktn_a0-5W40BRxzb6SeGxKY_wAVJMlGBrQ?e=px1Tfn)
|
||||||
2. 使用[01_dataset.ipynb](./01_dataset.ipynb) 进行数据集的分析文件格式需要设置为这种形式:
|
2. 使用[01_dataset.ipynb](./01_dataset.ipynb) 进行数据集的分析文件格式需要设置为这种形式:
|
||||||
```text
|
```text
|
||||||
dataset
|
dataset
|
||||||
@ -125,3 +125,213 @@
|
|||||||
| 识别结果 |  |
|
| 识别结果 |  |
|
||||||
| 模型约束情况 | 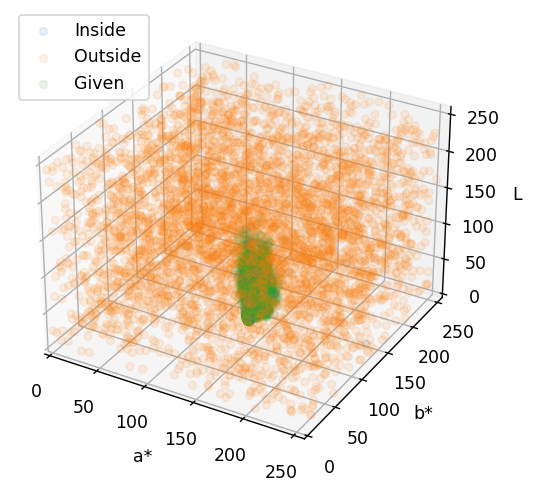 |
|
| 模型约束情况 |  |
|
||||||
|
|
||||||
|
## 图像的对齐
|
||||||
|
|
||||||
|
引入了RGB和光谱图像的原因,这里牵扯到图像对齐的问题。
|
||||||
|
|
||||||
|
### 对齐检测算法
|
||||||
|
|
||||||
|
理论大概是这样,但是这不重要啦,简单来说就是偏差平面里头计算响应强度,这是当时的草稿。
|
||||||
|
|
||||||
|
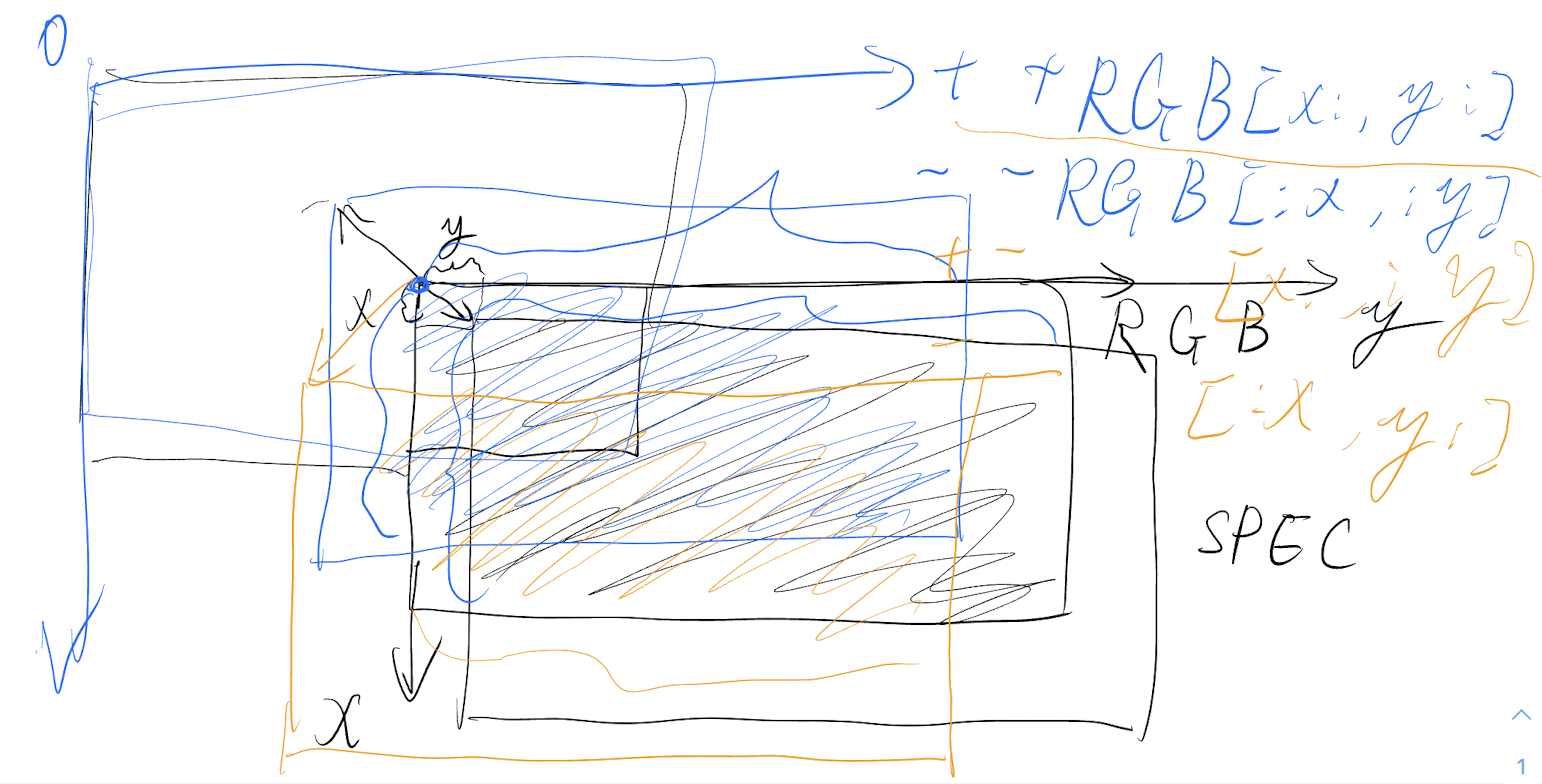
|
||||||
|
|
||||||
|
实现以后这里可以看到对齐的结果,算法实现在`main_test.py`里头的`calculate_delta()`:
|
||||||
|
|
||||||
|
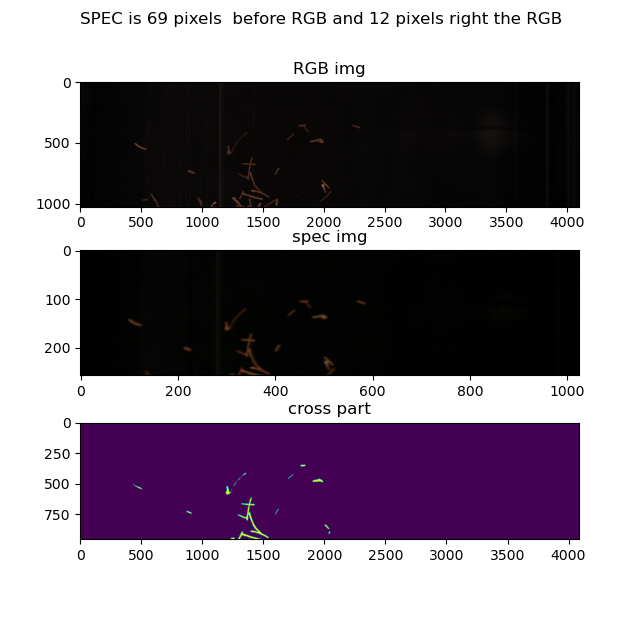
|
||||||
|
|
||||||
|
根据这张图片的换算结果可以得知光谱图像比RGB图像超前了69个像素,大概2.02厘米的样子。
|
||||||
|
|
||||||
|
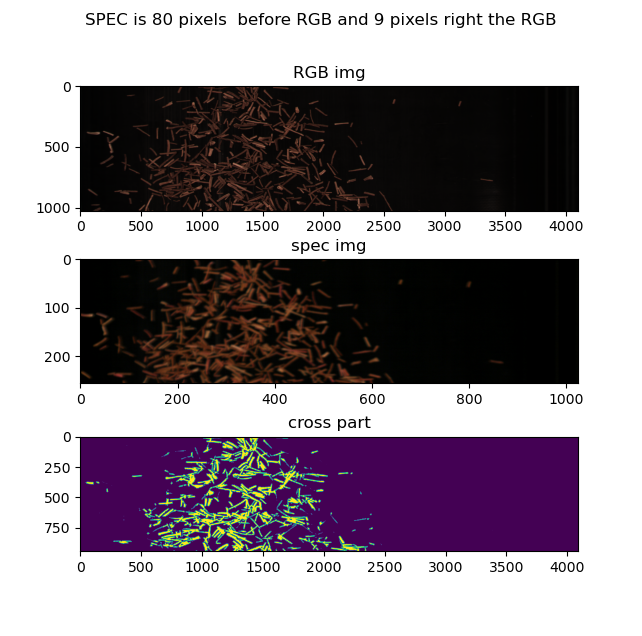
|
||||||
|
|
||||||
|
根据这张图片,可以得知,图像上下偏差是2.3厘米
|
||||||
|
|
||||||
|
|
||||||
|
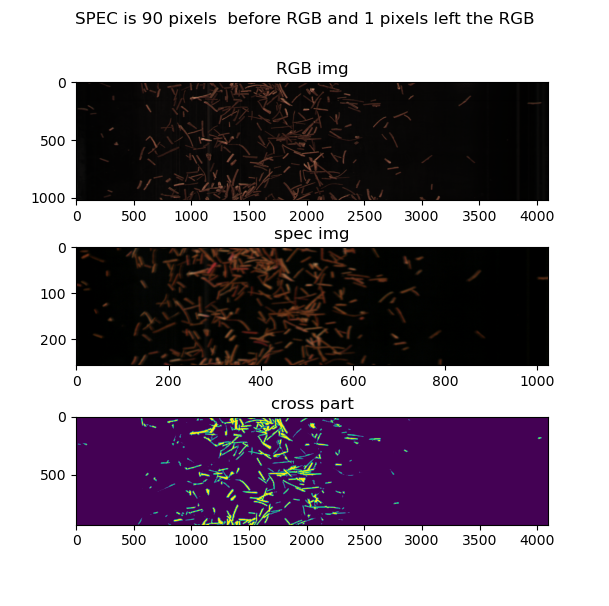
|
||||||
|
|
||||||
|
这张图片里的上下偏差则达到了2.6厘米左右。
|
||||||
|
|
||||||
|
### 图像拍摄脉冲触发问题
|
||||||
|
|
||||||
|
2022年7月30日我们进行了二次实验,本来以为会得到一个恒定的偏差结果,但是,情况并不像我们想的那样:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
从这张图可以看到,两张图的偏差大概是上下10像素,RGB偏上,左右偏差19像素,RGB偏左,
|
||||||
|
|
||||||
|
但是!RGB图像明显是扭曲的,这显然是由于触发导致的。
|
||||||
|
|
||||||
|
从其他图片来看:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
明显也存在图像扭曲的情况,偏差情况是:
|
||||||
|
|
||||||
|
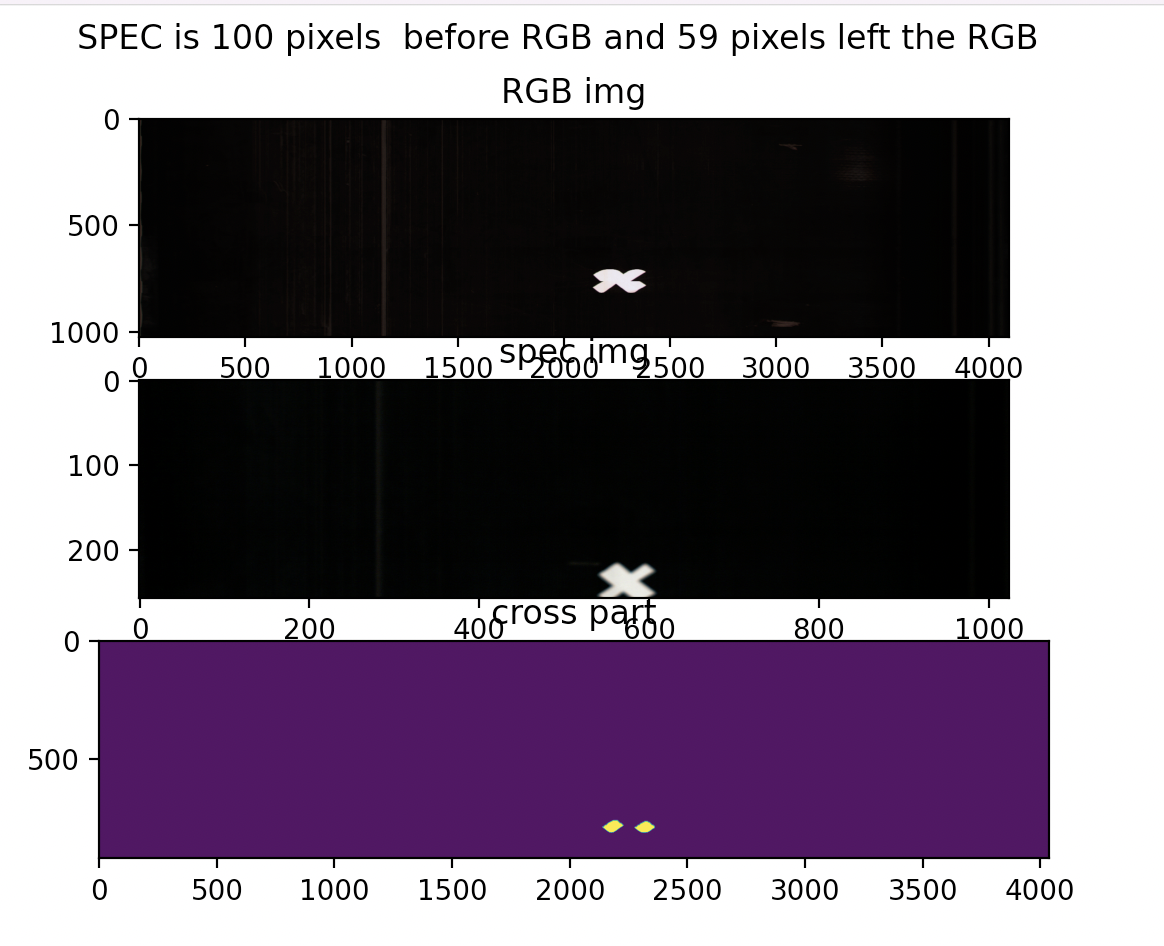这张图上下已经对不上了,用它计算的偏差不具备参考价值。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
偏差的影响,也可从这幅图当中看到,这幅图的上下偏差达到了惊人的200像素,明显考虑是触发有问题了,不然偏差值至少是恒定的。
|
||||||
|
|
||||||
|
结论是考虑RGB相机的触发存在一定问题。
|
||||||
|
|
||||||
|
# 喷阀检查相关
|
||||||
|
|
||||||
|
## 喷阀检验脚本
|
||||||
|
|
||||||
|
为了能够有效的对喷阀进行检查,我写了一个用于测试的小socket,这个小socket的使用方式是这样的:
|
||||||
|
|
||||||
|
开启服务端:
|
||||||
|
|
||||||
|
```shel
|
||||||
|
python valve_test.py
|
||||||
|
```
|
||||||
|
|
||||||
|
然后按照要求进行输入就可以了,我还在里头藏了个彩蛋,你猜猜是啥。
|
||||||
|
|
||||||
|
如果想要开客户端,可以加个参数,就像这样:
|
||||||
|
|
||||||
|
```shel
|
||||||
|
python valve_test.py -c
|
||||||
|
```
|
||||||
|
|
||||||
|
这个客户端啥也不会干,只会做去显示相应的收到的指令。
|
||||||
|
|
||||||
|
同时运行这两个可以在本地看到测试结果,不用看zynq那边的结果:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 仅使用RGB或SPEC预测以调节延时
|
||||||
|
|
||||||
|
只使用RGB或者SPEC预测时,使用如下代码:
|
||||||
|
|
||||||
|
只使用rgb:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python main.py -oc
|
||||||
|
```
|
||||||
|
|
||||||
|
只使用SPEC
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python main.py -os
|
||||||
|
```
|
||||||
|
|
||||||
|
## 同时开启喷阀数量限制
|
||||||
|
|
||||||
|
由于喷阀的电源有限,所以必须对同时开启的喷阀数量加以限制,否则会造成流在导线上的电流过大,就像是在烧水。
|
||||||
|
|
||||||
|
最大允许开启的喷阀数量$n$和电源功率$p$之间的关系如下:
|
||||||
|
$$
|
||||||
|
n = \frac{p}{12}
|
||||||
|
$$
|
||||||
|
这里$12 V \cdot A$是对应喷阀的电压和电流的乘积,建议在这个基础之上再进行数量除以$2$的操作,因为我们不可合并rgb和spec两个mask,所以如果当出现杂质时,仅对一个mask的最大值进行限定存在风险。
|
||||||
|
|
||||||
|
# 代码加密
|
||||||
|
|
||||||
|
本来想使用pyarmor,但是它在加密过程中一直重复不停的进行下载,这太麻烦了,而且还要考虑到兼容性问题,所以果断放弃,后来发现简单的方案是这样的,把python编译成字节码就行:
|
||||||
|
|
||||||
|
## 简单方案
|
||||||
|
|
||||||
|
这方案的好处在于不需要联网,但是破解成本比较低。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m compileall -f -q -b "tobacco_color"
|
||||||
|
```
|
||||||
|
|
||||||
|
然后接下来找到所有的.py文件并删除就可以了:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
find . -name "*.py" -type f -print -exec rm -rf {} \;
|
||||||
|
```
|
||||||
|
|
||||||
|
这个看起来好危险,我还是觉得到目录下一个个删除比较好。
|
||||||
|
|
||||||
|
## JMPY的方案
|
||||||
|
|
||||||
|
安装
|
||||||
|
|
||||||
|
```she
|
||||||
|
pip install jmpy3
|
||||||
|
```
|
||||||
|
|
||||||
|
加密
|
||||||
|
|
||||||
|
```shell
|
||||||
|
jmpy -i "tobacco_color" [-o output dir]
|
||||||
|
```
|
||||||
|
|
||||||
|
加密后的文件默认存储在 dist/project_name/ 下
|
||||||
|
|
||||||
|
最后,根据测试的pyarmor并没有起到让人满意的加密效果,这令人很担忧,所以我暂时不购买测试。
|
||||||
|
|
||||||
|
# 开机自启动
|
||||||
|
|
||||||
|
要带有图形化界面的开机自启动不能把程序放到init.d底下,不然的话图形化界面还没起来就启动程序,会崩掉。
|
||||||
|
|
||||||
|
## 以.Desktop文件形式
|
||||||
|
|
||||||
|
1. 首先写一个`~/run.sh`,内容如下:
|
||||||
|
|
||||||
|
```shel
|
||||||
|
conda activate tobacco/deepo
|
||||||
|
python /home/<user_name>/tobacco_color/main.py -os # 这里的os表示only spectral,还有oc,不加就是都用上。
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 然后,写一个.desktop文件
|
||||||
|
|
||||||
|
```shel
|
||||||
|
[Desktop Entry]
|
||||||
|
Type=Application
|
||||||
|
Name=Tobacco
|
||||||
|
Exec=/home/<user_name>/run.sh
|
||||||
|
Icon=/home/<user_name>/Pictures/albert # 图标
|
||||||
|
Comment=烟草识别程序
|
||||||
|
X-GNOME-Autostart-enabled=true
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 把这个.desktop文件放到自启动目录下:`/home/<user_name>/.config/autostart`
|
||||||
|
|
||||||
|
## 图形化形式
|
||||||
|
|
||||||
|
上一步当中run.sh是无论如何都要有的
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
中文里边叫开机自启动,
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
甚至可以加入延时:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# 模拟运行与文件转换
|
||||||
|
|
||||||
|
## 模拟运行
|
||||||
|
|
||||||
|
需要模拟运行的话可以使用`main_test.py`脚本进行。模拟运行的方法如下:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python main_test.py /path/to/test
|
||||||
|
```
|
||||||
|
|
||||||
|
其中`/path/to/test`填写C程序抓取的运行时数据。运行后的数据如下:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 转换保存下来的buffer文件
|
||||||
|
|
||||||
|
脚本用法:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python main_test.py /path/to/convert -convert_dir /output/dir -s
|
||||||
|
```
|
||||||
|
|
||||||
|
这里`path/to/convert`填写转换的buffer文件夹,文件夹需要是只有rgb和spec文件`/output/dir`填输出文件夹,如果输出文件夹不存在就会创建。如果不加`-s(--silent)`静默参数就会顺便显示预测的结果。
|
||||||
|
|
||||||
|
转换后的图片经过测试可以正常在ENVI中打开:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
45
config.py
45
config.py
@ -1,4 +1,5 @@
|
|||||||
import torch
|
import os
|
||||||
|
|
||||||
import numpy as np
|
import numpy as np
|
||||||
|
|
||||||
|
|
||||||
@ -18,14 +19,42 @@ class Config:
|
|||||||
green_bands = [i for i in range(1, 21)]
|
green_bands = [i for i in range(1, 21)]
|
||||||
|
|
||||||
# 光谱模型参数
|
# 光谱模型参数
|
||||||
blk_size = 4
|
blk_size = 4 # 必须是2的倍数,不然会出错
|
||||||
pixel_model_path = r"./models/dt.p"
|
pixel_model_path = r"./weights/pixel_2022-08-02_15-22.model" # 开发时的路径
|
||||||
blk_model_path = r"./models/rf_4x4_c22_20_sen8_9.model"
|
# pixel_model_path = r"/home/dt/tobacco-color/weights/pixel_2022-08-02_15-22.model" # 机器上部署的路径
|
||||||
|
blk_model_path = r"./weights/rf_4x4_c22_20_sen8_9.model" # 开发时的路径
|
||||||
|
# blk_model_path = r"/home/dt/tobacco-color/weights/rf_4x4_c22_20_sen8_9.model" # 机器上部署的路径
|
||||||
spec_size_threshold = 3
|
spec_size_threshold = 3
|
||||||
|
|
||||||
|
s_threshold_a = 124 # s_a的最高允许值
|
||||||
|
s_threshold_b = 124 # s_b的最高允许值
|
||||||
|
|
||||||
# rgb模型参数
|
# rgb模型参数
|
||||||
rgb_tobacco_model_path = r"models/tobacco_dt_2022-07-26_15-57.model"
|
rgb_tobacco_model_path = r"weights/tobacco_dt_2022-08-27_14-43.model" # 开发时的路径
|
||||||
rgb_background_model_path = r"models/background_dt_2022-07-27_08-11.model"
|
# rgb_tobacco_model_path = r"/home/dt/tobacco-color/weights/tobacco_dt_2022-08-27_14-43.model" # 机器上部署的路径
|
||||||
|
rgb_background_model_path = r"weights/background_dt_2023-12-26_20-39.model" # 开发时的路径
|
||||||
|
# rgb_background_model_path = r"/home/dt/tobacco-color/weights/background_dt_2022-08-22_22-15.model" # 机器上部署的路径
|
||||||
threshold_low, threshold_high = 10, 230
|
threshold_low, threshold_high = 10, 230
|
||||||
threshold_s = 175
|
threshold_s = 190 # 饱和度的最高允许值
|
||||||
rgb_size_threshold = 4
|
threshold_a = 125 # a的最高允许值
|
||||||
|
threshold_b = 126 # b的最高允许值
|
||||||
|
rgb_size_threshold = 6 # rgb的尺寸限制
|
||||||
|
lab_size_threshold = 6 # lab的尺寸限制
|
||||||
|
ai_path = 'weights/best1227.pt' # 开发时的路径
|
||||||
|
# ai_path = '/home/dt/tobacco-color/weights/best0827.pt' # 机器上部署的路径
|
||||||
|
ai_conf_threshold = 0.8
|
||||||
|
|
||||||
|
# mask parameter
|
||||||
|
target_size = (1024, 1024) # (Width, Height) of mask
|
||||||
|
valve_merge_size = 2 # 每两个喷阀当中有任意一个出现杂质则认为都是杂质
|
||||||
|
valve_horizontal_padding = 5 # 喷阀横向膨胀的尺寸,应该是奇数,3时表示左右各膨胀1,5时表示左右各膨胀2(23.9.20老倪要求改为5)
|
||||||
|
max_open_valve_limit = 25 # 最大同时开启喷阀限制,按照电流计算,当前的喷阀可以开启的喷阀 600W的电源 / 12V电源 = 50A, 一个阀门1A
|
||||||
|
max_time_spent = 200
|
||||||
|
# save part
|
||||||
|
offset_vertical = 0
|
||||||
|
|
||||||
|
# logging
|
||||||
|
root_dir = os.path.split(os.path.realpath(__file__))[0]
|
||||||
|
log_freq = 1500 # 进行log的频率(多少次predict后进行log写出记录喷阀开启次数)
|
||||||
|
rgb_log_dir = 'rgb_log' # rgb log 文件夹
|
||||||
|
spec_log_dir = 'spec_log' # spec log 文件夹
|
||||||
|
|||||||
BIN
deploy/icon.jpeg
Normal file
BIN
deploy/icon.jpeg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 132 KiB |
2
deploy/main.sh
Executable file
2
deploy/main.sh
Executable file
@ -0,0 +1,2 @@
|
|||||||
|
cd /home/dt/tobacco-color/
|
||||||
|
/home/dt/miniconda3/envs/tobacco/bin/python /home/dt/tobacco-color/main.py -d
|
||||||
7
deploy/tobacco_algorithm.desktop
Executable file
7
deploy/tobacco_algorithm.desktop
Executable file
@ -0,0 +1,7 @@
|
|||||||
|
[Desktop Entry]
|
||||||
|
Type=Application
|
||||||
|
Name=Tobacco_Algorithm
|
||||||
|
Exec=/home/dt/tobacco-color/deploy/main.sh
|
||||||
|
Icon=/home/dt/tobacco-color/deploy/icon.jpeg
|
||||||
|
Comment=烟草识别程序
|
||||||
|
X-GNOME-Autostart-enabled=true
|
||||||
172
detector.py
Normal file
172
detector.py
Normal file
@ -0,0 +1,172 @@
|
|||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import os
|
||||||
|
import cv2
|
||||||
|
import json
|
||||||
|
|
||||||
|
from models.experimental import attempt_load
|
||||||
|
from utils.datasets import letterbox
|
||||||
|
from utils.general import check_img_size, non_max_suppression, scale_coords
|
||||||
|
from utils.torch_utils import select_device
|
||||||
|
|
||||||
|
|
||||||
|
root_dir = os.path.split(__file__)[0]
|
||||||
|
|
||||||
|
default_config = {'model_name': 'best.pt',
|
||||||
|
'model_path': os.path.join(root_dir, 'weights/'),
|
||||||
|
'conf_thres': 0.5}
|
||||||
|
|
||||||
|
cmd_param_dict = {'RL': ['conf_thres', lambda x: (100.0 - int(x)) / 100.0],
|
||||||
|
'MP': ['model_path', lambda x: str(x)],
|
||||||
|
'MN': ['model_name', lambda x: str(x)]}
|
||||||
|
|
||||||
|
|
||||||
|
class SugarDetect(object):
|
||||||
|
def __init__(self, model_path):
|
||||||
|
self.device = select_device(device='0' if torch.cuda.is_available() else 'cpu')
|
||||||
|
self.half = self.device.type != "cpu"
|
||||||
|
self.model = attempt_load(weights=model_path,
|
||||||
|
map_location=self.device)
|
||||||
|
self.stride = int(self.model.stride.max())
|
||||||
|
self.imgsz = check_img_size(640, s=self.stride) # check img_size
|
||||||
|
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names # get class names
|
||||||
|
if self.half:
|
||||||
|
self.model.half() # to FP16
|
||||||
|
# run once if on GPU
|
||||||
|
if self.device.type != 'cpu':
|
||||||
|
self.model(torch.zeros(1, 3, self.imgsz, self.imgsz).to(self.device).type_as(next(self.model.parameters())))
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def detect(self, img, conf_thres=0.5, return_mask=True):
|
||||||
|
half, device, model, stride = self.half, self.device, self.model, self.stride
|
||||||
|
iou_thres, classes, agnostic_nms, max_det = 0.45, None, True, 1000
|
||||||
|
names, imgsz = self.names, self.imgsz
|
||||||
|
|
||||||
|
im0_shape = img.shape
|
||||||
|
|
||||||
|
# Padded resize
|
||||||
|
img = letterbox(img, (imgsz, imgsz), stride=stride)[0]
|
||||||
|
|
||||||
|
# Convert
|
||||||
|
# img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
|
||||||
|
img = img.transpose(2, 0, 1) # to 3x416x416
|
||||||
|
img = np.ascontiguousarray(img)
|
||||||
|
|
||||||
|
# Preprocess
|
||||||
|
img = torch.from_numpy(img).to(device)
|
||||||
|
img = img.half() if half else img.float() # uint8 to fp16/32
|
||||||
|
img /= 255.0 # 0 - 255 to 0.0 - 1.0
|
||||||
|
if img.ndimension() == 3:
|
||||||
|
img = img.unsqueeze(0)
|
||||||
|
|
||||||
|
# Inference
|
||||||
|
pred = model(img, augment=False)[0]
|
||||||
|
|
||||||
|
# Apply NMS
|
||||||
|
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
|
||||||
|
|
||||||
|
# Process detections
|
||||||
|
s, det, boxes = "", pred[0], []
|
||||||
|
s += '%gx%g ' % img.shape[2:] # print string
|
||||||
|
gn = torch.tensor(im0_shape)[[1, 0, 1, 0]] # normalization gain whwh
|
||||||
|
if return_mask:
|
||||||
|
mask = np.zeros((im0_shape[0], im0_shape[1]), dtype=np.uint8)
|
||||||
|
if len(det):
|
||||||
|
# Rescale boxes from img_size to im0 size
|
||||||
|
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0_shape).round()
|
||||||
|
# Print results
|
||||||
|
# for c in det[:, -1].unique():
|
||||||
|
# n = (det[:, -1] == c).sum() # detections per class
|
||||||
|
# s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
|
||||||
|
# Write results
|
||||||
|
for *xyxy, conf, cls in reversed(det):
|
||||||
|
if return_mask:
|
||||||
|
c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
|
||||||
|
cv2.rectangle(mask, c1, c2, 1, thickness=-1)
|
||||||
|
else:
|
||||||
|
for i in range(4):
|
||||||
|
boxes.append((int(xyxy[i])))
|
||||||
|
if return_mask:
|
||||||
|
return mask
|
||||||
|
else:
|
||||||
|
return boxes
|
||||||
|
|
||||||
|
|
||||||
|
def read_config(config_file):
|
||||||
|
config = default_config
|
||||||
|
# get config from file
|
||||||
|
if not os.path.exists(config_file):
|
||||||
|
with open(config_file, 'w') as f:
|
||||||
|
json.dump(config, f)
|
||||||
|
else:
|
||||||
|
with open(config_file, 'r') as f:
|
||||||
|
config = json.load(f)
|
||||||
|
return config
|
||||||
|
|
||||||
|
|
||||||
|
def write_config(config_file, config=None):
|
||||||
|
if config is None:
|
||||||
|
config = default_config
|
||||||
|
dir_path, _ = os.path.split(config_file)
|
||||||
|
if not os.path.exists(dir_path):
|
||||||
|
print(f"Path '{dir_path}' not exist, try to create.")
|
||||||
|
os.makedirs(dir_path)
|
||||||
|
with open(config_file, 'w') as f:
|
||||||
|
json.dump(config, f)
|
||||||
|
with open(config['model_path']+"current_model.txt", "w") as f:
|
||||||
|
f.write(config["model_name"])
|
||||||
|
|
||||||
|
|
||||||
|
def main(height, width, channel):
|
||||||
|
img_pipe_path = "/tmp/img_fifo.pipe"
|
||||||
|
result_pipe_path = "/tmp/result_fifo.pipe"
|
||||||
|
|
||||||
|
config_file = os.path.join(root_dir, 'config.json')
|
||||||
|
config = read_config(config_file)
|
||||||
|
detect = SugarDetect(model_path=os.path.join(config['model_path'], config['model_name']))
|
||||||
|
# 第一次检测太慢,先预测一张
|
||||||
|
test_img = np.zeros((height, width, channel), dtype=np.uint8)
|
||||||
|
detect.detect(test_img)
|
||||||
|
print("load success")
|
||||||
|
|
||||||
|
if not os.access(img_pipe_path, os.F_OK): # 判断管道是否存在,不存在创建
|
||||||
|
os.mkfifo(img_pipe_path)
|
||||||
|
if not os.access(result_pipe_path, os.F_OK):
|
||||||
|
os.mkfifo(result_pipe_path)
|
||||||
|
fd_img = os.open(img_pipe_path, os.O_RDONLY) # 打开管道
|
||||||
|
print("Open pipe successful.")
|
||||||
|
while True:
|
||||||
|
data = os.read(fd_img, height * width * channel)
|
||||||
|
if len(data) == 0:
|
||||||
|
continue
|
||||||
|
elif len(data) < 128: # 切换分选糖果类型
|
||||||
|
cmd = data.decode()
|
||||||
|
print("to python: ", cmd)
|
||||||
|
for cmd_pattern, para_f in cmd_param_dict.items():
|
||||||
|
if cmd.startswith(cmd_pattern):
|
||||||
|
para, f = para_f
|
||||||
|
print(f"modify para {para}")
|
||||||
|
try:
|
||||||
|
cmd_value = cmd.split(':')[-1] # split to get command value with ':'
|
||||||
|
config[para] = f(cmd_value) # convert value with function defined on the top
|
||||||
|
except Exception as e:
|
||||||
|
print(f"Convert command Error with '{e}'.")
|
||||||
|
write_config(config_file, config)
|
||||||
|
detect = SugarDetect(model_path=config['model_path']+config['model_name'])
|
||||||
|
else: # 检测缺陷糖果
|
||||||
|
img = np.frombuffer(data, dtype=np.uint8).reshape((height, width, channel))
|
||||||
|
points = detect.detect(img, config['conf_thres'])
|
||||||
|
|
||||||
|
points_bytes = b''
|
||||||
|
if len(points) == 0:
|
||||||
|
for i in range(4):
|
||||||
|
points.append(0)
|
||||||
|
for i in points:
|
||||||
|
points_bytes = points_bytes + i.to_bytes(2, 'big') # 转为字节流
|
||||||
|
fd_result = os.open(result_pipe_path, os.O_WRONLY)
|
||||||
|
os.write(fd_result, points_bytes) # 返回结果
|
||||||
|
os.close(fd_result)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main(height=584, width=2376, channel=3)
|
||||||
@ -23,11 +23,12 @@ class EfficientUI(object):
|
|||||||
spec_receiver = transmit.FifoReceiver(fifo_path=img_fifo_path, output=spec_img_queue, read_max_num=spec_len)
|
spec_receiver = transmit.FifoReceiver(fifo_path=img_fifo_path, output=spec_img_queue, read_max_num=spec_len)
|
||||||
rgb_receiver = transmit.FifoReceiver(fifo_path=rgb_fifo_path, output=rgb_img_queue, read_max_num=rgb_len)
|
rgb_receiver = transmit.FifoReceiver(fifo_path=rgb_fifo_path, output=rgb_img_queue, read_max_num=rgb_len)
|
||||||
# 指令执行与图像流向控制
|
# 指令执行与图像流向控制
|
||||||
subscribers = {'detector': detector_queue, 'visualize': self.visual_queue, 'save': save_queue}
|
# subscribers = {'detector': detector_queue, 'visualize': self.visual_queue, 'save': save_queue}
|
||||||
|
subscribers = {"detector": detector_queue, 'save': save_queue, 'visualize': self.visual_queue}
|
||||||
cmd_img_controller = transmit.CmdImgSplitMidware(rgb_queue=rgb_img_queue, spec_queue=spec_img_queue,
|
cmd_img_controller = transmit.CmdImgSplitMidware(rgb_queue=rgb_img_queue, spec_queue=spec_img_queue,
|
||||||
subscribers=subscribers)
|
subscribers=subscribers)
|
||||||
# 探测器
|
# 探测器
|
||||||
detector = transmit.ThreadDetector(input_queue=detector_queue, output_queue=mask_queue)
|
detector = transmit.ProcessDetector(input_queue=detector_queue, output_queue=mask_queue)
|
||||||
# 发送
|
# 发送
|
||||||
sender = transmit.FifoSender(output_fifo_path=mask_fifo_path, source=mask_queue)
|
sender = transmit.FifoSender(output_fifo_path=mask_fifo_path, source=mask_queue)
|
||||||
# 启动所有线程
|
# 启动所有线程
|
||||||
|
|||||||
215
main.py
215
main.py
@ -1,86 +1,195 @@
|
|||||||
import os
|
import os
|
||||||
|
from datetime import datetime
|
||||||
|
from pathlib import Path
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import cv2
|
||||||
import time
|
import time
|
||||||
from queue import Queue
|
|
||||||
|
|
||||||
import numpy as np
|
import numpy as np
|
||||||
from matplotlib import pyplot as plt
|
|
||||||
|
|
||||||
import models
|
|
||||||
import transmit
|
|
||||||
|
|
||||||
|
import utils
|
||||||
|
import utils as utils_customized
|
||||||
from config import Config
|
from config import Config
|
||||||
from models import RgbDetector, SpecDetector
|
from models import RgbDetector, SpecDetector
|
||||||
import cv2
|
import logging
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main(only_spec=False, only_color=False, if_merge=False, interval_time=None, delay_repeat_time=None,
|
||||||
|
single_spec=False, single_color=False):
|
||||||
spec_detector = SpecDetector(blk_model_path=Config.blk_model_path, pixel_model_path=Config.pixel_model_path)
|
spec_detector = SpecDetector(blk_model_path=Config.blk_model_path, pixel_model_path=Config.pixel_model_path)
|
||||||
rgb_detector = RgbDetector(tobacco_model_path=Config.rgb_tobacco_model_path,
|
rgb_detector = RgbDetector(tobacco_model_path=Config.rgb_tobacco_model_path,
|
||||||
background_model_path=Config.rgb_background_model_path)
|
background_model_path=Config.rgb_background_model_path,
|
||||||
|
ai_path=Config.ai_path)
|
||||||
|
_, _ = spec_detector.predict(np.ones((Config.nRows, Config.nCols, Config.nBands), dtype=float) * 0.4), \
|
||||||
|
rgb_detector.predict(np.ones((Config.nRgbRows, Config.nRgbCols, Config.nRgbBands), dtype=np.uint8) * 40)
|
||||||
total_len = Config.nRows * Config.nCols * Config.nBands * 4 # float型变量, 4个字节
|
total_len = Config.nRows * Config.nCols * Config.nBands * 4 # float型变量, 4个字节
|
||||||
total_rgb = Config.nRgbRows * Config.nRgbCols * Config.nRgbBands * 1 # int型变量
|
total_rgb = Config.nRgbRows * Config.nRgbCols * Config.nRgbBands * 1 # int型变量
|
||||||
|
log_file_name = datetime.now().strftime('%Y_%m_%d__%H_%M_%S.log')
|
||||||
|
if single_spec:
|
||||||
|
os.makedirs(Path(Config.root_dir) / Path(Config.rgb_log_dir), exist_ok=True)
|
||||||
|
log_path = Path(Config.root_dir) / Path(Config.rgb_log_dir) / log_file_name
|
||||||
|
if single_color:
|
||||||
|
os.makedirs(Path(Config.root_dir) / Path(Config.spec_log_dir), exist_ok=True)
|
||||||
|
log_path = Path(Config.root_dir) / Path(Config.spec_log_dir) / log_file_name
|
||||||
|
if not single_color:
|
||||||
|
logging.info("create color fifo")
|
||||||
if not os.access(img_fifo_path, os.F_OK):
|
if not os.access(img_fifo_path, os.F_OK):
|
||||||
os.mkfifo(img_fifo_path, 0o777)
|
os.mkfifo(img_fifo_path, 0o777)
|
||||||
if not os.access(mask_fifo_path, os.F_OK):
|
if not os.access(mask_fifo_path, os.F_OK):
|
||||||
os.mkfifo(mask_fifo_path, 0o777)
|
os.mkfifo(mask_fifo_path, 0o777)
|
||||||
|
if not single_spec:
|
||||||
|
logging.info("create rgb fifo")
|
||||||
if not os.access(rgb_fifo_path, os.F_OK):
|
if not os.access(rgb_fifo_path, os.F_OK):
|
||||||
os.mkfifo(rgb_fifo_path, 0o777)
|
os.mkfifo(rgb_fifo_path, 0o777)
|
||||||
|
if not os.access(rgb_mask_fifo_path, os.F_OK):
|
||||||
|
os.mkfifo(rgb_mask_fifo_path, 0o777)
|
||||||
|
logging.info(f"请注意!正在以调试模式运行程序,输出的信息可能较多。")
|
||||||
|
# specially designed for Miaow.
|
||||||
|
if (interval_time is not None) and (delay_repeat_time is not None):
|
||||||
|
interval_time = float(interval_time) / 1000.0
|
||||||
|
delay_repeat_time = int(delay_repeat_time)
|
||||||
|
logging.warning(f'Delay {interval_time * 1000:.2f}ms will be added per {delay_repeat_time} frames')
|
||||||
|
delay_repeat_time_count = 0
|
||||||
|
|
||||||
|
log_time_count, value_num_count = 0, 0
|
||||||
while True:
|
while True:
|
||||||
|
img_data, rgb_data = None, None
|
||||||
|
if single_spec:
|
||||||
fd_img = os.open(img_fifo_path, os.O_RDONLY)
|
fd_img = os.open(img_fifo_path, os.O_RDONLY)
|
||||||
fd_rgb = os.open(rgb_fifo_path, os.O_RDONLY)
|
|
||||||
|
|
||||||
# spec data read
|
# spec data read
|
||||||
data = os.read(fd_img, total_len)
|
data_total = os.read(fd_img, total_len)
|
||||||
if len(data) < 3:
|
if len(data_total) < 3:
|
||||||
threshold = int(float(data))
|
try:
|
||||||
|
threshold = int(float(data_total))
|
||||||
Config.spec_size_threshold = threshold
|
Config.spec_size_threshold = threshold
|
||||||
print("[INFO] Get spec threshold: ", threshold)
|
logging.info(f'[INFO] Get spec threshold: {threshold}')
|
||||||
else:
|
except Exception as e:
|
||||||
data_total = data
|
logging.error(
|
||||||
os.close(fd_img)
|
f'毁灭性错误:收到长度小于3却无法转化为整数spec_size_threshold的网络报文,报文内容为 {data_total},'
|
||||||
|
f' 错误为 {e}.')
|
||||||
# rgb data read
|
if single_spec:
|
||||||
rgb_data = os.read(fd_rgb, total_rgb)
|
|
||||||
if len(rgb_data) < 3:
|
|
||||||
rgb_threshold = int(float(rgb_data))
|
|
||||||
Config.rgb_size_threshold = rgb_threshold
|
|
||||||
print("[INFO] Get rgb threshold", rgb_threshold)
|
|
||||||
continue
|
continue
|
||||||
else:
|
else:
|
||||||
rgb_data_total = rgb_data
|
data_total = data_total
|
||||||
os.close(fd_rgb)
|
os.close(fd_img)
|
||||||
|
try:
|
||||||
# 识别
|
|
||||||
t1 = time.time()
|
|
||||||
img_data = np.frombuffer(data_total, dtype=np.float32).reshape((Config.nRows, Config.nBands, -1)) \
|
img_data = np.frombuffer(data_total, dtype=np.float32).reshape((Config.nRows, Config.nBands, -1)) \
|
||||||
.transpose(0, 2, 1)
|
.transpose(0, 2, 1)
|
||||||
rgb_data = np.frombuffer(rgb_data_total, dtype=np.uint8).reshape((Config.nRgbRows, Config.nRgbCols, -1))
|
except Exception as e:
|
||||||
# 光谱识别
|
logging.error(f'毁灭性错误!收到的光谱数据长度为{len(data_total)}无法转化成指定的形状 {e}')
|
||||||
mask = spec_detector.predict(img_data)
|
|
||||||
# rgb识别
|
|
||||||
mask_rgb = rgb_detector.predict(rgb_data)
|
|
||||||
# 结果合并
|
|
||||||
mask_result = (mask | mask_rgb).astype(np.uint8)
|
|
||||||
# mask_result = mask_rgb.astype(np.uint8)
|
|
||||||
mask_result = mask_result.repeat(Config.blk_size, axis=0).repeat(Config.blk_size, axis=1).astype(np.uint8)
|
|
||||||
t2 = time.time()
|
|
||||||
print(f'rgb len = {len(rgb_data)}')
|
|
||||||
|
|
||||||
|
if single_color:
|
||||||
|
fd_rgb = os.open(rgb_fifo_path, os.O_RDONLY)
|
||||||
|
# rgb data read
|
||||||
|
rgb_data_total = os.read(fd_rgb, total_rgb)
|
||||||
|
if len(rgb_data_total) < 3:
|
||||||
|
try:
|
||||||
|
rgb_threshold = int(float(rgb_data_total))
|
||||||
|
Config.rgb_size_threshold = rgb_threshold
|
||||||
|
logging.info(f'Get rgb threshold: {rgb_threshold}')
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(
|
||||||
|
f'毁灭性错误:收到长度小于3却无法转化为整数spec_size_threshold的网络报文,报文内容为 {total_rgb},'
|
||||||
|
f' 错误为 {e}.')
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
rgb_data_total = rgb_data_total
|
||||||
|
os.close(fd_rgb)
|
||||||
|
try:
|
||||||
|
rgb_data = np.frombuffer(rgb_data_total, dtype=np.uint8).reshape((Config.nRgbRows, Config.nRgbCols, -1))
|
||||||
|
except Exception as e:
|
||||||
|
logging.error(f'毁灭性错误!收到的rgb数据长度为{len(rgb_data_total)}无法转化成指定形状 {e}')
|
||||||
|
|
||||||
|
# 识别 read
|
||||||
|
since = time.time()
|
||||||
|
# predict
|
||||||
|
if single_spec or single_color:
|
||||||
|
if single_spec:
|
||||||
|
mask_spec = spec_detector.predict(img_data).astype(np.uint8)
|
||||||
|
masks = [mask_spec, ]
|
||||||
|
else:
|
||||||
|
mask_rgb = rgb_detector.predict(rgb_data).astype(np.uint8)
|
||||||
|
masks = [mask_rgb, ]
|
||||||
|
else:
|
||||||
|
if only_spec:
|
||||||
|
# 光谱识别
|
||||||
|
mask_spec = spec_detector.predict(img_data).astype(np.uint8)
|
||||||
|
mask_rgb = np.zeros_like(mask_spec, dtype=np.uint8)
|
||||||
|
elif only_color:
|
||||||
|
# rgb识别
|
||||||
|
mask_rgb = rgb_detector.predict(rgb_data).astype(np.uint8)
|
||||||
|
mask_spec = np.zeros_like(mask_rgb, dtype=np.uint8)
|
||||||
|
else:
|
||||||
|
mask_spec = spec_detector.predict(img_data).astype(np.uint8)
|
||||||
|
mask_rgb = rgb_detector.predict(rgb_data).astype(np.uint8)
|
||||||
|
masks = [mask_spec, mask_rgb]
|
||||||
|
# 进行多个喷阀的合并
|
||||||
|
masks = [utils_customized.shield_valve(mask, left_shield=10, right_shield=10) for mask in masks]
|
||||||
|
masks = [utils_customized.valve_expend(mask) for mask in masks]
|
||||||
|
mask_nums = sum([np.sum(np.sum(mask)) for mask in masks])
|
||||||
|
log_time_count += 1
|
||||||
|
value_num_count += mask_nums
|
||||||
|
if log_time_count > Config.log_freq:
|
||||||
|
utils.valve_log(log_path, valve_num=value_num_count)
|
||||||
|
log_time_count, value_num_count = 0, 0
|
||||||
|
|
||||||
|
# 进行喷阀同时开启限制,在8月11日后收到倪超老师的电话,关闭
|
||||||
|
# masks = [utils_customized.valve_limit(mask, Config.max_open_valve_limit) for mask in masks]
|
||||||
|
# control the size of the output masks, 在resize前,图像的宽度是和喷阀对应的
|
||||||
|
masks = [cv2.resize(mask.astype(np.uint8), Config.target_size) for mask in masks]
|
||||||
|
# merge the masks if needed
|
||||||
|
if if_merge and (len(masks) > 1):
|
||||||
|
masks = [masks[0] | masks[1], masks[1]]
|
||||||
|
if (interval_time is not None) and (delay_repeat_time is not None):
|
||||||
|
delay_repeat_time_count += 1
|
||||||
|
if delay_repeat_time_count > delay_repeat_time:
|
||||||
|
logging.warning(f"Delay time {interval_time * 1000:.2f}ms after {delay_repeat_time} frames")
|
||||||
|
delay_repeat_time_count = 0
|
||||||
|
time.sleep(interval_time)
|
||||||
# 写出
|
# 写出
|
||||||
fd_mask = os.open(mask_fifo_path, os.O_WRONLY)
|
if single_spec:
|
||||||
os.write(fd_mask, mask_result.tobytes())
|
output_fifos = [mask_fifo_path, ]
|
||||||
|
elif single_color:
|
||||||
|
output_fifos = [rgb_mask_fifo_path, ]
|
||||||
|
else:
|
||||||
|
output_fifos = [mask_fifo_path, rgb_mask_fifo_path]
|
||||||
|
for fifo, mask in zip(output_fifos, masks):
|
||||||
|
fd_mask = os.open(fifo, os.O_WRONLY)
|
||||||
|
os.write(fd_mask, mask.tobytes())
|
||||||
os.close(fd_mask)
|
os.close(fd_mask)
|
||||||
t3 = time.time()
|
time_spent = (time.time() - since) * 1000
|
||||||
print(f'total time is:{t3 - t1}')
|
predict_by = 'spec' if single_spec else 'rgb' if single_color else 'spec+rgb'
|
||||||
|
logging.info(f'Total time is: {time_spent:.2f} ms, predicted by {predict_by}')
|
||||||
|
if time_spent > Config.max_time_spent:
|
||||||
|
logging.warning(f'警告预测超时,预测耗时超过了200ms,The prediction time is {time_spent:.2f} ms.')
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == '__main__':
|
||||||
# 相关参数
|
import argparse
|
||||||
img_fifo_path = "/tmp/dkimg.fifo"
|
|
||||||
mask_fifo_path = "/tmp/dkmask.fifo"
|
|
||||||
rgb_fifo_path = "/tmp/dkrgb.fifo"
|
|
||||||
|
|
||||||
# 主函数
|
parser = argparse.ArgumentParser(description='主程序')
|
||||||
main()
|
parser.add_argument('-oc', default=False, action='store_true', help='只进行RGB彩色预测 only rgb', required=False)
|
||||||
# read_c_captures('/home/lzy/2022.7.15/tobacco_v1_0/', no_mask=True, nrows=256, ncols=1024,
|
parser.add_argument('-os', default=False, action='store_true', help='只进行光谱预测 only spec', required=False)
|
||||||
# selected_bands=[380, 300, 200])
|
parser.add_argument('-sc', default=False, action='store_true', help='只进行RGB预测且只返回一个mask', required=False)
|
||||||
|
parser.add_argument('-ss', default=False, action='store_true', help='只进行光谱预测且只返回一个mask',
|
||||||
|
required=False)
|
||||||
|
parser.add_argument('-m', default=False, action='store_true', help='if merge the two masks', required=False)
|
||||||
|
parser.add_argument('-d', default=False, action='store_true', help='是否使用DEBUG模式', required=False)
|
||||||
|
parser.add_argument('-dt', default=None, help='delay time', required=False)
|
||||||
|
parser.add_argument('-df', default=None, help='delay occours after how many frames', required=False)
|
||||||
|
args = parser.parse_args()
|
||||||
|
# fifo 参数
|
||||||
|
img_fifo_path = '/tmp/dkimg.fifo'
|
||||||
|
rgb_fifo_path = '/tmp/dkrgb.fifo'
|
||||||
|
# mask fifo
|
||||||
|
mask_fifo_path = '/tmp/dkmask.fifo'
|
||||||
|
rgb_mask_fifo_path = '/tmp/dkmask_rgb.fifo'
|
||||||
|
# logging相关
|
||||||
|
file_handler = logging.FileHandler(os.path.join(Config.root_dir, '.tobacco_algorithm.log'))
|
||||||
|
file_handler.setLevel(logging.DEBUG if args.d else logging.WARNING)
|
||||||
|
console_handler = logging.StreamHandler(sys.stdout)
|
||||||
|
console_handler.setLevel(logging.DEBUG if args.d else logging.WARNING)
|
||||||
|
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(message)s',
|
||||||
|
handlers=[file_handler, console_handler], level=logging.DEBUG)
|
||||||
|
main(only_spec=args.os, only_color=args.oc, if_merge=args.m, interval_time=args.dt, delay_repeat_time=args.df,
|
||||||
|
single_spec=args.ss, single_color=args.sc)
|
||||||
|
|||||||
181
main_test.py
181
main_test.py
@ -3,35 +3,50 @@
|
|||||||
# @Auther : zhouchao
|
# @Auther : zhouchao
|
||||||
# @File: main_test.py
|
# @File: main_test.py
|
||||||
# @Software:PyCharm
|
# @Software:PyCharm
|
||||||
|
import datetime
|
||||||
|
import itertools
|
||||||
|
import logging
|
||||||
import os
|
import os
|
||||||
import time
|
import time
|
||||||
|
import socket
|
||||||
|
import typing
|
||||||
|
from shutil import copyfile
|
||||||
|
|
||||||
import cv2
|
import cv2
|
||||||
|
import matplotlib
|
||||||
import matplotlib.pyplot as plt
|
import matplotlib.pyplot as plt
|
||||||
import numpy as np
|
import numpy as np
|
||||||
|
from matplotlib.gridspec import GridSpec
|
||||||
|
import tqdm
|
||||||
|
|
||||||
import transmit
|
import transmit
|
||||||
|
import utils
|
||||||
from config import Config
|
from config import Config
|
||||||
from models import Detector, AnonymousColorDetector, ManualTree, SpecDetector, RgbDetector
|
from models import Detector, AnonymousColorDetector, ManualTree, SpecDetector, RgbDetector
|
||||||
from utils import read_labeled_img, size_threshold, natural_sort
|
from utils import read_labeled_img, size_threshold, natural_sort
|
||||||
|
|
||||||
|
matplotlib.use('TkAgg')
|
||||||
|
|
||||||
|
|
||||||
class TestMain:
|
class TestMain:
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self._spec_detector = SpecDetector(blk_model_path=Config.blk_model_path,
|
self._spec_detector = SpecDetector(blk_model_path=Config.blk_model_path,
|
||||||
pixel_model_path=Config.pixel_model_path)
|
pixel_model_path=Config.pixel_model_path)
|
||||||
self._rgb_detector = RgbDetector(tobacco_model_path=Config.rgb_tobacco_model_path,
|
self._rgb_detector = RgbDetector(tobacco_model_path=Config.rgb_tobacco_model_path,
|
||||||
background_model_path=Config.rgb_background_model_path)
|
background_model_path=Config.rgb_background_model_path,
|
||||||
|
ai_path=Config.ai_path)
|
||||||
|
|
||||||
def pony_run(self, test_path, test_spectra=False, test_rgb=False,
|
def pony_run(self, test_path, test_spectra=False, test_rgb=False,
|
||||||
convert=False):
|
convert_dir=None, get_delta=False, silent=False):
|
||||||
"""
|
"""
|
||||||
虚拟读图测试程序
|
虚拟读图测试程序
|
||||||
|
|
||||||
:param test_path: 测试文件夹或者图片
|
:param test_path: 测试文件夹或者图片
|
||||||
:param test_spectra: 是否测试光谱
|
:param test_spectra: 是否测试光谱
|
||||||
:param test_rgb: 是否测试rgb
|
:param test_rgb: 是否测试rgb
|
||||||
:param convert: 是否进行格式转化
|
:param convert_dir: 格式转化文件夹
|
||||||
|
:param get_delta:是否计算偏差
|
||||||
|
:param silent: 是否静默模式运行
|
||||||
:return:
|
:return:
|
||||||
"""
|
"""
|
||||||
if os.path.isdir(test_path):
|
if os.path.isdir(test_path):
|
||||||
@ -43,31 +58,66 @@ class TestMain:
|
|||||||
with open(test_path, 'rb') as f:
|
with open(test_path, 'rb') as f:
|
||||||
data = f.read()
|
data = f.read()
|
||||||
spec_img = transmit.BeforeAfterMethods.spec_data_post_process(data)
|
spec_img = transmit.BeforeAfterMethods.spec_data_post_process(data)
|
||||||
_ = self.test_spec(spec_img=spec_img)
|
_ = self.test_spec(spec_img=spec_img, img_name=test_path)
|
||||||
elif test_rgb:
|
elif test_rgb:
|
||||||
with open(test_path, 'rb') as f:
|
with open(test_path, 'rb') as f:
|
||||||
data = f.read()
|
data = f.read()
|
||||||
rgb_img = transmit.BeforeAfterMethods.rgb_data_post_process(data)
|
rgb_img = transmit.BeforeAfterMethods.rgb_data_post_process(data)
|
||||||
_ = self.test_rgb(rgb_img)
|
_ = self.test_rgb(rgb_img, img_name=test_path)
|
||||||
return
|
return
|
||||||
|
if silent and convert_dir is not None:
|
||||||
|
bar = tqdm.tqdm(desc='正在转换', total=len(rgb_file_names), ncols=80)
|
||||||
for rgb_file_name, spec_file_name in zip(rgb_file_names, spec_file_names):
|
for rgb_file_name, spec_file_name in zip(rgb_file_names, spec_file_names):
|
||||||
|
rgb_temp, spec_temp = rgb_file_name[:], spec_file_name[:]
|
||||||
|
assert rgb_temp.replace('rgb', '') == spec_temp.replace('spec', '')
|
||||||
if test_spectra:
|
if test_spectra:
|
||||||
with open(os.path.join(test_path, spec_file_name), 'rb') as f:
|
with open(os.path.join(test_path, spec_file_name), 'rb') as f:
|
||||||
data = f.read()
|
data = f.read()
|
||||||
|
try:
|
||||||
spec_img = transmit.BeforeAfterMethods.spec_data_post_process(data)
|
spec_img = transmit.BeforeAfterMethods.spec_data_post_process(data)
|
||||||
spec_mask = self.test_spec(spec_img, img_name=spec_file_name)
|
except Exception as e:
|
||||||
|
raise FileExistsError(f'文件 {spec_file_name} 读取失败,长度不对. 请清理文件夹{test_path},'
|
||||||
|
f'去除{spec_file_name}\n {e}')
|
||||||
|
|
||||||
|
if convert_dir is not None:
|
||||||
|
spec_img_show = np.asarray(np.clip(spec_img[..., [21, 3, 0]] * 255, a_min=0, a_max=255),
|
||||||
|
dtype=np.uint8)
|
||||||
|
cv2.imwrite(os.path.join(convert_dir, spec_file_name + '.bmp'), spec_img_show[..., ::-1])
|
||||||
|
hdr_string = utils.generate_hdr(f'File imported from {spec_file_name} at'
|
||||||
|
f' {datetime.datetime.now().strftime("%m/%d/%Y, %H:%M")}')
|
||||||
|
copyfile(os.path.join(test_path, spec_file_name), os.path.join(convert_dir, spec_file_name+'.raw'))
|
||||||
|
|
||||||
|
with open(os.path.join(convert_dir, spec_file_name + '.hdr'), 'w') as f:
|
||||||
|
f.write(hdr_string)
|
||||||
|
spec_mask = self.test_spec(spec_img, img_name=spec_file_name, show=False)
|
||||||
if test_rgb:
|
if test_rgb:
|
||||||
with open(os.path.join(test_path, rgb_file_name), 'rb') as f:
|
with open(os.path.join(test_path, rgb_file_name), 'rb') as f:
|
||||||
data = f.read()
|
data = f.read()
|
||||||
|
try:
|
||||||
rgb_img = transmit.BeforeAfterMethods.rgb_data_post_process(data)
|
rgb_img = transmit.BeforeAfterMethods.rgb_data_post_process(data)
|
||||||
rgb_mask = self.test_rgb(rgb_img, img_name=rgb_file_name)
|
except Exception as e:
|
||||||
|
raise FileExistsError(f'文件 {rgb_file_name} 读取失败, 长度不对. 请清理文件夹{test_path},'
|
||||||
|
f' 去除{rgb_file_name} \n {e}')
|
||||||
|
|
||||||
|
if convert_dir is not None:
|
||||||
|
cv2.imwrite(os.path.join(convert_dir, rgb_file_name + '.bmp'), rgb_img[..., ::-1])
|
||||||
|
rgb_mask = self.test_rgb(rgb_img, img_name=rgb_file_name, show=False)
|
||||||
if test_rgb and test_spectra:
|
if test_rgb and test_spectra:
|
||||||
|
if get_delta:
|
||||||
|
spec_cv = np.clip(spec_img[..., [21, 3, 0]], a_min=0, a_max=1) * 255
|
||||||
|
spec_cv = spec_cv.astype(np.uint8)
|
||||||
|
delta = self.calculate_delta(rgb_img, spec_cv)
|
||||||
|
print(delta)
|
||||||
self.merge(rgb_img=rgb_img, rgb_mask=rgb_mask,
|
self.merge(rgb_img=rgb_img, rgb_mask=rgb_mask,
|
||||||
spec_img=spec_img[..., [21, 3, 0]], spec_mask=spec_mask,
|
spec_img=spec_img[..., [21, 3, 0]], spec_mask=spec_mask,
|
||||||
file_name=rgb_file_name)
|
rgb_file_name=rgb_file_name, spec_file_name=spec_file_name,
|
||||||
|
show=not silent)
|
||||||
|
if silent and convert_dir is not None:
|
||||||
|
bar.update()
|
||||||
|
|
||||||
def test_rgb(self, rgb_img, img_name):
|
def test_rgb(self, rgb_img, img_name, show=True):
|
||||||
rgb_mask = self._rgb_detector.predict(rgb_img)
|
rgb_mask = self._rgb_detector.predict(rgb_img)
|
||||||
|
if show:
|
||||||
fig, axs = plt.subplots(2, 1)
|
fig, axs = plt.subplots(2, 1)
|
||||||
axs[0].imshow(rgb_img)
|
axs[0].imshow(rgb_img)
|
||||||
axs[0].set_title(f"rgb img {img_name}")
|
axs[0].set_title(f"rgb img {img_name}")
|
||||||
@ -76,8 +126,9 @@ class TestMain:
|
|||||||
plt.show()
|
plt.show()
|
||||||
return rgb_mask
|
return rgb_mask
|
||||||
|
|
||||||
def test_spec(self, spec_img, img_name):
|
def test_spec(self, spec_img, img_name, show=True):
|
||||||
spec_mask = self._spec_detector.predict(spec_img)
|
spec_mask = self._spec_detector.predict(spec_img)
|
||||||
|
if show:
|
||||||
fig, axs = plt.subplots(2, 1)
|
fig, axs = plt.subplots(2, 1)
|
||||||
axs[0].imshow(spec_img[..., [21, 3, 0]])
|
axs[0].imshow(spec_img[..., [21, 3, 0]])
|
||||||
axs[0].set_title(f"spec img {img_name}")
|
axs[0].set_title(f"spec img {img_name}")
|
||||||
@ -87,22 +138,108 @@ class TestMain:
|
|||||||
return spec_mask
|
return spec_mask
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def merge(rgb_img, rgb_mask, spec_img, spec_mask, file_name):
|
def merge(rgb_img, rgb_mask, spec_img, spec_mask, rgb_file_name, spec_file_name, show=True):
|
||||||
mask_result = (spec_mask | rgb_mask).astype(np.uint8)
|
mask_result = (spec_mask | rgb_mask).astype(np.uint8)
|
||||||
mask_result = mask_result.repeat(Config.blk_size, axis=0).repeat(Config.blk_size, axis=1).astype(np.uint8)
|
mask_result = mask_result.repeat(Config.blk_size, axis=0).repeat(Config.blk_size, axis=1).astype(np.uint8)
|
||||||
fig, axs = plt.subplots(3, 2)
|
if show:
|
||||||
axs[0, 0].set_title(file_name)
|
fig = plt.figure(constrained_layout=True)
|
||||||
axs[0, 0].imshow(rgb_img)
|
gs = GridSpec(3, 2, figure=fig)
|
||||||
axs[1, 0].imshow(spec_img)
|
ax1 = fig.add_subplot(gs[0, 0])
|
||||||
axs[2, 0].imshow(mask_result)
|
ax2 = fig.add_subplot(gs[0, 1])
|
||||||
axs[0, 1].imshow(rgb_mask)
|
ax3 = fig.add_subplot(gs[1, 0])
|
||||||
axs[1, 1].imshow(spec_mask)
|
ax4 = fig.add_subplot(gs[1, 1])
|
||||||
axs[2, 1].imshow(mask_result)
|
ax5 = fig.add_subplot(gs[2, :])
|
||||||
|
|
||||||
|
fig.suptitle("Result")
|
||||||
|
|
||||||
|
ax1.imshow(rgb_img)
|
||||||
|
ax1.set_title(rgb_file_name)
|
||||||
|
ax2.imshow(rgb_mask)
|
||||||
|
ax2.set_title("rgb mask")
|
||||||
|
|
||||||
|
ax3.imshow(np.clip(spec_img, a_min=0, a_max=1))
|
||||||
|
ax3.set_title(spec_file_name)
|
||||||
|
ax4.imshow(spec_mask)
|
||||||
|
ax4.set_title('spec mask')
|
||||||
|
|
||||||
|
ax5.imshow(mask_result)
|
||||||
|
ax5.set_title('merge mask')
|
||||||
plt.show()
|
plt.show()
|
||||||
return mask_result
|
return mask_result
|
||||||
|
|
||||||
|
def calculate_delta(self, rgb_img, spec_img, search_area_size=(400, 200), eps=1):
|
||||||
|
rgb_grey, spec_grey = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2GRAY), cv2.cvtColor(spec_img, cv2.COLOR_RGB2GRAY)
|
||||||
|
_, rgb_bin = cv2.threshold(rgb_grey, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
|
||||||
|
_, spec_bin = cv2.threshold(spec_grey, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
|
||||||
|
spec_bin = cv2.resize(spec_bin, dsize=(rgb_bin.shape[1], rgb_bin.shape[0]))
|
||||||
|
search_area = np.zeros(search_area_size)
|
||||||
|
for x in range(0, search_area_size[0], eps):
|
||||||
|
for y in range(0, search_area_size[1], eps):
|
||||||
|
delta_x, delta_y = x - search_area_size[0] // 2, y - search_area_size[1] // 2
|
||||||
|
rgb_cross_area = self.get_cross_area(rgb_bin, delta_x, delta_y)
|
||||||
|
spce_cross_area = self.get_cross_area(spec_bin, -delta_x, -delta_y)
|
||||||
|
response_altitude = np.sum(np.sum(rgb_cross_area & spce_cross_area))
|
||||||
|
search_area[x, y] = response_altitude
|
||||||
|
delta = np.unravel_index(np.argmax(search_area), search_area.shape)
|
||||||
|
delta = (delta[0] - search_area_size[1] // 2, delta[1] - search_area_size[1] // 2)
|
||||||
|
delta_x, delta_y = delta
|
||||||
|
|
||||||
|
rgb_cross_area = self.get_cross_area(rgb_bin, delta_x, delta_y)
|
||||||
|
spce_cross_area = self.get_cross_area(spec_bin, -delta_x, -delta_y)
|
||||||
|
|
||||||
|
human_word = "SPEC is " + str(abs(delta_x)) + " pixels "
|
||||||
|
human_word += 'after' if delta_x >= 0 else ' before '
|
||||||
|
human_word += "RGB and " + str(abs(delta_y)) + " pixels "
|
||||||
|
human_word += "right " if delta_y >= 0 else "left "
|
||||||
|
human_word += "the RGB"
|
||||||
|
|
||||||
|
fig, axs = plt.subplots(3, 1)
|
||||||
|
axs[0].imshow(rgb_img)
|
||||||
|
axs[0].set_title("RGB img")
|
||||||
|
axs[1].imshow(spec_img)
|
||||||
|
axs[1].set_title("spec img")
|
||||||
|
axs[2].imshow(rgb_cross_area & spce_cross_area)
|
||||||
|
axs[2].set_title("cross part")
|
||||||
|
plt.suptitle(human_word)
|
||||||
|
plt.show()
|
||||||
|
|
||||||
|
print(human_word)
|
||||||
|
return delta
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def get_cross_area(img_bin, delta_x, delta_y):
|
||||||
|
if delta_x >= 0:
|
||||||
|
cross_area = img_bin[delta_x:, :]
|
||||||
|
else:
|
||||||
|
cross_area = img_bin[:delta_x, :]
|
||||||
|
if delta_y >= 0:
|
||||||
|
cross_area = cross_area[:, delta_y:]
|
||||||
|
else:
|
||||||
|
cross_area = cross_area[:, :delta_y]
|
||||||
|
return cross_area
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == '__main__':
|
||||||
testor = TestMain()
|
import argparse
|
||||||
testor.pony_run(test_path=r'E:\zhouchao\728-tobacco\728-1-3',
|
parser = argparse.ArgumentParser(description='Run image test or image_file')
|
||||||
test_rgb=True, test_spectra=True)
|
parser.add_argument('path', default=r'E:\zhouchao\8.4\zazhi', help='测试文件或文件夹')
|
||||||
|
parser.add_argument('-test_rgb', default=True, action='store_false', help='是否测试RGB图')
|
||||||
|
parser.add_argument('-test_spec', default=True, action='store_false', help='是否测试光谱图')
|
||||||
|
parser.add_argument('-get_delta', default=False, action='store_true', help='是否进行误差计算')
|
||||||
|
parser.add_argument('-convert_dir', default=None, help='是否将c语言采集的buffer进行转换')
|
||||||
|
parser.add_argument('-s', '--silent', default=False, action='store_true', help='是否显示')
|
||||||
|
args = parser.parse_args()
|
||||||
|
# file path check
|
||||||
|
if args.convert_dir is not None:
|
||||||
|
if os.path.exists(args.convert_dir):
|
||||||
|
if not os.path.isdir(args.convert_dir):
|
||||||
|
raise TypeError("转换文件夹需要是个文件夹")
|
||||||
|
else:
|
||||||
|
if os.path.abspath(args.path) == os.path.abspath(args.convert_dir):
|
||||||
|
print("警告!您的输出文件夹和输入文件夹用了同一个位置")
|
||||||
|
else:
|
||||||
|
print(f"已创建需要存放转换文件的文件夹 {args.convert_dir}")
|
||||||
|
os.makedirs(args.convert_dir, mode=0o777, exist_ok=False)
|
||||||
|
tester = TestMain()
|
||||||
|
tester.pony_run(test_path=args.path, test_rgb=args.test_rgb, test_spectra=args.test_spec,
|
||||||
|
get_delta=args.get_delta, convert_dir=args.convert_dir, silent=args.silent)
|
||||||
|
|||||||
@ -15,12 +15,14 @@ from scipy.ndimage import binary_dilation
|
|||||||
from sklearn.tree import DecisionTreeClassifier
|
from sklearn.tree import DecisionTreeClassifier
|
||||||
from sklearn.metrics import classification_report
|
from sklearn.metrics import classification_report
|
||||||
from sklearn.model_selection import train_test_split
|
from sklearn.model_selection import train_test_split
|
||||||
|
import time
|
||||||
|
|
||||||
from config import Config
|
from config import Config
|
||||||
|
from detector import SugarDetect
|
||||||
from utils import lab_scatter, read_labeled_img, size_threshold
|
from utils import lab_scatter, read_labeled_img, size_threshold
|
||||||
|
|
||||||
|
|
||||||
deploy = True
|
deploy = False
|
||||||
if not deploy:
|
if not deploy:
|
||||||
print("Training env")
|
print("Training env")
|
||||||
from tqdm import tqdm
|
from tqdm import tqdm
|
||||||
@ -255,12 +257,12 @@ class ManualTree:
|
|||||||
|
|
||||||
# 机器学习像素模型类
|
# 机器学习像素模型类
|
||||||
class PixelModelML:
|
class PixelModelML:
|
||||||
def __init__(self, pixel_model_path):
|
def __init__(self, pixel_model_path=None):
|
||||||
with open(pixel_model_path, "rb") as f:
|
with open(pixel_model_path, "rb") as f:
|
||||||
self.dt = pickle.load(f)
|
self.dt = pickle.load(f)
|
||||||
|
|
||||||
def predict(self, feature):
|
def predict(self, feature):
|
||||||
pixel_result_array = self.dt.predict(feature)
|
pixel_result_array = self.dt.predict_bin(feature)
|
||||||
return pixel_result_array
|
return pixel_result_array
|
||||||
|
|
||||||
|
|
||||||
@ -306,10 +308,13 @@ class BlkModel:
|
|||||||
|
|
||||||
|
|
||||||
class RgbDetector(Detector):
|
class RgbDetector(Detector):
|
||||||
def __init__(self, tobacco_model_path, background_model_path):
|
def __init__(self, tobacco_model_path, background_model_path, ai_path):
|
||||||
self.background_detector = None
|
self.background_detector = None
|
||||||
self.tobacco_detector = None
|
self.tobacco_detector = None
|
||||||
self.load(tobacco_model_path, background_model_path)
|
self.load(tobacco_model_path, background_model_path)
|
||||||
|
self.ai_path = ai_path
|
||||||
|
if ai_path is not None:
|
||||||
|
self.ai_detector = SugarDetect(model_path=ai_path)
|
||||||
|
|
||||||
def predict(self, rgb_data):
|
def predict(self, rgb_data):
|
||||||
rgb_data = self.tobacco_detector.pretreatment(rgb_data) # resize to the required size
|
rgb_data = self.tobacco_detector.pretreatment(rgb_data) # resize to the required size
|
||||||
@ -320,6 +325,22 @@ class RgbDetector(Detector):
|
|||||||
non_tobacco_or_background = 1 - (background | tobacco_d) # 既非烟梗也非背景的区域
|
non_tobacco_or_background = 1 - (background | tobacco_d) # 既非烟梗也非背景的区域
|
||||||
rgb_predict_result = high_s | non_tobacco_or_background # 高饱和度区域或者是双非区域都是杂质
|
rgb_predict_result = high_s | non_tobacco_or_background # 高饱和度区域或者是双非区域都是杂质
|
||||||
mask_rgb = size_threshold(rgb_predict_result, Config.blk_size, Config.rgb_size_threshold) # 杂质大小限制,超过大小的才打
|
mask_rgb = size_threshold(rgb_predict_result, Config.blk_size, Config.rgb_size_threshold) # 杂质大小限制,超过大小的才打
|
||||||
|
if self.ai_path is not None:
|
||||||
|
mask_ai = self.ai_detector.detect(rgb_data, Config.ai_conf_threshold)
|
||||||
|
mask_ai = cv2.resize(mask_ai, dsize=(mask_rgb.shape[1], mask_rgb.shape[0]))
|
||||||
|
mask_rgb = mask_ai | mask_rgb
|
||||||
|
# # 测试时间
|
||||||
|
# start = time.time()
|
||||||
|
# 转换为lab,提取a通道,识别绿色杂质
|
||||||
|
lab_a = cv2.cvtColor(rgb_data, cv2.COLOR_RGB2LAB)[..., 1] < Config.threshold_a
|
||||||
|
# 转换为lab,提取b通道,识别蓝色杂质
|
||||||
|
lab_b = cv2.cvtColor(rgb_data, cv2.COLOR_RGB2LAB)[..., 2] < Config.threshold_b
|
||||||
|
lab_predict_result = lab_a | lab_b
|
||||||
|
mask_lab = size_threshold(lab_predict_result, Config.blk_size, Config.lab_size_threshold)
|
||||||
|
mask_rgb = mask_rgb.astype(np.uint8) | mask_lab.astype(np.uint8)
|
||||||
|
# # 测试时间
|
||||||
|
# end = time.time()
|
||||||
|
# print("lab time: ", end - start)
|
||||||
return mask_rgb
|
return mask_rgb
|
||||||
|
|
||||||
def load(self, tobacco_model_path, background_model_path):
|
def load(self, tobacco_model_path, background_model_path):
|
||||||
@ -339,16 +360,29 @@ class SpecDetector(Detector):
|
|||||||
self.blk_model = None
|
self.blk_model = None
|
||||||
self.pixel_model_ml = None
|
self.pixel_model_ml = None
|
||||||
self.load(blk_model_path, pixel_model_path)
|
self.load(blk_model_path, pixel_model_path)
|
||||||
|
self.spare_part = np.zeros((Config.blk_size//2, Config.nCols))
|
||||||
|
|
||||||
def load(self, blk_model_path, pixel_model_path):
|
def load(self, blk_model_path, pixel_model_path):
|
||||||
self.pixel_model_ml = PixelModelML(pixel_model_path)
|
self.pixel_model_ml = PixelModelML(pixel_model_path)
|
||||||
self.blk_model = BlkModel(blk_model_path)
|
self.blk_model = BlkModel(blk_model_path)
|
||||||
|
|
||||||
def predict(self, img_data):
|
def predict(self, img_data: np.ndarray, save_part: bool = False) -> np.ndarray:
|
||||||
pixel_predict_result = self.pixel_predict_ml_dilation(data=img_data, iteration=1)
|
pixel_predict_result = self.pixel_predict_ml_dilation(data=img_data, iteration=1)
|
||||||
blk_predict_result = self.blk_predict(data=img_data)
|
blk_predict_result = self.blk_predict(data=img_data)
|
||||||
mask = (pixel_predict_result & blk_predict_result).astype(np.uint8)
|
mask = (pixel_predict_result & blk_predict_result).astype(np.uint8)
|
||||||
mask = size_threshold(mask, Config.blk_size, Config.spec_size_threshold)
|
spec_cv = np.clip(img_data[..., [21, 3, 0]], a_min=0, a_max=1) * 255
|
||||||
|
spec_cv = spec_cv.astype(np.uint8)
|
||||||
|
# spec转lab 提取a通道,识别绿色杂质
|
||||||
|
lab_a = cv2.cvtColor(spec_cv, cv2.COLOR_RGB2LAB)[..., 1] < Config.s_threshold_a
|
||||||
|
# spec转lab 提取b通道,识别蓝色杂质
|
||||||
|
lab_b = cv2.cvtColor(spec_cv, cv2.COLOR_RGB2LAB)[..., 2] < Config.s_threshold_b
|
||||||
|
lab_predict_result = lab_a | lab_b
|
||||||
|
mask_lab = size_threshold(lab_predict_result, Config.blk_size, Config.lab_size_threshold)
|
||||||
|
|
||||||
|
if save_part:
|
||||||
|
self.spare_part = mask[-(Config.blk_size//2):, :]
|
||||||
|
mask = size_threshold(mask, Config.blk_size, Config.spec_size_threshold, self.spare_part)
|
||||||
|
mask = mask.astype(np.uint8) | mask_lab.astype(np.uint8)
|
||||||
return mask
|
return mask
|
||||||
|
|
||||||
def save(self, *args, **kwargs):
|
def save(self, *args, **kwargs):
|
||||||
@ -409,7 +443,7 @@ class SpecDetector(Detector):
|
|||||||
if x_yellow.shape[0] == 0:
|
if x_yellow.shape[0] == 0:
|
||||||
return non_yellow_things
|
return non_yellow_things
|
||||||
else:
|
else:
|
||||||
tobacco = self.pixel_model_ml.predict(x_yellow[..., Config.green_bands]) > 0.5
|
tobacco = self.pixel_model_ml.predict(x_yellow) < 0.5
|
||||||
|
|
||||||
non_yellow_things[yellow_things] = ~tobacco
|
non_yellow_things[yellow_things] = ~tobacco
|
||||||
# 杂质mask中将背景赋值为0,将杂质赋值为1
|
# 杂质mask中将背景赋值为0,将杂质赋值为1
|
||||||
@ -436,16 +470,26 @@ class SpecDetector(Detector):
|
|||||||
return blk_result_array
|
return blk_result_array
|
||||||
|
|
||||||
|
|
||||||
|
class DecisionTree(DecisionTreeClassifier):
|
||||||
|
def predict_bin(self, feature):
|
||||||
|
res = self.predict(feature)
|
||||||
|
res[res <= 1] = 0
|
||||||
|
res[res > 1] = 1
|
||||||
|
return res
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == '__main__':
|
||||||
data_dir = "data/dataset"
|
import os
|
||||||
|
data_dir = os.path.join('E:\Tobacco\data', 'dataset')
|
||||||
color_dict = {(0, 0, 255): "yangeng"}
|
color_dict = {(0, 0, 255): "yangeng"}
|
||||||
dataset = read_labeled_img(data_dir, color_dict=color_dict, is_ps_color_space=False)
|
dataset = read_labeled_img(data_dir, color_dict=color_dict, is_ps_color_space=False)
|
||||||
ground_truth = dataset['yangeng']
|
ground_truth = dataset['yangeng']
|
||||||
detector = AnonymousColorDetector(file_path='models/dt_2022-07-19_14-38.model')
|
detector = AnonymousColorDetector(file_path=r'E:\Tobacco\weights\tobacco_dt_2022-08-05_10-38.model')
|
||||||
# x = np.array([[10, 30, 20], [10, 35, 25], [10, 35, 36]])
|
# x = np.array([[10, 30, 20], [10, 35, 25], [10, 35, 36]])
|
||||||
boundary = np.array([0, 0, 0, 255, 255, 255])
|
boundary = np.array([0, 0, 0, 255, 255, 255])
|
||||||
# detector.fit(x, world_boundary, threshold=5, negative_sample_size=2000)
|
# detector.fit(x, world_boundary, threshold=5, negative_sample_size=2000)
|
||||||
detector.visualize(boundary, sample_size=50000, class_max_num=5000, ground_truth=ground_truth)
|
detector.visualize(boundary, sample_size=500000, class_max_num=5000, ground_truth=ground_truth, inside_alpha=0.3,
|
||||||
|
outside_alpha=0.01)
|
||||||
temp = scipy.io.loadmat('data/dataset_2022-07-19_11-35.mat')
|
temp = scipy.io.loadmat('data/dataset_2022-07-19_11-35.mat')
|
||||||
x, y = temp['x'], temp['y']
|
x, y = temp['x'], temp['y']
|
||||||
dataset = {'inside': x[y.ravel() == 1, :], "outside": x[y.ravel() == 0, :]}
|
dataset = {'inside': x[y.ravel() == 1, :], "outside": x[y.ravel() == 0, :]}
|
||||||
677
models/common.py
Normal file
677
models/common.py
Normal file
@ -0,0 +1,677 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Common modules
|
||||||
|
"""
|
||||||
|
|
||||||
|
import json
|
||||||
|
import math
|
||||||
|
import platform
|
||||||
|
import warnings
|
||||||
|
from collections import OrderedDict, namedtuple
|
||||||
|
from copy import copy
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
import requests
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import yaml
|
||||||
|
from PIL import Image
|
||||||
|
from torch.cuda import amp
|
||||||
|
|
||||||
|
from utils.datasets import exif_transpose, letterbox
|
||||||
|
from utils.general import (LOGGER, check_requirements, check_suffix, check_version, colorstr, increment_path,
|
||||||
|
make_divisible, non_max_suppression, scale_coords, xywh2xyxy, xyxy2xywh)
|
||||||
|
from utils.plots import Annotator, colors, save_one_box
|
||||||
|
from utils.torch_utils import copy_attr, time_sync
|
||||||
|
|
||||||
|
|
||||||
|
def autopad(k, p=None): # kernel, padding
|
||||||
|
# Pad to 'same'
|
||||||
|
if p is None:
|
||||||
|
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
|
||||||
|
return p
|
||||||
|
|
||||||
|
|
||||||
|
class Conv(nn.Module):
|
||||||
|
# Standard convolution
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
||||||
|
super().__init__()
|
||||||
|
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
|
||||||
|
self.bn = nn.BatchNorm2d(c2)
|
||||||
|
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.act(self.bn(self.conv(x)))
|
||||||
|
|
||||||
|
def forward_fuse(self, x):
|
||||||
|
return self.act(self.conv(x))
|
||||||
|
|
||||||
|
|
||||||
|
class DWConv(Conv):
|
||||||
|
# Depth-wise convolution class
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
||||||
|
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
|
||||||
|
|
||||||
|
|
||||||
|
class TransformerLayer(nn.Module):
|
||||||
|
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
|
||||||
|
def __init__(self, c, num_heads):
|
||||||
|
super().__init__()
|
||||||
|
self.q = nn.Linear(c, c, bias=False)
|
||||||
|
self.k = nn.Linear(c, c, bias=False)
|
||||||
|
self.v = nn.Linear(c, c, bias=False)
|
||||||
|
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
|
||||||
|
self.fc1 = nn.Linear(c, c, bias=False)
|
||||||
|
self.fc2 = nn.Linear(c, c, bias=False)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
|
||||||
|
x = self.fc2(self.fc1(x)) + x
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
class TransformerBlock(nn.Module):
|
||||||
|
# Vision Transformer https://arxiv.org/abs/2010.11929
|
||||||
|
def __init__(self, c1, c2, num_heads, num_layers):
|
||||||
|
super().__init__()
|
||||||
|
self.conv = None
|
||||||
|
if c1 != c2:
|
||||||
|
self.conv = Conv(c1, c2)
|
||||||
|
self.linear = nn.Linear(c2, c2) # learnable position embedding
|
||||||
|
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
|
||||||
|
self.c2 = c2
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
if self.conv is not None:
|
||||||
|
x = self.conv(x)
|
||||||
|
b, _, w, h = x.shape
|
||||||
|
p = x.flatten(2).permute(2, 0, 1)
|
||||||
|
return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
|
||||||
|
|
||||||
|
|
||||||
|
class Bottleneck(nn.Module):
|
||||||
|
# Standard bottleneck
|
||||||
|
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, 1, 1)
|
||||||
|
self.cv2 = Conv(c_, c2, 3, 1, g=g)
|
||||||
|
self.add = shortcut and c1 == c2
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
|
||||||
|
|
||||||
|
|
||||||
|
class BottleneckCSP(nn.Module):
|
||||||
|
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
|
||||||
|
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, 1, 1)
|
||||||
|
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
|
||||||
|
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
|
||||||
|
self.cv4 = Conv(2 * c_, c2, 1, 1)
|
||||||
|
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
|
||||||
|
self.act = nn.SiLU()
|
||||||
|
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
y1 = self.cv3(self.m(self.cv1(x)))
|
||||||
|
y2 = self.cv2(x)
|
||||||
|
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
|
||||||
|
|
||||||
|
|
||||||
|
class C3(nn.Module):
|
||||||
|
# CSP Bottleneck with 3 convolutions
|
||||||
|
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, 1, 1)
|
||||||
|
self.cv2 = Conv(c1, c_, 1, 1)
|
||||||
|
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
|
||||||
|
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
|
||||||
|
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
|
||||||
|
|
||||||
|
|
||||||
|
class C3TR(C3):
|
||||||
|
# C3 module with TransformerBlock()
|
||||||
|
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
|
||||||
|
super().__init__(c1, c2, n, shortcut, g, e)
|
||||||
|
c_ = int(c2 * e)
|
||||||
|
self.m = TransformerBlock(c_, c_, 4, n)
|
||||||
|
|
||||||
|
|
||||||
|
class C3SPP(C3):
|
||||||
|
# C3 module with SPP()
|
||||||
|
def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
|
||||||
|
super().__init__(c1, c2, n, shortcut, g, e)
|
||||||
|
c_ = int(c2 * e)
|
||||||
|
self.m = SPP(c_, c_, k)
|
||||||
|
|
||||||
|
|
||||||
|
class C3Ghost(C3):
|
||||||
|
# C3 module with GhostBottleneck()
|
||||||
|
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
|
||||||
|
super().__init__(c1, c2, n, shortcut, g, e)
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
|
||||||
|
|
||||||
|
|
||||||
|
class SPP(nn.Module):
|
||||||
|
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
|
||||||
|
def __init__(self, c1, c2, k=(5, 9, 13)):
|
||||||
|
super().__init__()
|
||||||
|
c_ = c1 // 2 # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, 1, 1)
|
||||||
|
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
|
||||||
|
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.cv1(x)
|
||||||
|
with warnings.catch_warnings():
|
||||||
|
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
|
||||||
|
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
|
||||||
|
|
||||||
|
|
||||||
|
class SPPF(nn.Module):
|
||||||
|
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
|
||||||
|
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
|
||||||
|
super().__init__()
|
||||||
|
c_ = c1 // 2 # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, 1, 1)
|
||||||
|
self.cv2 = Conv(c_ * 4, c2, 1, 1)
|
||||||
|
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
x = self.cv1(x)
|
||||||
|
with warnings.catch_warnings():
|
||||||
|
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
|
||||||
|
y1 = self.m(x)
|
||||||
|
y2 = self.m(y1)
|
||||||
|
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
|
||||||
|
|
||||||
|
|
||||||
|
class Focus(nn.Module):
|
||||||
|
# Focus wh information into c-space
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
|
||||||
|
super().__init__()
|
||||||
|
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
|
||||||
|
# self.contract = Contract(gain=2)
|
||||||
|
|
||||||
|
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
|
||||||
|
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
|
||||||
|
# return self.conv(self.contract(x))
|
||||||
|
|
||||||
|
|
||||||
|
class GhostConv(nn.Module):
|
||||||
|
# Ghost Convolution https://github.com/huawei-noah/ghostnet
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
|
||||||
|
super().__init__()
|
||||||
|
c_ = c2 // 2 # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, k, s, None, g, act)
|
||||||
|
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
y = self.cv1(x)
|
||||||
|
return torch.cat([y, self.cv2(y)], 1)
|
||||||
|
|
||||||
|
|
||||||
|
class GhostBottleneck(nn.Module):
|
||||||
|
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
|
||||||
|
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
|
||||||
|
super().__init__()
|
||||||
|
c_ = c2 // 2
|
||||||
|
self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pw
|
||||||
|
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
|
||||||
|
GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
|
||||||
|
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
|
||||||
|
Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.conv(x) + self.shortcut(x)
|
||||||
|
|
||||||
|
|
||||||
|
class Contract(nn.Module):
|
||||||
|
# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
|
||||||
|
def __init__(self, gain=2):
|
||||||
|
super().__init__()
|
||||||
|
self.gain = gain
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
|
||||||
|
s = self.gain
|
||||||
|
x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
|
||||||
|
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
|
||||||
|
return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
|
||||||
|
|
||||||
|
|
||||||
|
class Expand(nn.Module):
|
||||||
|
# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
|
||||||
|
def __init__(self, gain=2):
|
||||||
|
super().__init__()
|
||||||
|
self.gain = gain
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
|
||||||
|
s = self.gain
|
||||||
|
x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
|
||||||
|
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
|
||||||
|
return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
|
||||||
|
|
||||||
|
|
||||||
|
class Concat(nn.Module):
|
||||||
|
# Concatenate a list of tensors along dimension
|
||||||
|
def __init__(self, dimension=1):
|
||||||
|
super().__init__()
|
||||||
|
self.d = dimension
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return torch.cat(x, self.d)
|
||||||
|
|
||||||
|
|
||||||
|
class DetectMultiBackend(nn.Module):
|
||||||
|
# YOLOv5 MultiBackend class for python inference on various backends
|
||||||
|
def __init__(self, weights='yolov5s.pt', device=None, dnn=False, data=None):
|
||||||
|
# Usage:
|
||||||
|
# PyTorch: weights = *.pt
|
||||||
|
# TorchScript: *.torchscript
|
||||||
|
# ONNX Runtime: *.onnx
|
||||||
|
# ONNX OpenCV DNN: *.onnx with --dnn
|
||||||
|
# OpenVINO: *.xml
|
||||||
|
# CoreML: *.mlmodel
|
||||||
|
# TensorRT: *.engine
|
||||||
|
# TensorFlow SavedModel: *_saved_model
|
||||||
|
# TensorFlow GraphDef: *.pb
|
||||||
|
# TensorFlow Lite: *.tflite
|
||||||
|
# TensorFlow Edge TPU: *_edgetpu.tflite
|
||||||
|
from models.experimental import attempt_download, attempt_load # scoped to avoid circular import
|
||||||
|
|
||||||
|
super().__init__()
|
||||||
|
w = str(weights[0] if isinstance(weights, list) else weights)
|
||||||
|
pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs = self.model_type(w) # get backend
|
||||||
|
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
|
||||||
|
w = attempt_download(w) # download if not local
|
||||||
|
if data: # data.yaml path (optional)
|
||||||
|
with open(data, errors='ignore') as f:
|
||||||
|
names = yaml.safe_load(f)['names'] # class names
|
||||||
|
|
||||||
|
if pt: # PyTorch
|
||||||
|
model = attempt_load(weights if isinstance(weights, list) else w, map_location=device)
|
||||||
|
stride = max(int(model.stride.max()), 32) # model stride
|
||||||
|
names = model.module.names if hasattr(model, 'module') else model.names # get class names
|
||||||
|
self.model = model # explicitly assign for to(), cpu(), cuda(), half()
|
||||||
|
elif jit: # TorchScript
|
||||||
|
LOGGER.info(f'Loading {w} for TorchScript inference...')
|
||||||
|
extra_files = {'config.txt': ''} # model metadata
|
||||||
|
model = torch.jit.load(w, _extra_files=extra_files)
|
||||||
|
if extra_files['config.txt']:
|
||||||
|
d = json.loads(extra_files['config.txt']) # extra_files dict
|
||||||
|
stride, names = int(d['stride']), d['names']
|
||||||
|
elif dnn: # ONNX OpenCV DNN
|
||||||
|
LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
|
||||||
|
check_requirements(('opencv-python>=4.5.4',))
|
||||||
|
net = cv2.dnn.readNetFromONNX(w)
|
||||||
|
elif onnx: # ONNX Runtime
|
||||||
|
LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
|
||||||
|
cuda = torch.cuda.is_available()
|
||||||
|
check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
|
||||||
|
import onnxruntime
|
||||||
|
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
|
||||||
|
session = onnxruntime.InferenceSession(w, providers=providers)
|
||||||
|
elif xml: # OpenVINO
|
||||||
|
LOGGER.info(f'Loading {w} for OpenVINO inference...')
|
||||||
|
check_requirements(('openvino-dev',)) # requires openvino-dev: https://pypi.org/project/openvino-dev/
|
||||||
|
import openvino.inference_engine as ie
|
||||||
|
core = ie.IECore()
|
||||||
|
if not Path(w).is_file(): # if not *.xml
|
||||||
|
w = next(Path(w).glob('*.xml')) # get *.xml file from *_openvino_model dir
|
||||||
|
network = core.read_network(model=w, weights=Path(w).with_suffix('.bin')) # *.xml, *.bin paths
|
||||||
|
executable_network = core.load_network(network, device_name='CPU', num_requests=1)
|
||||||
|
elif engine: # TensorRT
|
||||||
|
LOGGER.info(f'Loading {w} for TensorRT inference...')
|
||||||
|
import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
|
||||||
|
check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
|
||||||
|
Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
|
||||||
|
logger = trt.Logger(trt.Logger.INFO)
|
||||||
|
with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
|
||||||
|
model = runtime.deserialize_cuda_engine(f.read())
|
||||||
|
bindings = OrderedDict()
|
||||||
|
for index in range(model.num_bindings):
|
||||||
|
name = model.get_binding_name(index)
|
||||||
|
dtype = trt.nptype(model.get_binding_dtype(index))
|
||||||
|
shape = tuple(model.get_binding_shape(index))
|
||||||
|
data = torch.from_numpy(np.empty(shape, dtype=np.dtype(dtype))).to(device)
|
||||||
|
bindings[name] = Binding(name, dtype, shape, data, int(data.data_ptr()))
|
||||||
|
binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
|
||||||
|
context = model.create_execution_context()
|
||||||
|
batch_size = bindings['images'].shape[0]
|
||||||
|
elif coreml: # CoreML
|
||||||
|
LOGGER.info(f'Loading {w} for CoreML inference...')
|
||||||
|
import coremltools as ct
|
||||||
|
model = ct.models.MLModel(w)
|
||||||
|
else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
|
||||||
|
if saved_model: # SavedModel
|
||||||
|
LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
|
||||||
|
import tensorflow as tf
|
||||||
|
keras = False # assume TF1 saved_model
|
||||||
|
model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
|
||||||
|
elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
|
||||||
|
LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
|
||||||
|
import tensorflow as tf
|
||||||
|
|
||||||
|
def wrap_frozen_graph(gd, inputs, outputs):
|
||||||
|
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped
|
||||||
|
ge = x.graph.as_graph_element
|
||||||
|
return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
|
||||||
|
|
||||||
|
gd = tf.Graph().as_graph_def() # graph_def
|
||||||
|
gd.ParseFromString(open(w, 'rb').read())
|
||||||
|
frozen_func = wrap_frozen_graph(gd, inputs="x:0", outputs="Identity:0")
|
||||||
|
elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
|
||||||
|
try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
|
||||||
|
from tflite_runtime.interpreter import Interpreter, load_delegate
|
||||||
|
except ImportError:
|
||||||
|
import tensorflow as tf
|
||||||
|
Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate,
|
||||||
|
if edgetpu: # Edge TPU https://coral.ai/software/#edgetpu-runtime
|
||||||
|
LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
|
||||||
|
delegate = {'Linux': 'libedgetpu.so.1',
|
||||||
|
'Darwin': 'libedgetpu.1.dylib',
|
||||||
|
'Windows': 'edgetpu.dll'}[platform.system()]
|
||||||
|
interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
|
||||||
|
else: # Lite
|
||||||
|
LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
|
||||||
|
interpreter = Interpreter(model_path=w) # load TFLite model
|
||||||
|
interpreter.allocate_tensors() # allocate
|
||||||
|
input_details = interpreter.get_input_details() # inputs
|
||||||
|
output_details = interpreter.get_output_details() # outputs
|
||||||
|
elif tfjs:
|
||||||
|
raise Exception('ERROR: YOLOv5 TF.js inference is not supported')
|
||||||
|
self.__dict__.update(locals()) # assign all variables to self
|
||||||
|
|
||||||
|
def forward(self, im, augment=False, visualize=False, val=False):
|
||||||
|
# YOLOv5 MultiBackend inference
|
||||||
|
b, ch, h, w = im.shape # batch, channel, height, width
|
||||||
|
if self.pt or self.jit: # PyTorch
|
||||||
|
y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)
|
||||||
|
return y if val else y[0]
|
||||||
|
elif self.dnn: # ONNX OpenCV DNN
|
||||||
|
im = im.cpu().numpy() # torch to numpy
|
||||||
|
self.net.setInput(im)
|
||||||
|
y = self.net.forward()
|
||||||
|
elif self.onnx: # ONNX Runtime
|
||||||
|
im = im.cpu().numpy() # torch to numpy
|
||||||
|
y = self.session.run([self.session.get_outputs()[0].name], {self.session.get_inputs()[0].name: im})[0]
|
||||||
|
elif self.xml: # OpenVINO
|
||||||
|
im = im.cpu().numpy() # FP32
|
||||||
|
desc = self.ie.TensorDesc(precision='FP32', dims=im.shape, layout='NCHW') # Tensor Description
|
||||||
|
request = self.executable_network.requests[0] # inference request
|
||||||
|
request.set_blob(blob_name='images', blob=self.ie.Blob(desc, im)) # name=next(iter(request.input_blobs))
|
||||||
|
request.infer()
|
||||||
|
y = request.output_blobs['output'].buffer # name=next(iter(request.output_blobs))
|
||||||
|
elif self.engine: # TensorRT
|
||||||
|
assert im.shape == self.bindings['images'].shape, (im.shape, self.bindings['images'].shape)
|
||||||
|
self.binding_addrs['images'] = int(im.data_ptr())
|
||||||
|
self.context.execute_v2(list(self.binding_addrs.values()))
|
||||||
|
y = self.bindings['output'].data
|
||||||
|
elif self.coreml: # CoreML
|
||||||
|
im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
|
||||||
|
im = Image.fromarray((im[0] * 255).astype('uint8'))
|
||||||
|
# im = im.resize((192, 320), Image.ANTIALIAS)
|
||||||
|
y = self.model.predict({'image': im}) # coordinates are xywh normalized
|
||||||
|
if 'confidence' in y:
|
||||||
|
box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
|
||||||
|
conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
|
||||||
|
y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
|
||||||
|
else:
|
||||||
|
k = 'var_' + str(sorted(int(k.replace('var_', '')) for k in y)[-1]) # output key
|
||||||
|
y = y[k] # output
|
||||||
|
else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
|
||||||
|
im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
|
||||||
|
if self.saved_model: # SavedModel
|
||||||
|
y = (self.model(im, training=False) if self.keras else self.model(im)[0]).numpy()
|
||||||
|
elif self.pb: # GraphDef
|
||||||
|
y = self.frozen_func(x=self.tf.constant(im)).numpy()
|
||||||
|
else: # Lite or Edge TPU
|
||||||
|
input, output = self.input_details[0], self.output_details[0]
|
||||||
|
int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
|
||||||
|
if int8:
|
||||||
|
scale, zero_point = input['quantization']
|
||||||
|
im = (im / scale + zero_point).astype(np.uint8) # de-scale
|
||||||
|
self.interpreter.set_tensor(input['index'], im)
|
||||||
|
self.interpreter.invoke()
|
||||||
|
y = self.interpreter.get_tensor(output['index'])
|
||||||
|
if int8:
|
||||||
|
scale, zero_point = output['quantization']
|
||||||
|
y = (y.astype(np.float32) - zero_point) * scale # re-scale
|
||||||
|
y[..., :4] *= [w, h, w, h] # xywh normalized to pixels
|
||||||
|
|
||||||
|
y = torch.tensor(y) if isinstance(y, np.ndarray) else y
|
||||||
|
return (y, []) if val else y
|
||||||
|
|
||||||
|
def warmup(self, imgsz=(1, 3, 640, 640), half=False):
|
||||||
|
# Warmup model by running inference once
|
||||||
|
if self.pt or self.jit or self.onnx or self.engine: # warmup types
|
||||||
|
if isinstance(self.device, torch.device) and self.device.type != 'cpu': # only warmup GPU models
|
||||||
|
im = torch.zeros(*imgsz).to(self.device).type(torch.half if half else torch.float) # input image
|
||||||
|
self.forward(im) # warmup
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def model_type(p='path/to/model.pt'):
|
||||||
|
# Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
|
||||||
|
from export import export_formats
|
||||||
|
suffixes = list(export_formats().Suffix) + ['.xml'] # export suffixes
|
||||||
|
check_suffix(p, suffixes) # checks
|
||||||
|
p = Path(p).name # eliminate trailing separators
|
||||||
|
pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, xml2 = (s in p for s in suffixes)
|
||||||
|
xml |= xml2 # *_openvino_model or *.xml
|
||||||
|
tflite &= not edgetpu # *.tflite
|
||||||
|
return pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs
|
||||||
|
|
||||||
|
|
||||||
|
class AutoShape(nn.Module):
|
||||||
|
# YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
|
||||||
|
conf = 0.25 # NMS confidence threshold
|
||||||
|
iou = 0.45 # NMS IoU threshold
|
||||||
|
agnostic = False # NMS class-agnostic
|
||||||
|
multi_label = False # NMS multiple labels per box
|
||||||
|
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
|
||||||
|
max_det = 1000 # maximum number of detections per image
|
||||||
|
amp = False # Automatic Mixed Precision (AMP) inference
|
||||||
|
|
||||||
|
def __init__(self, model):
|
||||||
|
super().__init__()
|
||||||
|
LOGGER.info('Adding AutoShape... ')
|
||||||
|
copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributes
|
||||||
|
self.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instance
|
||||||
|
self.pt = not self.dmb or model.pt # PyTorch model
|
||||||
|
self.model = model.eval()
|
||||||
|
|
||||||
|
def _apply(self, fn):
|
||||||
|
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
|
||||||
|
self = super()._apply(fn)
|
||||||
|
if self.pt:
|
||||||
|
m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
|
||||||
|
m.stride = fn(m.stride)
|
||||||
|
m.grid = list(map(fn, m.grid))
|
||||||
|
if isinstance(m.anchor_grid, list):
|
||||||
|
m.anchor_grid = list(map(fn, m.anchor_grid))
|
||||||
|
return self
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def forward(self, imgs, size=640, augment=False, profile=False):
|
||||||
|
# Inference from various sources. For height=640, width=1280, RGB images example inputs are:
|
||||||
|
# file: imgs = 'data/images/zidane.jpg' # str or PosixPath
|
||||||
|
# URI: = 'https://ultralytics.com/images/zidane.jpg'
|
||||||
|
# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
|
||||||
|
# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
|
||||||
|
# numpy: = np.zeros((640,1280,3)) # HWC
|
||||||
|
# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
|
||||||
|
# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
|
||||||
|
|
||||||
|
t = [time_sync()]
|
||||||
|
p = next(self.model.parameters()) if self.pt else torch.zeros(1) # for device and type
|
||||||
|
autocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inference
|
||||||
|
if isinstance(imgs, torch.Tensor): # torch
|
||||||
|
with amp.autocast(enabled=autocast):
|
||||||
|
return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
|
||||||
|
|
||||||
|
# Pre-process
|
||||||
|
n, imgs = (len(imgs), imgs) if isinstance(imgs, list) else (1, [imgs]) # number of images, list of images
|
||||||
|
shape0, shape1, files = [], [], [] # image and inference shapes, filenames
|
||||||
|
for i, im in enumerate(imgs):
|
||||||
|
f = f'image{i}' # filename
|
||||||
|
if isinstance(im, (str, Path)): # filename or uri
|
||||||
|
im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
|
||||||
|
im = np.asarray(exif_transpose(im))
|
||||||
|
elif isinstance(im, Image.Image): # PIL Image
|
||||||
|
im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
|
||||||
|
files.append(Path(f).with_suffix('.jpg').name)
|
||||||
|
if im.shape[0] < 5: # image in CHW
|
||||||
|
im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
|
||||||
|
im = im[..., :3] if im.ndim == 3 else np.tile(im[..., None], 3) # enforce 3ch input
|
||||||
|
s = im.shape[:2] # HWC
|
||||||
|
shape0.append(s) # image shape
|
||||||
|
g = (size / max(s)) # gain
|
||||||
|
shape1.append([y * g for y in s])
|
||||||
|
imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
|
||||||
|
shape1 = [make_divisible(x, self.stride) for x in np.stack(shape1, 0).max(0)] # inference shape
|
||||||
|
x = [letterbox(im, new_shape=shape1 if self.pt else size, auto=False)[0] for im in imgs] # pad
|
||||||
|
x = np.stack(x, 0) if n > 1 else x[0][None] # stack
|
||||||
|
x = np.ascontiguousarray(x.transpose((0, 3, 1, 2))) # BHWC to BCHW
|
||||||
|
x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
|
||||||
|
t.append(time_sync())
|
||||||
|
|
||||||
|
with amp.autocast(enabled=autocast):
|
||||||
|
# Inference
|
||||||
|
y = self.model(x, augment, profile) # forward
|
||||||
|
t.append(time_sync())
|
||||||
|
|
||||||
|
# Post-process
|
||||||
|
y = non_max_suppression(y if self.dmb else y[0], self.conf, iou_thres=self.iou, classes=self.classes,
|
||||||
|
agnostic=self.agnostic, multi_label=self.multi_label, max_det=self.max_det) # NMS
|
||||||
|
for i in range(n):
|
||||||
|
scale_coords(shape1, y[i][:, :4], shape0[i])
|
||||||
|
|
||||||
|
t.append(time_sync())
|
||||||
|
return Detections(imgs, y, files, t, self.names, x.shape)
|
||||||
|
|
||||||
|
|
||||||
|
class Detections:
|
||||||
|
# YOLOv5 detections class for inference results
|
||||||
|
def __init__(self, imgs, pred, files, times=(0, 0, 0, 0), names=None, shape=None):
|
||||||
|
super().__init__()
|
||||||
|
d = pred[0].device # device
|
||||||
|
gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in imgs] # normalizations
|
||||||
|
self.imgs = imgs # list of images as numpy arrays
|
||||||
|
self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
|
||||||
|
self.names = names # class names
|
||||||
|
self.files = files # image filenames
|
||||||
|
self.times = times # profiling times
|
||||||
|
self.xyxy = pred # xyxy pixels
|
||||||
|
self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
|
||||||
|
self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
|
||||||
|
self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
|
||||||
|
self.n = len(self.pred) # number of images (batch size)
|
||||||
|
self.t = tuple((times[i + 1] - times[i]) * 1000 / self.n for i in range(3)) # timestamps (ms)
|
||||||
|
self.s = shape # inference BCHW shape
|
||||||
|
|
||||||
|
def display(self, pprint=False, show=False, save=False, crop=False, render=False, save_dir=Path('')):
|
||||||
|
crops = []
|
||||||
|
for i, (im, pred) in enumerate(zip(self.imgs, self.pred)):
|
||||||
|
s = f'image {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
|
||||||
|
if pred.shape[0]:
|
||||||
|
for c in pred[:, -1].unique():
|
||||||
|
n = (pred[:, -1] == c).sum() # detections per class
|
||||||
|
s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
|
||||||
|
if show or save or render or crop:
|
||||||
|
annotator = Annotator(im, example=str(self.names))
|
||||||
|
for *box, conf, cls in reversed(pred): # xyxy, confidence, class
|
||||||
|
label = f'{self.names[int(cls)]} {conf:.2f}'
|
||||||
|
if crop:
|
||||||
|
file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
|
||||||
|
crops.append({'box': box, 'conf': conf, 'cls': cls, 'label': label,
|
||||||
|
'im': save_one_box(box, im, file=file, save=save)})
|
||||||
|
else: # all others
|
||||||
|
annotator.box_label(box, label, color=colors(cls))
|
||||||
|
im = annotator.im
|
||||||
|
else:
|
||||||
|
s += '(no detections)'
|
||||||
|
|
||||||
|
im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
|
||||||
|
if pprint:
|
||||||
|
LOGGER.info(s.rstrip(', '))
|
||||||
|
if show:
|
||||||
|
im.show(self.files[i]) # show
|
||||||
|
if save:
|
||||||
|
f = self.files[i]
|
||||||
|
im.save(save_dir / f) # save
|
||||||
|
if i == self.n - 1:
|
||||||
|
LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
|
||||||
|
if render:
|
||||||
|
self.imgs[i] = np.asarray(im)
|
||||||
|
if crop:
|
||||||
|
if save:
|
||||||
|
LOGGER.info(f'Saved results to {save_dir}\n')
|
||||||
|
return crops
|
||||||
|
|
||||||
|
def print(self):
|
||||||
|
self.display(pprint=True) # print results
|
||||||
|
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {tuple(self.s)}' %
|
||||||
|
self.t)
|
||||||
|
|
||||||
|
def show(self):
|
||||||
|
self.display(show=True) # show results
|
||||||
|
|
||||||
|
def save(self, save_dir='runs/detect/exp'):
|
||||||
|
save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
|
||||||
|
self.display(save=True, save_dir=save_dir) # save results
|
||||||
|
|
||||||
|
def crop(self, save=True, save_dir='runs/detect/exp'):
|
||||||
|
save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
|
||||||
|
return self.display(crop=True, save=save, save_dir=save_dir) # crop results
|
||||||
|
|
||||||
|
def render(self):
|
||||||
|
self.display(render=True) # render results
|
||||||
|
return self.imgs
|
||||||
|
|
||||||
|
def pandas(self):
|
||||||
|
# return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
|
||||||
|
new = copy(self) # return copy
|
||||||
|
ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
|
||||||
|
cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
|
||||||
|
for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
|
||||||
|
a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
|
||||||
|
setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
|
||||||
|
return new
|
||||||
|
|
||||||
|
def tolist(self):
|
||||||
|
# return a list of Detections objects, i.e. 'for result in results.tolist():'
|
||||||
|
r = range(self.n) # iterable
|
||||||
|
x = [Detections([self.imgs[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]
|
||||||
|
# for d in x:
|
||||||
|
# for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
|
||||||
|
# setattr(d, k, getattr(d, k)[0]) # pop out of list
|
||||||
|
return x
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return self.n
|
||||||
|
|
||||||
|
|
||||||
|
class Classify(nn.Module):
|
||||||
|
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
|
||||||
|
super().__init__()
|
||||||
|
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
|
||||||
|
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
|
||||||
|
self.flat = nn.Flatten()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
|
||||||
|
return self.flat(self.conv(z)) # flatten to x(b,c2)
|
||||||
120
models/experimental.py
Normal file
120
models/experimental.py
Normal file
@ -0,0 +1,120 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Experimental modules
|
||||||
|
"""
|
||||||
|
import math
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
from models.common import Conv
|
||||||
|
from utils.downloads import attempt_download
|
||||||
|
|
||||||
|
|
||||||
|
class CrossConv(nn.Module):
|
||||||
|
# Cross Convolution Downsample
|
||||||
|
def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
|
||||||
|
# ch_in, ch_out, kernel, stride, groups, expansion, shortcut
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = Conv(c1, c_, (1, k), (1, s))
|
||||||
|
self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
|
||||||
|
self.add = shortcut and c1 == c2
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
|
||||||
|
|
||||||
|
|
||||||
|
class Sum(nn.Module):
|
||||||
|
# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
|
||||||
|
def __init__(self, n, weight=False): # n: number of inputs
|
||||||
|
super().__init__()
|
||||||
|
self.weight = weight # apply weights boolean
|
||||||
|
self.iter = range(n - 1) # iter object
|
||||||
|
if weight:
|
||||||
|
self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
y = x[0] # no weight
|
||||||
|
if self.weight:
|
||||||
|
w = torch.sigmoid(self.w) * 2
|
||||||
|
for i in self.iter:
|
||||||
|
y = y + x[i + 1] * w[i]
|
||||||
|
else:
|
||||||
|
for i in self.iter:
|
||||||
|
y = y + x[i + 1]
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
class MixConv2d(nn.Module):
|
||||||
|
# Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
|
||||||
|
def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
|
||||||
|
super().__init__()
|
||||||
|
n = len(k) # number of convolutions
|
||||||
|
if equal_ch: # equal c_ per group
|
||||||
|
i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
|
||||||
|
c_ = [(i == g).sum() for g in range(n)] # intermediate channels
|
||||||
|
else: # equal weight.numel() per group
|
||||||
|
b = [c2] + [0] * n
|
||||||
|
a = np.eye(n + 1, n, k=-1)
|
||||||
|
a -= np.roll(a, 1, axis=1)
|
||||||
|
a *= np.array(k) ** 2
|
||||||
|
a[0] = 1
|
||||||
|
c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
|
||||||
|
|
||||||
|
self.m = nn.ModuleList(
|
||||||
|
[nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
|
||||||
|
self.bn = nn.BatchNorm2d(c2)
|
||||||
|
self.act = nn.SiLU()
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
|
||||||
|
|
||||||
|
|
||||||
|
class Ensemble(nn.ModuleList):
|
||||||
|
# Ensemble of models
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__()
|
||||||
|
|
||||||
|
def forward(self, x, augment=False, profile=False, visualize=False):
|
||||||
|
y = []
|
||||||
|
for module in self:
|
||||||
|
y.append(module(x, augment, profile, visualize)[0])
|
||||||
|
# y = torch.stack(y).max(0)[0] # max ensemble
|
||||||
|
# y = torch.stack(y).mean(0) # mean ensemble
|
||||||
|
y = torch.cat(y, 1) # nms ensemble
|
||||||
|
return y, None # inference, train output
|
||||||
|
|
||||||
|
|
||||||
|
def attempt_load(weights, map_location=None, inplace=True, fuse=True):
|
||||||
|
from models.yolo import Detect, Model
|
||||||
|
|
||||||
|
# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
|
||||||
|
model = Ensemble()
|
||||||
|
for w in weights if isinstance(weights, list) else [weights]:
|
||||||
|
ckpt = torch.load(attempt_download(w), map_location=map_location) # load
|
||||||
|
if fuse:
|
||||||
|
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
|
||||||
|
else:
|
||||||
|
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse
|
||||||
|
|
||||||
|
# Compatibility updates
|
||||||
|
for m in model.modules():
|
||||||
|
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
|
||||||
|
m.inplace = inplace # pytorch 1.7.0 compatibility
|
||||||
|
if type(m) is Detect:
|
||||||
|
if not isinstance(m.anchor_grid, list): # new Detect Layer compatibility
|
||||||
|
delattr(m, 'anchor_grid')
|
||||||
|
setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
|
||||||
|
elif type(m) is Conv:
|
||||||
|
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
|
||||||
|
|
||||||
|
if len(model) == 1:
|
||||||
|
return model[-1] # return model
|
||||||
|
else:
|
||||||
|
print(f'Ensemble created with {weights}\n')
|
||||||
|
for k in ['names']:
|
||||||
|
setattr(model, k, getattr(model[-1], k))
|
||||||
|
model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
|
||||||
|
return model # return ensemble
|
||||||
464
models/tf.py
Normal file
464
models/tf.py
Normal file
@ -0,0 +1,464 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
TensorFlow, Keras and TFLite versions of YOLOv5
|
||||||
|
Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
$ python models/tf.py --weights yolov5s.pt
|
||||||
|
|
||||||
|
Export:
|
||||||
|
$ python path/to/export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
|
||||||
|
"""
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
from copy import deepcopy
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
FILE = Path(__file__).resolve()
|
||||||
|
ROOT = FILE.parents[1] # YOLOv5 root directory
|
||||||
|
if str(ROOT) not in sys.path:
|
||||||
|
sys.path.append(str(ROOT)) # add ROOT to PATH
|
||||||
|
# ROOT = ROOT.relative_to(Path.cwd()) # relative
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import tensorflow as tf
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
from tensorflow import keras
|
||||||
|
|
||||||
|
from models.common import C3, SPP, SPPF, Bottleneck, BottleneckCSP, Concat, Conv, DWConv, Focus, autopad
|
||||||
|
from models.experimental import CrossConv, MixConv2d, attempt_load
|
||||||
|
from models.yolo import Detect
|
||||||
|
from utils.activations import SiLU
|
||||||
|
from utils.general import LOGGER, make_divisible, print_args
|
||||||
|
|
||||||
|
|
||||||
|
class TFBN(keras.layers.Layer):
|
||||||
|
# TensorFlow BatchNormalization wrapper
|
||||||
|
def __init__(self, w=None):
|
||||||
|
super().__init__()
|
||||||
|
self.bn = keras.layers.BatchNormalization(
|
||||||
|
beta_initializer=keras.initializers.Constant(w.bias.numpy()),
|
||||||
|
gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
|
||||||
|
moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
|
||||||
|
moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
|
||||||
|
epsilon=w.eps)
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return self.bn(inputs)
|
||||||
|
|
||||||
|
|
||||||
|
class TFPad(keras.layers.Layer):
|
||||||
|
def __init__(self, pad):
|
||||||
|
super().__init__()
|
||||||
|
self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
|
||||||
|
|
||||||
|
|
||||||
|
class TFConv(keras.layers.Layer):
|
||||||
|
# Standard convolution
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
|
||||||
|
# ch_in, ch_out, weights, kernel, stride, padding, groups
|
||||||
|
super().__init__()
|
||||||
|
assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
|
||||||
|
assert isinstance(k, int), "Convolution with multiple kernels are not allowed."
|
||||||
|
# TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
|
||||||
|
# see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
|
||||||
|
|
||||||
|
conv = keras.layers.Conv2D(
|
||||||
|
c2, k, s, 'SAME' if s == 1 else 'VALID', use_bias=False if hasattr(w, 'bn') else True,
|
||||||
|
kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
|
||||||
|
bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
|
||||||
|
self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
|
||||||
|
self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
|
||||||
|
|
||||||
|
# YOLOv5 activations
|
||||||
|
if isinstance(w.act, nn.LeakyReLU):
|
||||||
|
self.act = (lambda x: keras.activations.relu(x, alpha=0.1)) if act else tf.identity
|
||||||
|
elif isinstance(w.act, nn.Hardswish):
|
||||||
|
self.act = (lambda x: x * tf.nn.relu6(x + 3) * 0.166666667) if act else tf.identity
|
||||||
|
elif isinstance(w.act, (nn.SiLU, SiLU)):
|
||||||
|
self.act = (lambda x: keras.activations.swish(x)) if act else tf.identity
|
||||||
|
else:
|
||||||
|
raise Exception(f'no matching TensorFlow activation found for {w.act}')
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return self.act(self.bn(self.conv(inputs)))
|
||||||
|
|
||||||
|
|
||||||
|
class TFFocus(keras.layers.Layer):
|
||||||
|
# Focus wh information into c-space
|
||||||
|
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
|
||||||
|
# ch_in, ch_out, kernel, stride, padding, groups
|
||||||
|
super().__init__()
|
||||||
|
self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
|
||||||
|
|
||||||
|
def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
|
||||||
|
# inputs = inputs / 255 # normalize 0-255 to 0-1
|
||||||
|
return self.conv(tf.concat([inputs[:, ::2, ::2, :],
|
||||||
|
inputs[:, 1::2, ::2, :],
|
||||||
|
inputs[:, ::2, 1::2, :],
|
||||||
|
inputs[:, 1::2, 1::2, :]], 3))
|
||||||
|
|
||||||
|
|
||||||
|
class TFBottleneck(keras.layers.Layer):
|
||||||
|
# Standard bottleneck
|
||||||
|
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
|
||||||
|
self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
|
||||||
|
self.add = shortcut and c1 == c2
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
|
||||||
|
|
||||||
|
|
||||||
|
class TFConv2d(keras.layers.Layer):
|
||||||
|
# Substitution for PyTorch nn.Conv2D
|
||||||
|
def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
|
||||||
|
super().__init__()
|
||||||
|
assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
|
||||||
|
self.conv = keras.layers.Conv2D(
|
||||||
|
c2, k, s, 'VALID', use_bias=bias,
|
||||||
|
kernel_initializer=keras.initializers.Constant(w.weight.permute(2, 3, 1, 0).numpy()),
|
||||||
|
bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None, )
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return self.conv(inputs)
|
||||||
|
|
||||||
|
|
||||||
|
class TFBottleneckCSP(keras.layers.Layer):
|
||||||
|
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
|
||||||
|
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
|
||||||
|
# ch_in, ch_out, number, shortcut, groups, expansion
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
|
||||||
|
self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
|
||||||
|
self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
|
||||||
|
self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
|
||||||
|
self.bn = TFBN(w.bn)
|
||||||
|
self.act = lambda x: keras.activations.relu(x, alpha=0.1)
|
||||||
|
self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
y1 = self.cv3(self.m(self.cv1(inputs)))
|
||||||
|
y2 = self.cv2(inputs)
|
||||||
|
return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
|
||||||
|
|
||||||
|
|
||||||
|
class TFC3(keras.layers.Layer):
|
||||||
|
# CSP Bottleneck with 3 convolutions
|
||||||
|
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
|
||||||
|
# ch_in, ch_out, number, shortcut, groups, expansion
|
||||||
|
super().__init__()
|
||||||
|
c_ = int(c2 * e) # hidden channels
|
||||||
|
self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
|
||||||
|
self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
|
||||||
|
self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
|
||||||
|
self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
|
||||||
|
|
||||||
|
|
||||||
|
class TFSPP(keras.layers.Layer):
|
||||||
|
# Spatial pyramid pooling layer used in YOLOv3-SPP
|
||||||
|
def __init__(self, c1, c2, k=(5, 9, 13), w=None):
|
||||||
|
super().__init__()
|
||||||
|
c_ = c1 // 2 # hidden channels
|
||||||
|
self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
|
||||||
|
self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
|
||||||
|
self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
x = self.cv1(inputs)
|
||||||
|
return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
|
||||||
|
|
||||||
|
|
||||||
|
class TFSPPF(keras.layers.Layer):
|
||||||
|
# Spatial pyramid pooling-Fast layer
|
||||||
|
def __init__(self, c1, c2, k=5, w=None):
|
||||||
|
super().__init__()
|
||||||
|
c_ = c1 // 2 # hidden channels
|
||||||
|
self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
|
||||||
|
self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
|
||||||
|
self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
x = self.cv1(inputs)
|
||||||
|
y1 = self.m(x)
|
||||||
|
y2 = self.m(y1)
|
||||||
|
return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
|
||||||
|
|
||||||
|
|
||||||
|
class TFDetect(keras.layers.Layer):
|
||||||
|
def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
|
||||||
|
super().__init__()
|
||||||
|
self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
|
||||||
|
self.nc = nc # number of classes
|
||||||
|
self.no = nc + 5 # number of outputs per anchor
|
||||||
|
self.nl = len(anchors) # number of detection layers
|
||||||
|
self.na = len(anchors[0]) // 2 # number of anchors
|
||||||
|
self.grid = [tf.zeros(1)] * self.nl # init grid
|
||||||
|
self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
|
||||||
|
self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]),
|
||||||
|
[self.nl, 1, -1, 1, 2])
|
||||||
|
self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
|
||||||
|
self.training = False # set to False after building model
|
||||||
|
self.imgsz = imgsz
|
||||||
|
for i in range(self.nl):
|
||||||
|
ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
|
||||||
|
self.grid[i] = self._make_grid(nx, ny)
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
z = [] # inference output
|
||||||
|
x = []
|
||||||
|
for i in range(self.nl):
|
||||||
|
x.append(self.m[i](inputs[i]))
|
||||||
|
# x(bs,20,20,255) to x(bs,3,20,20,85)
|
||||||
|
ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
|
||||||
|
x[i] = tf.transpose(tf.reshape(x[i], [-1, ny * nx, self.na, self.no]), [0, 2, 1, 3])
|
||||||
|
|
||||||
|
if not self.training: # inference
|
||||||
|
y = tf.sigmoid(x[i])
|
||||||
|
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
|
||||||
|
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
|
||||||
|
# Normalize xywh to 0-1 to reduce calibration error
|
||||||
|
xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
|
||||||
|
wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
|
||||||
|
y = tf.concat([xy, wh, y[..., 4:]], -1)
|
||||||
|
z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
|
||||||
|
|
||||||
|
return x if self.training else (tf.concat(z, 1), x)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _make_grid(nx=20, ny=20):
|
||||||
|
# yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
|
||||||
|
# return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
|
||||||
|
xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
|
||||||
|
return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
|
||||||
|
|
||||||
|
|
||||||
|
class TFUpsample(keras.layers.Layer):
|
||||||
|
def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
|
||||||
|
super().__init__()
|
||||||
|
assert scale_factor == 2, "scale_factor must be 2"
|
||||||
|
self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * 2, x.shape[2] * 2), method=mode)
|
||||||
|
# self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
|
||||||
|
# with default arguments: align_corners=False, half_pixel_centers=False
|
||||||
|
# self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
|
||||||
|
# size=(x.shape[1] * 2, x.shape[2] * 2))
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return self.upsample(inputs)
|
||||||
|
|
||||||
|
|
||||||
|
class TFConcat(keras.layers.Layer):
|
||||||
|
def __init__(self, dimension=1, w=None):
|
||||||
|
super().__init__()
|
||||||
|
assert dimension == 1, "convert only NCHW to NHWC concat"
|
||||||
|
self.d = 3
|
||||||
|
|
||||||
|
def call(self, inputs):
|
||||||
|
return tf.concat(inputs, self.d)
|
||||||
|
|
||||||
|
|
||||||
|
def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
|
||||||
|
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
|
||||||
|
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
|
||||||
|
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
|
||||||
|
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
|
||||||
|
|
||||||
|
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
|
||||||
|
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
|
||||||
|
m_str = m
|
||||||
|
m = eval(m) if isinstance(m, str) else m # eval strings
|
||||||
|
for j, a in enumerate(args):
|
||||||
|
try:
|
||||||
|
args[j] = eval(a) if isinstance(a, str) else a # eval strings
|
||||||
|
except NameError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
n = max(round(n * gd), 1) if n > 1 else n # depth gain
|
||||||
|
if m in [nn.Conv2d, Conv, Bottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
|
||||||
|
c1, c2 = ch[f], args[0]
|
||||||
|
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
|
||||||
|
|
||||||
|
args = [c1, c2, *args[1:]]
|
||||||
|
if m in [BottleneckCSP, C3]:
|
||||||
|
args.insert(2, n)
|
||||||
|
n = 1
|
||||||
|
elif m is nn.BatchNorm2d:
|
||||||
|
args = [ch[f]]
|
||||||
|
elif m is Concat:
|
||||||
|
c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
|
||||||
|
elif m is Detect:
|
||||||
|
args.append([ch[x + 1] for x in f])
|
||||||
|
if isinstance(args[1], int): # number of anchors
|
||||||
|
args[1] = [list(range(args[1] * 2))] * len(f)
|
||||||
|
args.append(imgsz)
|
||||||
|
else:
|
||||||
|
c2 = ch[f]
|
||||||
|
|
||||||
|
tf_m = eval('TF' + m_str.replace('nn.', ''))
|
||||||
|
m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
|
||||||
|
else tf_m(*args, w=model.model[i]) # module
|
||||||
|
|
||||||
|
torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
|
||||||
|
t = str(m)[8:-2].replace('__main__.', '') # module type
|
||||||
|
np = sum(x.numel() for x in torch_m_.parameters()) # number params
|
||||||
|
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
|
||||||
|
LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
|
||||||
|
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
|
||||||
|
layers.append(m_)
|
||||||
|
ch.append(c2)
|
||||||
|
return keras.Sequential(layers), sorted(save)
|
||||||
|
|
||||||
|
|
||||||
|
class TFModel:
|
||||||
|
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
|
||||||
|
super().__init__()
|
||||||
|
if isinstance(cfg, dict):
|
||||||
|
self.yaml = cfg # model dict
|
||||||
|
else: # is *.yaml
|
||||||
|
import yaml # for torch hub
|
||||||
|
self.yaml_file = Path(cfg).name
|
||||||
|
with open(cfg) as f:
|
||||||
|
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
|
||||||
|
|
||||||
|
# Define model
|
||||||
|
if nc and nc != self.yaml['nc']:
|
||||||
|
LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
|
||||||
|
self.yaml['nc'] = nc # override yaml value
|
||||||
|
self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
|
||||||
|
|
||||||
|
def predict(self, inputs, tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
|
||||||
|
conf_thres=0.25):
|
||||||
|
y = [] # outputs
|
||||||
|
x = inputs
|
||||||
|
for i, m in enumerate(self.model.layers):
|
||||||
|
if m.f != -1: # if not from previous layer
|
||||||
|
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
|
||||||
|
|
||||||
|
x = m(x) # run
|
||||||
|
y.append(x if m.i in self.savelist else None) # save output
|
||||||
|
|
||||||
|
# Add TensorFlow NMS
|
||||||
|
if tf_nms:
|
||||||
|
boxes = self._xywh2xyxy(x[0][..., :4])
|
||||||
|
probs = x[0][:, :, 4:5]
|
||||||
|
classes = x[0][:, :, 5:]
|
||||||
|
scores = probs * classes
|
||||||
|
if agnostic_nms:
|
||||||
|
nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
|
||||||
|
return nms, x[1]
|
||||||
|
else:
|
||||||
|
boxes = tf.expand_dims(boxes, 2)
|
||||||
|
nms = tf.image.combined_non_max_suppression(
|
||||||
|
boxes, scores, topk_per_class, topk_all, iou_thres, conf_thres, clip_boxes=False)
|
||||||
|
return nms, x[1]
|
||||||
|
|
||||||
|
return x[0] # output only first tensor [1,6300,85] = [xywh, conf, class0, class1, ...]
|
||||||
|
# x = x[0][0] # [x(1,6300,85), ...] to x(6300,85)
|
||||||
|
# xywh = x[..., :4] # x(6300,4) boxes
|
||||||
|
# conf = x[..., 4:5] # x(6300,1) confidences
|
||||||
|
# cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
|
||||||
|
# return tf.concat([conf, cls, xywh], 1)
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _xywh2xyxy(xywh):
|
||||||
|
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
|
||||||
|
x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
|
||||||
|
return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
|
||||||
|
|
||||||
|
|
||||||
|
class AgnosticNMS(keras.layers.Layer):
|
||||||
|
# TF Agnostic NMS
|
||||||
|
def call(self, input, topk_all, iou_thres, conf_thres):
|
||||||
|
# wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
|
||||||
|
return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres), input,
|
||||||
|
fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
|
||||||
|
name='agnostic_nms')
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
|
||||||
|
boxes, classes, scores = x
|
||||||
|
class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
|
||||||
|
scores_inp = tf.reduce_max(scores, -1)
|
||||||
|
selected_inds = tf.image.non_max_suppression(
|
||||||
|
boxes, scores_inp, max_output_size=topk_all, iou_threshold=iou_thres, score_threshold=conf_thres)
|
||||||
|
selected_boxes = tf.gather(boxes, selected_inds)
|
||||||
|
padded_boxes = tf.pad(selected_boxes,
|
||||||
|
paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
|
||||||
|
mode="CONSTANT", constant_values=0.0)
|
||||||
|
selected_scores = tf.gather(scores_inp, selected_inds)
|
||||||
|
padded_scores = tf.pad(selected_scores,
|
||||||
|
paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
|
||||||
|
mode="CONSTANT", constant_values=-1.0)
|
||||||
|
selected_classes = tf.gather(class_inds, selected_inds)
|
||||||
|
padded_classes = tf.pad(selected_classes,
|
||||||
|
paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
|
||||||
|
mode="CONSTANT", constant_values=-1.0)
|
||||||
|
valid_detections = tf.shape(selected_inds)[0]
|
||||||
|
return padded_boxes, padded_scores, padded_classes, valid_detections
|
||||||
|
|
||||||
|
|
||||||
|
def representative_dataset_gen(dataset, ncalib=100):
|
||||||
|
# Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
|
||||||
|
for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
|
||||||
|
input = np.transpose(img, [1, 2, 0])
|
||||||
|
input = np.expand_dims(input, axis=0).astype(np.float32)
|
||||||
|
input /= 255
|
||||||
|
yield [input]
|
||||||
|
if n >= ncalib:
|
||||||
|
break
|
||||||
|
|
||||||
|
|
||||||
|
def run(weights=ROOT / 'yolov5s.pt', # weights path
|
||||||
|
imgsz=(640, 640), # inference size h,w
|
||||||
|
batch_size=1, # batch size
|
||||||
|
dynamic=False, # dynamic batch size
|
||||||
|
):
|
||||||
|
# PyTorch model
|
||||||
|
im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
|
||||||
|
model = attempt_load(weights, map_location=torch.device('cpu'), inplace=True, fuse=False)
|
||||||
|
_ = model(im) # inference
|
||||||
|
model.info()
|
||||||
|
|
||||||
|
# TensorFlow model
|
||||||
|
im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
|
||||||
|
tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
|
||||||
|
_ = tf_model.predict(im) # inference
|
||||||
|
|
||||||
|
# Keras model
|
||||||
|
im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
|
||||||
|
keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
|
||||||
|
keras_model.summary()
|
||||||
|
|
||||||
|
LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
|
||||||
|
|
||||||
|
|
||||||
|
def parse_opt():
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
|
||||||
|
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
|
||||||
|
parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
|
||||||
|
opt = parser.parse_args()
|
||||||
|
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
|
||||||
|
print_args(FILE.stem, opt)
|
||||||
|
return opt
|
||||||
|
|
||||||
|
|
||||||
|
def main(opt):
|
||||||
|
run(**vars(opt))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
opt = parse_opt()
|
||||||
|
main(opt)
|
||||||
329
models/yolo.py
Normal file
329
models/yolo.py
Normal file
@ -0,0 +1,329 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
YOLO-specific modules
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
$ python path/to/models/yolo.py --cfg yolov5s.yaml
|
||||||
|
"""
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
from copy import deepcopy
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
FILE = Path(__file__).resolve()
|
||||||
|
ROOT = FILE.parents[1] # YOLOv5 root directory
|
||||||
|
if str(ROOT) not in sys.path:
|
||||||
|
sys.path.append(str(ROOT)) # add ROOT to PATH
|
||||||
|
# ROOT = ROOT.relative_to(Path.cwd()) # relative
|
||||||
|
|
||||||
|
from models.common import *
|
||||||
|
from models.experimental import *
|
||||||
|
from utils.autoanchor import check_anchor_order
|
||||||
|
from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
|
||||||
|
from utils.plots import feature_visualization
|
||||||
|
from utils.torch_utils import fuse_conv_and_bn, initialize_weights, model_info, scale_img, select_device, time_sync
|
||||||
|
|
||||||
|
try:
|
||||||
|
import thop # for FLOPs computation
|
||||||
|
except ImportError:
|
||||||
|
thop = None
|
||||||
|
|
||||||
|
|
||||||
|
class Detect(nn.Module):
|
||||||
|
stride = None # strides computed during build
|
||||||
|
onnx_dynamic = False # ONNX export parameter
|
||||||
|
|
||||||
|
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
|
||||||
|
super().__init__()
|
||||||
|
self.nc = nc # number of classes
|
||||||
|
self.no = nc + 5 # number of outputs per anchor
|
||||||
|
self.nl = len(anchors) # number of detection layers
|
||||||
|
self.na = len(anchors[0]) // 2 # number of anchors
|
||||||
|
self.grid = [torch.zeros(1)] * self.nl # init grid
|
||||||
|
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
|
||||||
|
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
|
||||||
|
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
|
||||||
|
self.inplace = inplace # use in-place ops (e.g. slice assignment)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
z = [] # inference output
|
||||||
|
for i in range(self.nl):
|
||||||
|
x[i] = self.m[i](x[i]) # conv
|
||||||
|
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
|
||||||
|
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
|
||||||
|
|
||||||
|
if not self.training: # inference
|
||||||
|
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
|
||||||
|
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
|
||||||
|
|
||||||
|
y = x[i].sigmoid()
|
||||||
|
if self.inplace:
|
||||||
|
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
|
||||||
|
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
|
||||||
|
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
|
||||||
|
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
|
||||||
|
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
|
||||||
|
y = torch.cat((xy, wh, y[..., 4:]), -1)
|
||||||
|
z.append(y.view(bs, -1, self.no))
|
||||||
|
|
||||||
|
return x if self.training else (torch.cat(z, 1), x)
|
||||||
|
|
||||||
|
def _make_grid(self, nx=20, ny=20, i=0):
|
||||||
|
d = self.anchors[i].device
|
||||||
|
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
|
||||||
|
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)], indexing='ij')
|
||||||
|
else:
|
||||||
|
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)])
|
||||||
|
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
|
||||||
|
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
|
||||||
|
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
|
||||||
|
return grid, anchor_grid
|
||||||
|
|
||||||
|
|
||||||
|
class Model(nn.Module):
|
||||||
|
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
|
||||||
|
super().__init__()
|
||||||
|
if isinstance(cfg, dict):
|
||||||
|
self.yaml = cfg # model dict
|
||||||
|
else: # is *.yaml
|
||||||
|
import yaml # for torch hub
|
||||||
|
self.yaml_file = Path(cfg).name
|
||||||
|
with open(cfg, encoding='ascii', errors='ignore') as f:
|
||||||
|
self.yaml = yaml.safe_load(f) # model dict
|
||||||
|
|
||||||
|
# Define model
|
||||||
|
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
|
||||||
|
if nc and nc != self.yaml['nc']:
|
||||||
|
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
|
||||||
|
self.yaml['nc'] = nc # override yaml value
|
||||||
|
if anchors:
|
||||||
|
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
|
||||||
|
self.yaml['anchors'] = round(anchors) # override yaml value
|
||||||
|
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
|
||||||
|
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
|
||||||
|
self.inplace = self.yaml.get('inplace', True)
|
||||||
|
|
||||||
|
# Build strides, anchors
|
||||||
|
m = self.model[-1] # Detect()
|
||||||
|
if isinstance(m, Detect):
|
||||||
|
s = 256 # 2x min stride
|
||||||
|
m.inplace = self.inplace
|
||||||
|
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
|
||||||
|
m.anchors /= m.stride.view(-1, 1, 1)
|
||||||
|
check_anchor_order(m)
|
||||||
|
self.stride = m.stride
|
||||||
|
self._initialize_biases() # only run once
|
||||||
|
|
||||||
|
# Init weights, biases
|
||||||
|
initialize_weights(self)
|
||||||
|
self.info()
|
||||||
|
LOGGER.info('')
|
||||||
|
|
||||||
|
def forward(self, x, augment=False, profile=False, visualize=False):
|
||||||
|
if augment:
|
||||||
|
return self._forward_augment(x) # augmented inference, None
|
||||||
|
return self._forward_once(x, profile, visualize) # single-scale inference, train
|
||||||
|
|
||||||
|
def _forward_augment(self, x):
|
||||||
|
img_size = x.shape[-2:] # height, width
|
||||||
|
s = [1, 0.83, 0.67] # scales
|
||||||
|
f = [None, 3, None] # flips (2-ud, 3-lr)
|
||||||
|
y = [] # outputs
|
||||||
|
for si, fi in zip(s, f):
|
||||||
|
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
|
||||||
|
yi = self._forward_once(xi)[0] # forward
|
||||||
|
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
|
||||||
|
yi = self._descale_pred(yi, fi, si, img_size)
|
||||||
|
y.append(yi)
|
||||||
|
y = self._clip_augmented(y) # clip augmented tails
|
||||||
|
return torch.cat(y, 1), None # augmented inference, train
|
||||||
|
|
||||||
|
def _forward_once(self, x, profile=False, visualize=False):
|
||||||
|
y, dt = [], [] # outputs
|
||||||
|
for m in self.model:
|
||||||
|
if m.f != -1: # if not from previous layer
|
||||||
|
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
|
||||||
|
if profile:
|
||||||
|
self._profile_one_layer(m, x, dt)
|
||||||
|
x = m(x) # run
|
||||||
|
y.append(x if m.i in self.save else None) # save output
|
||||||
|
if visualize:
|
||||||
|
feature_visualization(x, m.type, m.i, save_dir=visualize)
|
||||||
|
return x
|
||||||
|
|
||||||
|
def _descale_pred(self, p, flips, scale, img_size):
|
||||||
|
# de-scale predictions following augmented inference (inverse operation)
|
||||||
|
if self.inplace:
|
||||||
|
p[..., :4] /= scale # de-scale
|
||||||
|
if flips == 2:
|
||||||
|
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
|
||||||
|
elif flips == 3:
|
||||||
|
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
|
||||||
|
else:
|
||||||
|
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
|
||||||
|
if flips == 2:
|
||||||
|
y = img_size[0] - y # de-flip ud
|
||||||
|
elif flips == 3:
|
||||||
|
x = img_size[1] - x # de-flip lr
|
||||||
|
p = torch.cat((x, y, wh, p[..., 4:]), -1)
|
||||||
|
return p
|
||||||
|
|
||||||
|
def _clip_augmented(self, y):
|
||||||
|
# Clip YOLOv5 augmented inference tails
|
||||||
|
nl = self.model[-1].nl # number of detection layers (P3-P5)
|
||||||
|
g = sum(4 ** x for x in range(nl)) # grid points
|
||||||
|
e = 1 # exclude layer count
|
||||||
|
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
|
||||||
|
y[0] = y[0][:, :-i] # large
|
||||||
|
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
|
||||||
|
y[-1] = y[-1][:, i:] # small
|
||||||
|
return y
|
||||||
|
|
||||||
|
def _profile_one_layer(self, m, x, dt):
|
||||||
|
c = isinstance(m, Detect) # is final layer, copy input as inplace fix
|
||||||
|
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
|
||||||
|
t = time_sync()
|
||||||
|
for _ in range(10):
|
||||||
|
m(x.copy() if c else x)
|
||||||
|
dt.append((time_sync() - t) * 100)
|
||||||
|
if m == self.model[0]:
|
||||||
|
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
|
||||||
|
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
|
||||||
|
if c:
|
||||||
|
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
|
||||||
|
|
||||||
|
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
|
||||||
|
# https://arxiv.org/abs/1708.02002 section 3.3
|
||||||
|
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
|
||||||
|
m = self.model[-1] # Detect() module
|
||||||
|
for mi, s in zip(m.m, m.stride): # from
|
||||||
|
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
|
||||||
|
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
|
||||||
|
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
|
||||||
|
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
|
||||||
|
|
||||||
|
def _print_biases(self):
|
||||||
|
m = self.model[-1] # Detect() module
|
||||||
|
for mi in m.m: # from
|
||||||
|
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
|
||||||
|
LOGGER.info(
|
||||||
|
('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
|
||||||
|
|
||||||
|
# def _print_weights(self):
|
||||||
|
# for m in self.model.modules():
|
||||||
|
# if type(m) is Bottleneck:
|
||||||
|
# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
|
||||||
|
|
||||||
|
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
|
||||||
|
LOGGER.info('Fusing layers... ')
|
||||||
|
for m in self.model.modules():
|
||||||
|
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
|
||||||
|
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
|
||||||
|
delattr(m, 'bn') # remove batchnorm
|
||||||
|
m.forward = m.forward_fuse # update forward
|
||||||
|
self.info()
|
||||||
|
return self
|
||||||
|
|
||||||
|
def info(self, verbose=False, img_size=640): # print model information
|
||||||
|
model_info(self, verbose, img_size)
|
||||||
|
|
||||||
|
def _apply(self, fn):
|
||||||
|
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
|
||||||
|
self = super()._apply(fn)
|
||||||
|
m = self.model[-1] # Detect()
|
||||||
|
if isinstance(m, Detect):
|
||||||
|
m.stride = fn(m.stride)
|
||||||
|
m.grid = list(map(fn, m.grid))
|
||||||
|
if isinstance(m.anchor_grid, list):
|
||||||
|
m.anchor_grid = list(map(fn, m.anchor_grid))
|
||||||
|
return self
|
||||||
|
|
||||||
|
|
||||||
|
def parse_model(d, ch): # model_dict, input_channels(3)
|
||||||
|
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
|
||||||
|
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
|
||||||
|
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
|
||||||
|
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
|
||||||
|
|
||||||
|
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
|
||||||
|
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
|
||||||
|
m = eval(m) if isinstance(m, str) else m # eval strings
|
||||||
|
for j, a in enumerate(args):
|
||||||
|
try:
|
||||||
|
args[j] = eval(a) if isinstance(a, str) else a # eval strings
|
||||||
|
except NameError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
|
||||||
|
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
|
||||||
|
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
|
||||||
|
c1, c2 = ch[f], args[0]
|
||||||
|
if c2 != no: # if not output
|
||||||
|
c2 = make_divisible(c2 * gw, 8)
|
||||||
|
|
||||||
|
args = [c1, c2, *args[1:]]
|
||||||
|
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
|
||||||
|
args.insert(2, n) # number of repeats
|
||||||
|
n = 1
|
||||||
|
elif m is nn.BatchNorm2d:
|
||||||
|
args = [ch[f]]
|
||||||
|
elif m is Concat:
|
||||||
|
c2 = sum(ch[x] for x in f)
|
||||||
|
elif m is Detect:
|
||||||
|
args.append([ch[x] for x in f])
|
||||||
|
if isinstance(args[1], int): # number of anchors
|
||||||
|
args[1] = [list(range(args[1] * 2))] * len(f)
|
||||||
|
elif m is Contract:
|
||||||
|
c2 = ch[f] * args[0] ** 2
|
||||||
|
elif m is Expand:
|
||||||
|
c2 = ch[f] // args[0] ** 2
|
||||||
|
else:
|
||||||
|
c2 = ch[f]
|
||||||
|
|
||||||
|
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
|
||||||
|
t = str(m)[8:-2].replace('__main__.', '') # module type
|
||||||
|
np = sum(x.numel() for x in m_.parameters()) # number params
|
||||||
|
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
|
||||||
|
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
|
||||||
|
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
|
||||||
|
layers.append(m_)
|
||||||
|
if i == 0:
|
||||||
|
ch = []
|
||||||
|
ch.append(c2)
|
||||||
|
return nn.Sequential(*layers), sorted(save)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
|
||||||
|
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
||||||
|
parser.add_argument('--profile', action='store_true', help='profile model speed')
|
||||||
|
parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
|
||||||
|
opt = parser.parse_args()
|
||||||
|
opt.cfg = check_yaml(opt.cfg) # check YAML
|
||||||
|
print_args(FILE.stem, opt)
|
||||||
|
device = select_device(opt.device)
|
||||||
|
|
||||||
|
# Create model
|
||||||
|
model = Model(opt.cfg).to(device)
|
||||||
|
model.train()
|
||||||
|
|
||||||
|
# Profile
|
||||||
|
if opt.profile:
|
||||||
|
img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
|
||||||
|
y = model(img, profile=True)
|
||||||
|
|
||||||
|
# Test all models
|
||||||
|
if opt.test:
|
||||||
|
for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
|
||||||
|
try:
|
||||||
|
_ = Model(cfg)
|
||||||
|
except Exception as e:
|
||||||
|
print(f'Error in {cfg}: {e}')
|
||||||
|
|
||||||
|
# Tensorboard (not working https://github.com/ultralytics/yolov5/issues/2898)
|
||||||
|
# from torch.utils.tensorboard import SummaryWriter
|
||||||
|
# tb_writer = SummaryWriter('.')
|
||||||
|
# LOGGER.info("Run 'tensorboard --logdir=models' to view tensorboard at http://localhost:6006/")
|
||||||
|
# tb_writer.add_graph(torch.jit.trace(model, img, strict=False), []) # add model graph
|
||||||
BIN
requirements.txt
Normal file
BIN
requirements.txt
Normal file
Binary file not shown.
47
tests/test_rgb.py
Normal file
47
tests/test_rgb.py
Normal file
@ -0,0 +1,47 @@
|
|||||||
|
import os
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from config import Config
|
||||||
|
from models import Detector, AnonymousColorDetector, RgbDetector
|
||||||
|
import cv2
|
||||||
|
|
||||||
|
# 测试单张图片使用RGB进行预测的效果
|
||||||
|
|
||||||
|
# # 测试时间
|
||||||
|
# import time
|
||||||
|
# start_time = time.time()
|
||||||
|
# 读取图片
|
||||||
|
file_path = r"E:\Tobacco\data\testImgs\Image_2022_0726_1413_46_400-001165.bmp"
|
||||||
|
img = cv2.imread(file_path)[..., ::-1]
|
||||||
|
print("img.shape:", img.shape)
|
||||||
|
|
||||||
|
# 初始化和加载色彩模型
|
||||||
|
print('Initializing color model...')
|
||||||
|
rgb_detector = RgbDetector(tobacco_model_path=r'../weights/tobacco_dt_2022-08-27_14-43.model',
|
||||||
|
background_model_path=r"../weights/background_dt_2022-08-22_22-15.model",
|
||||||
|
ai_path='../weights/best0827.pt')
|
||||||
|
_ = rgb_detector.predict(np.ones((Config.nRgbRows, Config.nRgbCols, Config.nRgbBands), dtype=np.uint8) * 40)
|
||||||
|
print('Color model loaded.')
|
||||||
|
|
||||||
|
# 预测单张图片
|
||||||
|
print('Predicting...')
|
||||||
|
mask_rgb = rgb_detector.predict(img).astype(np.uint8)
|
||||||
|
|
||||||
|
# # 测试时间
|
||||||
|
# end_time = time.time()
|
||||||
|
# print("time cost:", end_time - start_time)
|
||||||
|
|
||||||
|
# 使用matplotlib展示两个图片的对比
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
# 切换matplotlib的后端为qt,否则会报错
|
||||||
|
plt.switch_backend('qt5agg')
|
||||||
|
|
||||||
|
fig, ax = plt.subplots(1, 2)
|
||||||
|
ax[0].imshow(img)
|
||||||
|
ax[1].matshow(mask_rgb)
|
||||||
|
plt.show()
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
18
tests/test_utils.py
Normal file
18
tests/test_utils.py
Normal file
@ -0,0 +1,18 @@
|
|||||||
|
import unittest
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from utils import valve_limit
|
||||||
|
|
||||||
|
|
||||||
|
class UtilTestCase(unittest.TestCase):
|
||||||
|
mask_test = np.zeros((1024, 1024), dtype=np.uint8)
|
||||||
|
mask_test[0:20, :] = 1
|
||||||
|
|
||||||
|
def test_valve_limit(self):
|
||||||
|
mask_result = valve_limit(self.mask_test, max_valve_num=49)
|
||||||
|
self.assertTrue(np.all(np.sum(mask_result, 1) <= 49)) # add assertion here
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
unittest.main()
|
||||||
73
transmit.py
73
transmit.py
@ -1,15 +1,14 @@
|
|||||||
import os
|
import os
|
||||||
import threading
|
import threading
|
||||||
|
from multiprocessing import Process, Queue
|
||||||
import time
|
import time
|
||||||
|
|
||||||
from utils import ImgQueue as Queue
|
from utils import ImgQueue as ImgQueue
|
||||||
import numpy as np
|
import numpy as np
|
||||||
from config import Config
|
from config import Config
|
||||||
from models import SpecDetector, RgbDetector
|
from models import SpecDetector, RgbDetector
|
||||||
import typing
|
import typing
|
||||||
import logging
|
import logging
|
||||||
logging.basicConfig(format='%(asctime)s %(levelname)s %(name)s %(message)s',
|
|
||||||
level=logging.INFO)
|
|
||||||
|
|
||||||
|
|
||||||
class Transmitter(object):
|
class Transmitter(object):
|
||||||
@ -25,7 +24,7 @@ class Transmitter(object):
|
|||||||
"""
|
"""
|
||||||
raise NotImplementedError
|
raise NotImplementedError
|
||||||
|
|
||||||
def set_output(self, output: Queue):
|
def set_output(self, output: ImgQueue):
|
||||||
"""
|
"""
|
||||||
设置单个输出源
|
设置单个输出源
|
||||||
:param output:
|
:param output:
|
||||||
@ -83,7 +82,7 @@ class BeforeAfterMethods:
|
|||||||
|
|
||||||
|
|
||||||
class FifoReceiver(Transmitter):
|
class FifoReceiver(Transmitter):
|
||||||
def __init__(self, fifo_path: str, output: Queue, read_max_num: int, msg_queue=None):
|
def __init__(self, fifo_path: str, output: ImgQueue, read_max_num: int, msg_queue=None):
|
||||||
super().__init__()
|
super().__init__()
|
||||||
self._input_fifo_path = None
|
self._input_fifo_path = None
|
||||||
self._output_queue = None
|
self._output_queue = None
|
||||||
@ -101,7 +100,7 @@ class FifoReceiver(Transmitter):
|
|||||||
os.mkfifo(fifo_path, 0o777)
|
os.mkfifo(fifo_path, 0o777)
|
||||||
self._input_fifo_path = fifo_path
|
self._input_fifo_path = fifo_path
|
||||||
|
|
||||||
def set_output(self, output: Queue):
|
def set_output(self, output: ImgQueue):
|
||||||
self._output_queue = output
|
self._output_queue = output
|
||||||
|
|
||||||
def start(self, post_process_func=None, name='fifo_receiver'):
|
def start(self, post_process_func=None, name='fifo_receiver'):
|
||||||
@ -130,7 +129,7 @@ class FifoReceiver(Transmitter):
|
|||||||
|
|
||||||
|
|
||||||
class FifoSender(Transmitter):
|
class FifoSender(Transmitter):
|
||||||
def __init__(self, output_fifo_path: str, source: Queue):
|
def __init__(self, output_fifo_path: str, source: ImgQueue):
|
||||||
super().__init__()
|
super().__init__()
|
||||||
self._input_source = None
|
self._input_source = None
|
||||||
self._output_fifo_path = None
|
self._output_fifo_path = None
|
||||||
@ -140,7 +139,7 @@ class FifoSender(Transmitter):
|
|||||||
self._need_stop.clear()
|
self._need_stop.clear()
|
||||||
self._running_thread = None
|
self._running_thread = None
|
||||||
|
|
||||||
def set_source(self, source: Queue):
|
def set_source(self, source: ImgQueue):
|
||||||
self._input_source = source
|
self._input_source = source
|
||||||
|
|
||||||
def set_output(self, output_fifo_path: str):
|
def set_output(self, output_fifo_path: str):
|
||||||
@ -184,7 +183,7 @@ class CmdImgSplitMidware(Transmitter):
|
|||||||
"""
|
"""
|
||||||
用于控制命令和图像的中间件
|
用于控制命令和图像的中间件
|
||||||
"""
|
"""
|
||||||
def __init__(self, subscribers: typing.Dict[str, Queue], rgb_queue: Queue, spec_queue: Queue):
|
def __init__(self, subscribers: typing.Dict[str, ImgQueue], rgb_queue: ImgQueue, spec_queue: ImgQueue):
|
||||||
super().__init__()
|
super().__init__()
|
||||||
self._rgb_queue = None
|
self._rgb_queue = None
|
||||||
self._spec_queue = None
|
self._spec_queue = None
|
||||||
@ -194,11 +193,11 @@ class CmdImgSplitMidware(Transmitter):
|
|||||||
self.set_output(subscribers)
|
self.set_output(subscribers)
|
||||||
self.thread_stop = threading.Event()
|
self.thread_stop = threading.Event()
|
||||||
|
|
||||||
def set_source(self, rgb_queue: Queue, spec_queue: Queue):
|
def set_source(self, rgb_queue: ImgQueue, spec_queue: ImgQueue):
|
||||||
self._rgb_queue = rgb_queue
|
self._rgb_queue = rgb_queue
|
||||||
self._spec_queue = spec_queue
|
self._spec_queue = spec_queue
|
||||||
|
|
||||||
def set_output(self, output: typing.Dict[str, Queue]):
|
def set_output(self, output: typing.Dict[str, ImgQueue]):
|
||||||
self._subscribers = output
|
self._subscribers = output
|
||||||
|
|
||||||
def start(self, name='CMD_thread'):
|
def start(self, name='CMD_thread'):
|
||||||
@ -246,7 +245,7 @@ class ImageSaver(Transmitter):
|
|||||||
|
|
||||||
|
|
||||||
class ThreadDetector(Transmitter):
|
class ThreadDetector(Transmitter):
|
||||||
def __init__(self, input_queue: Queue, output_queue: Queue):
|
def __init__(self, input_queue: ImgQueue, output_queue: ImgQueue):
|
||||||
super().__init__()
|
super().__init__()
|
||||||
self._input_queue, self._output_queue = input_queue, output_queue
|
self._input_queue, self._output_queue = input_queue, output_queue
|
||||||
self._spec_detector = SpecDetector(blk_model_path=Config.blk_model_path,
|
self._spec_detector = SpecDetector(blk_model_path=Config.blk_model_path,
|
||||||
@ -256,7 +255,7 @@ class ThreadDetector(Transmitter):
|
|||||||
self._predict_thread = None
|
self._predict_thread = None
|
||||||
self._thread_exit = threading.Event()
|
self._thread_exit = threading.Event()
|
||||||
|
|
||||||
def set_source(self, img_queue: Queue):
|
def set_source(self, img_queue: ImgQueue):
|
||||||
self._input_queue = img_queue
|
self._input_queue = img_queue
|
||||||
|
|
||||||
def stop(self, *args, **kwargs):
|
def stop(self, *args, **kwargs):
|
||||||
@ -291,3 +290,51 @@ class ThreadDetector(Transmitter):
|
|||||||
mask = self.predict(spec, rgb)
|
mask = self.predict(spec, rgb)
|
||||||
self._output_queue.safe_put(mask)
|
self._output_queue.safe_put(mask)
|
||||||
self._thread_exit.clear()
|
self._thread_exit.clear()
|
||||||
|
|
||||||
|
|
||||||
|
class ProcessDetector(Transmitter):
|
||||||
|
def __init__(self, input_queue: ImgQueue, output_queue: ImgQueue):
|
||||||
|
super().__init__()
|
||||||
|
self._input_queue, self._output_queue = input_queue, output_queue
|
||||||
|
self._spec_detector = SpecDetector(blk_model_path=Config.blk_model_path,
|
||||||
|
pixel_model_path=Config.pixel_model_path)
|
||||||
|
self._rgb_detector = RgbDetector(tobacco_model_path=Config.rgb_tobacco_model_path,
|
||||||
|
background_model_path=Config.rgb_background_model_path)
|
||||||
|
self._predict_thread = None
|
||||||
|
self._thread_exit = threading.Event()
|
||||||
|
|
||||||
|
def set_source(self, img_queue: ImgQueue):
|
||||||
|
self._input_queue = img_queue
|
||||||
|
|
||||||
|
def stop(self, *args, **kwargs):
|
||||||
|
self._thread_exit.set()
|
||||||
|
|
||||||
|
def start(self, name='predict_thread'):
|
||||||
|
self._predict_thread = Process(target=self._predict_server, name=name, daemon=True)
|
||||||
|
self._predict_thread.start()
|
||||||
|
|
||||||
|
def predict(self, spec: np.ndarray, rgb: np.ndarray):
|
||||||
|
logging.info(f'Detector get image with shape {spec.shape} and {rgb.shape}')
|
||||||
|
t1 = time.time()
|
||||||
|
mask = self._spec_detector.predict(spec)
|
||||||
|
t2 = time.time()
|
||||||
|
logging.info(f'Detector finish spec predict within {(t2 - t1) * 1000:.2f}ms')
|
||||||
|
# rgb识别
|
||||||
|
mask_rgb = self._rgb_detector.predict(rgb)
|
||||||
|
t3 = time.time()
|
||||||
|
logging.info(f'Detector finish rgb predict within {(t3 - t2) * 1000:.2f}ms')
|
||||||
|
# 结果合并
|
||||||
|
mask_result = (mask | mask_rgb).astype(np.uint8)
|
||||||
|
mask_result = mask_result.repeat(Config.blk_size, axis=0).repeat(Config.blk_size, axis=1).astype(np.uint8)
|
||||||
|
t4 = time.time()
|
||||||
|
logging.info(f'Detector finish merge within {(t4 - t3) * 1000: .2f}ms')
|
||||||
|
logging.info(f'Detector finish predict within {(time.time() -t1)*1000:.2f}ms')
|
||||||
|
return mask_result
|
||||||
|
|
||||||
|
def _predict_server(self):
|
||||||
|
while not self._thread_exit.is_set():
|
||||||
|
if not self._input_queue.empty():
|
||||||
|
spec, rgb = self._input_queue.get()
|
||||||
|
mask = self.predict(spec, rgb)
|
||||||
|
self._output_queue.put(mask)
|
||||||
|
self._thread_exit.clear()
|
||||||
147
utils.py
147
utils.py
@ -1,147 +0,0 @@
|
|||||||
# -*- codeing = utf-8 -*-
|
|
||||||
# Time : 2022/7/18 9:46
|
|
||||||
# @Auther : zhouchao
|
|
||||||
# @File: utils.py
|
|
||||||
# @Software:PyCharm
|
|
||||||
import glob
|
|
||||||
import os
|
|
||||||
from queue import Queue
|
|
||||||
|
|
||||||
import cv2
|
|
||||||
import numpy as np
|
|
||||||
from matplotlib import pyplot as plt
|
|
||||||
import re
|
|
||||||
|
|
||||||
|
|
||||||
def natural_sort(l):
|
|
||||||
convert = lambda text: int(text) if text.isdigit() else text.lower()
|
|
||||||
alphanum_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]
|
|
||||||
return sorted(l, key=alphanum_key)
|
|
||||||
|
|
||||||
|
|
||||||
class MergeDict(dict):
|
|
||||||
def __init__(self):
|
|
||||||
super(MergeDict, self).__init__()
|
|
||||||
|
|
||||||
def merge(self, merged: dict):
|
|
||||||
for k, v in merged.items():
|
|
||||||
if k not in self.keys():
|
|
||||||
self.update({k: v})
|
|
||||||
else:
|
|
||||||
original = self.__getitem__(k)
|
|
||||||
new_value = np.concatenate([original, v], axis=0)
|
|
||||||
self.update({k: new_value})
|
|
||||||
return self
|
|
||||||
|
|
||||||
|
|
||||||
class ImgQueue(Queue):
|
|
||||||
"""
|
|
||||||
A custom queue subclass that provides a :meth:`clear` method.
|
|
||||||
"""
|
|
||||||
|
|
||||||
def clear(self):
|
|
||||||
"""
|
|
||||||
Clears all items from the queue.
|
|
||||||
"""
|
|
||||||
|
|
||||||
with self.mutex:
|
|
||||||
unfinished = self.unfinished_tasks - len(self.queue)
|
|
||||||
if unfinished <= 0:
|
|
||||||
if unfinished < 0:
|
|
||||||
raise ValueError('task_done() called too many times')
|
|
||||||
self.all_tasks_done.notify_all()
|
|
||||||
self.unfinished_tasks = unfinished
|
|
||||||
self.queue.clear()
|
|
||||||
self.not_full.notify_all()
|
|
||||||
|
|
||||||
def safe_put(self, item):
|
|
||||||
if self.full():
|
|
||||||
_ = self.get()
|
|
||||||
return False
|
|
||||||
self.put(item)
|
|
||||||
return True
|
|
||||||
|
|
||||||
|
|
||||||
def read_labeled_img(dataset_dir: str, color_dict: dict, ext='.bmp', is_ps_color_space=True) -> dict:
|
|
||||||
"""
|
|
||||||
根据dataset_dir下的文件创建数据集
|
|
||||||
|
|
||||||
:param dataset_dir: 文件夹名称,文件夹内必须包含'label'和'label'两个文件夹,并分别存放同名的图像与标签
|
|
||||||
:param color_dict: 进行标签图像的颜色查找
|
|
||||||
:param ext: 图片后缀名,默认为.bmp
|
|
||||||
:param is_ps_color_space: 是否使用ps的标准lab色彩空间,默认True
|
|
||||||
:return: 字典形式的数据集{label: vector(n x 3)},vector为lab色彩空间
|
|
||||||
"""
|
|
||||||
img_names = [img_name for img_name in os.listdir(os.path.join(dataset_dir, 'label'))
|
|
||||||
if img_name.endswith(ext)]
|
|
||||||
total_dataset = MergeDict()
|
|
||||||
for img_name in img_names:
|
|
||||||
img_path, label_path = [os.path.join(dataset_dir, folder, img_name) for folder in ['img', 'label']]
|
|
||||||
# 读取图片和色彩空间转换
|
|
||||||
img = cv2.imread(img_path)
|
|
||||||
label_img = cv2.imread(label_path)
|
|
||||||
img = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
|
|
||||||
# 从opencv的色彩空间到Photoshop的色彩空间
|
|
||||||
if is_ps_color_space:
|
|
||||||
alpha, beta = np.array([100 / 255, 1, 1]), np.array([0, -128, -128])
|
|
||||||
img = img * alpha + beta
|
|
||||||
img = np.asarray(np.round(img, 0), dtype=int)
|
|
||||||
dataset = {label: img[np.all(label_img == color, axis=2)] for color, label in color_dict.items()}
|
|
||||||
total_dataset.merge(dataset)
|
|
||||||
return total_dataset
|
|
||||||
|
|
||||||
|
|
||||||
def lab_scatter(dataset: dict, class_max_num=None, is_3d=False, is_ps_color_space=True, **kwargs):
|
|
||||||
"""
|
|
||||||
在lab色彩空间内绘制3维数据分布情况
|
|
||||||
|
|
||||||
:param dataset: 字典形式的数据集{label: vector(n x 3)},vector为lab色彩空间
|
|
||||||
:param class_max_num: 每个类别最多画的样本数量,默认不限制
|
|
||||||
:param is_3d: 进行lab三维绘制或者a,b两通道绘制
|
|
||||||
:param is_ps_color_space: 是否使用ps的标准lab色彩空间,默认True
|
|
||||||
:return: None
|
|
||||||
"""
|
|
||||||
# 观察色彩分布情况
|
|
||||||
fig = plt.figure()
|
|
||||||
if is_3d:
|
|
||||||
ax = fig.add_subplot(projection='3d')
|
|
||||||
else:
|
|
||||||
ax = fig.add_subplot()
|
|
||||||
for label, data in dataset.items():
|
|
||||||
if class_max_num is not None:
|
|
||||||
assert isinstance(class_max_num, int)
|
|
||||||
if data.shape[0] > class_max_num:
|
|
||||||
sample_idx = np.arange(data.shape[0])
|
|
||||||
sample_idx = np.random.choice(sample_idx, class_max_num)
|
|
||||||
data = data[sample_idx, :]
|
|
||||||
l, a, b = [data[:, i] for i in range(3)]
|
|
||||||
if is_3d:
|
|
||||||
ax.scatter(a, b, l, label=label, alpha=0.1)
|
|
||||||
else:
|
|
||||||
ax.scatter(a, b, label=label, alpha=0.1)
|
|
||||||
x_max, x_min, y_max, y_min, z_max, z_min = [127, -127, 127, -127, 100, 0] if is_ps_color_space else \
|
|
||||||
[255, 0, 255, 0, 255, 0]
|
|
||||||
ax.set_xlim(x_min, x_max)
|
|
||||||
ax.set_ylim(y_min, y_max)
|
|
||||||
ax.set_xlabel('a*')
|
|
||||||
ax.set_ylabel('b*')
|
|
||||||
if is_3d:
|
|
||||||
ax.set_zlim(z_min, z_max)
|
|
||||||
ax.set_zlabel('L')
|
|
||||||
plt.legend()
|
|
||||||
plt.show()
|
|
||||||
|
|
||||||
|
|
||||||
def size_threshold(img, blk_size, threshold):
|
|
||||||
mask = img.reshape(img.shape[0], img.shape[1] // blk_size, blk_size).sum(axis=2). \
|
|
||||||
reshape(img.shape[0] // blk_size, blk_size, img.shape[1] // blk_size).sum(axis=1)
|
|
||||||
mask[mask <= threshold] = 0
|
|
||||||
mask[mask > threshold] = 1
|
|
||||||
return mask
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
|
||||||
color_dict = {(0, 0, 255): "yangeng", (255, 0, 0): "bejing", (0, 255, 0): "hongdianxian",
|
|
||||||
(255, 0, 255): "chengsebangbangtang", (0, 255, 255): "lvdianxian"}
|
|
||||||
dataset = read_labeled_img("data/dataset", color_dict=color_dict, is_ps_color_space=False)
|
|
||||||
lab_scatter(dataset, class_max_num=20000, is_3d=False, is_ps_color_space=False)
|
|
||||||
323
utils/__init__.py
Executable file
323
utils/__init__.py
Executable file
@ -0,0 +1,323 @@
|
|||||||
|
# -*- codeing = utf-8 -*-
|
||||||
|
# Time : 2022/7/18 9:46
|
||||||
|
# @Auther : zhouchao
|
||||||
|
# @File: utils.py
|
||||||
|
# @Software:PyCharm
|
||||||
|
import glob
|
||||||
|
import logging
|
||||||
|
import os
|
||||||
|
import pathlib
|
||||||
|
import time
|
||||||
|
from datetime import datetime
|
||||||
|
from queue import Queue
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
from numpy.random import default_rng
|
||||||
|
from matplotlib import pyplot as plt
|
||||||
|
import re
|
||||||
|
|
||||||
|
from config import Config
|
||||||
|
|
||||||
|
|
||||||
|
def natural_sort(l):
|
||||||
|
"""
|
||||||
|
自然排序
|
||||||
|
:param l: 待排序
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
convert = lambda text: int(text) if text.isdigit() else text.lower()
|
||||||
|
alphanum_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]
|
||||||
|
return sorted(l, key=alphanum_key)
|
||||||
|
|
||||||
|
|
||||||
|
class MergeDict(dict):
|
||||||
|
def __init__(self):
|
||||||
|
super(MergeDict, self).__init__()
|
||||||
|
|
||||||
|
def merge(self, merged: dict):
|
||||||
|
for k, v in merged.items():
|
||||||
|
if k not in self.keys():
|
||||||
|
self.update({k: v})
|
||||||
|
else:
|
||||||
|
original = self.__getitem__(k)
|
||||||
|
new_value = np.concatenate([original, v], axis=0)
|
||||||
|
self.update({k: new_value})
|
||||||
|
return self
|
||||||
|
|
||||||
|
|
||||||
|
class ImgQueue(Queue):
|
||||||
|
"""
|
||||||
|
A custom queue subclass that provides a :meth:`clear` method.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def clear(self):
|
||||||
|
"""
|
||||||
|
Clears all items from the queue.
|
||||||
|
"""
|
||||||
|
|
||||||
|
with self.mutex:
|
||||||
|
unfinished = self.unfinished_tasks - len(self.queue)
|
||||||
|
if unfinished <= 0:
|
||||||
|
if unfinished < 0:
|
||||||
|
raise ValueError('task_done() called too many times')
|
||||||
|
self.all_tasks_done.notify_all()
|
||||||
|
self.unfinished_tasks = unfinished
|
||||||
|
self.queue.clear()
|
||||||
|
self.not_full.notify_all()
|
||||||
|
|
||||||
|
def safe_put(self, item):
|
||||||
|
if self.full():
|
||||||
|
_ = self.get()
|
||||||
|
return False
|
||||||
|
self.put(item)
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
def read_labeled_img(dataset_dir: str, color_dict: dict, ext='.bmp', is_ps_color_space=True) -> dict:
|
||||||
|
"""
|
||||||
|
根据dataset_dir下的文件创建数据集
|
||||||
|
|
||||||
|
:param dataset_dir: 文件夹名称,文件夹内必须包含'label'和'label'两个文件夹,并分别存放同名的图像与标签
|
||||||
|
:param color_dict: 进行标签图像的颜色查找
|
||||||
|
:param ext: 图片后缀名,默认为.bmp
|
||||||
|
:param is_ps_color_space: 是否使用ps的标准lab色彩空间,默认True
|
||||||
|
:return: 字典形式的数据集{label: vector(n x 3)},vector为lab色彩空间
|
||||||
|
"""
|
||||||
|
img_names = [img_name for img_name in os.listdir(os.path.join(dataset_dir, 'label'))
|
||||||
|
if img_name.endswith(ext)]
|
||||||
|
total_dataset = MergeDict()
|
||||||
|
for img_name in img_names:
|
||||||
|
img_path, label_path = [os.path.join(dataset_dir, folder, img_name) for folder in ['img', 'label']]
|
||||||
|
# 读取图片和色彩空间转换
|
||||||
|
img = cv2.imread(img_path)
|
||||||
|
label_img = cv2.imread(label_path)
|
||||||
|
img = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
|
||||||
|
# 从opencv的色彩空间到Photoshop的色彩空间
|
||||||
|
if is_ps_color_space:
|
||||||
|
alpha, beta = np.array([100 / 255, 1, 1]), np.array([0, -128, -128])
|
||||||
|
img = img * alpha + beta
|
||||||
|
img = np.asarray(np.round(img, 0), dtype=int)
|
||||||
|
dataset = {label: img[np.all(label_img == color, axis=2)] for color, label in color_dict.items()}
|
||||||
|
total_dataset.merge(dataset)
|
||||||
|
return total_dataset
|
||||||
|
|
||||||
|
|
||||||
|
def lab_scatter(dataset: dict, class_max_num=None, is_3d=False, is_ps_color_space=True, **kwargs):
|
||||||
|
"""
|
||||||
|
在lab色彩空间内绘制3维数据分布情况
|
||||||
|
|
||||||
|
:param dataset: 字典形式的数据集{label: vector(n x 3)},vector为lab色彩空间
|
||||||
|
:param class_max_num: 每个类别最多画的样本数量,默认不限制
|
||||||
|
:param is_3d: 进行lab三维绘制或者a,b两通道绘制
|
||||||
|
:param is_ps_color_space: 是否使用ps的标准lab色彩空间,默认True
|
||||||
|
:return: None
|
||||||
|
"""
|
||||||
|
# 观察色彩分布情况
|
||||||
|
if "alpha" not in kwargs.keys():
|
||||||
|
kwargs["alpha"] = 0.1
|
||||||
|
if 'inside_alpha' in kwargs.keys():
|
||||||
|
inside_alpha = kwargs['inside_alpha']
|
||||||
|
else:
|
||||||
|
inside_alpha = kwargs["alpha"]
|
||||||
|
if 'outside_alpha' in kwargs.keys():
|
||||||
|
outside_alpha = kwargs['outside_alpha']
|
||||||
|
else:
|
||||||
|
outside_alpha = kwargs["alpha"]
|
||||||
|
fig = plt.figure()
|
||||||
|
if is_3d:
|
||||||
|
ax = fig.add_subplot(projection='3d')
|
||||||
|
else:
|
||||||
|
ax = fig.add_subplot()
|
||||||
|
for label, data in dataset.items():
|
||||||
|
if label == 'Inside':
|
||||||
|
alpha = inside_alpha
|
||||||
|
elif label == 'Outside':
|
||||||
|
alpha = outside_alpha
|
||||||
|
else:
|
||||||
|
alpha = kwargs["alpha"]
|
||||||
|
if class_max_num is not None:
|
||||||
|
assert isinstance(class_max_num, int)
|
||||||
|
if data.shape[0] > class_max_num:
|
||||||
|
sample_idx = np.arange(data.shape[0])
|
||||||
|
sample_idx = np.random.choice(sample_idx, class_max_num)
|
||||||
|
data = data[sample_idx, :]
|
||||||
|
l, a, b = [data[:, i] for i in range(3)]
|
||||||
|
if is_3d:
|
||||||
|
ax.scatter(a, b, l, label=label, alpha=alpha)
|
||||||
|
else:
|
||||||
|
ax.scatter(a, b, label=label, alpha=alpha)
|
||||||
|
x_max, x_min, y_max, y_min, z_max, z_min = [127, -127, 127, -127, 100, 0] if is_ps_color_space else \
|
||||||
|
[255, 0, 255, 0, 255, 0]
|
||||||
|
ax.set_xlim(x_min, x_max)
|
||||||
|
ax.set_ylim(y_min, y_max)
|
||||||
|
ax.set_xlabel('a*')
|
||||||
|
ax.set_ylabel('b*')
|
||||||
|
if is_3d:
|
||||||
|
ax.set_zlim(z_min, z_max)
|
||||||
|
ax.set_zlabel('L')
|
||||||
|
plt.legend()
|
||||||
|
plt.show()
|
||||||
|
|
||||||
|
|
||||||
|
def size_threshold(img, blk_size, threshold, last_end: np.ndarray = None) -> np.ndarray:
|
||||||
|
mask = img.reshape(img.shape[0], img.shape[1] // blk_size, blk_size).sum(axis=2). \
|
||||||
|
reshape(img.shape[0] // blk_size, blk_size, img.shape[1] // blk_size).sum(axis=1)
|
||||||
|
mask[mask <= threshold] = 0
|
||||||
|
mask[mask > threshold] = 1
|
||||||
|
if last_end is not None:
|
||||||
|
half_blk_size = blk_size // 2
|
||||||
|
assert (last_end.shape[0] == half_blk_size) and (last_end.shape[1] == img.shape[1])
|
||||||
|
mask_up = np.concatenate((last_end, img[:-half_blk_size, :]), axis=0)
|
||||||
|
mask_up_right = np.concatenate((mask_up[:, half_blk_size:],
|
||||||
|
np.zeros((img.shape[0], half_blk_size), dtype=np.uint8)), axis=1)
|
||||||
|
mask_up = size_threshold(mask_up, blk_size, threshold)
|
||||||
|
mask_up_right = size_threshold(mask_up_right, blk_size, threshold)
|
||||||
|
mask[:-1, :] = mask_up[1:, :]
|
||||||
|
mask[:-1, 1:] = mask_up_right[1:, :-1]
|
||||||
|
return mask
|
||||||
|
|
||||||
|
|
||||||
|
def valve_merge(img: np.ndarray, merge_size: int = 2) -> np.ndarray:
|
||||||
|
assert img.shape[1] % merge_size == 0 # 列数必须能够被整除
|
||||||
|
img_shape = (img.shape[1], img.shape[0])
|
||||||
|
img = img.reshape((img.shape[0], img.shape[1] // merge_size, merge_size))
|
||||||
|
img = np.sum(img, axis=2)
|
||||||
|
img[img > 0] = 1
|
||||||
|
img = cv2.resize(img.astype(np.uint8), dsize=img_shape)
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def valve_expend(img: np.ndarray) -> np.ndarray:
|
||||||
|
kernel = np.ones((1, Config.valve_horizontal_padding), np.uint8)
|
||||||
|
img = cv2.dilate(img, kernel, iterations=1)
|
||||||
|
return img
|
||||||
|
|
||||||
|
|
||||||
|
def shield_valve(mask: np.ndarray, left_shield: int = -1, right_shield: int = -1) -> np.asarray:
|
||||||
|
if (left_shield < mask.shape[1]) & (left_shield > 0):
|
||||||
|
mask[:, :left_shield] = 0
|
||||||
|
if (right_shield < mask.shape[1]) & (right_shield > 0):
|
||||||
|
mask[:, -right_shield:] = 0
|
||||||
|
return mask
|
||||||
|
|
||||||
|
|
||||||
|
def valve_limit(mask: np.ndarray, max_valve_num: int) -> np.ndarray:
|
||||||
|
"""
|
||||||
|
用于限制阀门同时开启个数的函数
|
||||||
|
:param mask: 阀门开启mask,0,1格式,每个1对应一个阀门
|
||||||
|
:param max_valve_num: 最大阀门数量
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
assert (max_valve_num >= 1) and (max_valve_num < 50)
|
||||||
|
row_valve_count = np.sum(mask, axis=1)
|
||||||
|
if np.any(row_valve_count > max_valve_num):
|
||||||
|
over_rows_idx = np.argwhere(row_valve_count > max_valve_num).ravel()
|
||||||
|
logging.warning(f'发现单行喷阀数量{len(over_rows_idx)}超过限制,已限制到最大许可值{max_valve_num}')
|
||||||
|
over_rows = mask[over_rows_idx, :]
|
||||||
|
|
||||||
|
# a simple function to get lucky valves when too many valves appear in the same line
|
||||||
|
def process_row(each_row):
|
||||||
|
valve_idx = np.argwhere(each_row > 0).ravel()
|
||||||
|
lucky_valve_idx = default_rng().choice(valve_idx, max_valve_num)
|
||||||
|
new_row = np.zeros_like(each_row)
|
||||||
|
new_row[lucky_valve_idx] = 1
|
||||||
|
return new_row
|
||||||
|
limited_rows = np.apply_along_axis(process_row, 1, over_rows)
|
||||||
|
mask[over_rows_idx] = limited_rows
|
||||||
|
return mask
|
||||||
|
|
||||||
|
|
||||||
|
def read_envi_ascii(file_name, save_xy=False, hdr_file_name=None):
|
||||||
|
"""
|
||||||
|
Read envi ascii file. Use ENVI ROI Tool -> File -> output ROIs to ASCII...
|
||||||
|
|
||||||
|
:param file_name: file name of ENVI ascii file
|
||||||
|
:param hdr_file_name: hdr file name for a "BANDS" vector in the output
|
||||||
|
:param save_xy: save the x, y position on the first two cols of the result vector
|
||||||
|
:return: dict {class_name: vector, ...}
|
||||||
|
"""
|
||||||
|
number_line_start_with = "; Number of ROIs: "
|
||||||
|
roi_name_start_with, roi_npts_start_with = "; ROI name: ", "; ROI npts: "
|
||||||
|
data_start_with = "; ID"
|
||||||
|
class_num, class_names, class_nums, vectors = 0, [], [], []
|
||||||
|
with open(file_name, 'r') as f:
|
||||||
|
for line_text in f:
|
||||||
|
if line_text.startswith(number_line_start_with):
|
||||||
|
class_num = int(line_text[len(number_line_start_with):])
|
||||||
|
elif line_text.startswith(roi_name_start_with):
|
||||||
|
class_names.append(line_text[len(roi_name_start_with):-1])
|
||||||
|
elif line_text.startswith(roi_npts_start_with):
|
||||||
|
class_nums.append(int(line_text[len(roi_name_start_with):-1]))
|
||||||
|
elif line_text.startswith(data_start_with):
|
||||||
|
col_list = list(filter(None, line_text[1:].split(" ")))
|
||||||
|
assert (len(class_names) == class_num) and (len(class_names) == len(class_nums))
|
||||||
|
break
|
||||||
|
elif line_text.startswith(";"):
|
||||||
|
continue
|
||||||
|
for vector_rows in class_nums:
|
||||||
|
vector_str = ''
|
||||||
|
for i in range(vector_rows):
|
||||||
|
vector_str += f.readline()
|
||||||
|
vector = np.fromstring(vector_str, dtype=np.float, sep=" ").reshape(-1, len(col_list))
|
||||||
|
assert vector.shape[0] == vector_rows
|
||||||
|
vector = vector[:, 3:] if not save_xy else vector[:, 1:]
|
||||||
|
vectors.append(vector)
|
||||||
|
f.readline() # suppose to read a blank line
|
||||||
|
if hdr_file_name is not None:
|
||||||
|
bands = []
|
||||||
|
with open(hdr_file_name, 'r') as f:
|
||||||
|
start_bands = False
|
||||||
|
for line_text in f:
|
||||||
|
if start_bands:
|
||||||
|
if line_text.endswith(",\n"):
|
||||||
|
bands.append(float(line_text[:-2]))
|
||||||
|
else:
|
||||||
|
bands.append(float(line_text))
|
||||||
|
break
|
||||||
|
elif line_text.startswith("wavelength ="):
|
||||||
|
start_bands = True
|
||||||
|
bands = np.array(bands, dtype=np.float)
|
||||||
|
vectors.append(bands)
|
||||||
|
class_names.append("BANDS")
|
||||||
|
return dict(zip(class_names, vectors))
|
||||||
|
|
||||||
|
|
||||||
|
def generate_hdr(des='File Imported into ENVI.'):
|
||||||
|
template_file = f"""ENVI
|
||||||
|
description = {{ {des}
|
||||||
|
}}
|
||||||
|
samples = {Config.nCols}
|
||||||
|
lines = {Config.nRows}
|
||||||
|
bands = {Config.nBands}
|
||||||
|
header offset = 0
|
||||||
|
file type = ENVI Standard
|
||||||
|
data type = 4
|
||||||
|
interleave = bil
|
||||||
|
sensor type = Unknown
|
||||||
|
byte order = 0
|
||||||
|
wavelength units = Unknown
|
||||||
|
"""
|
||||||
|
return template_file
|
||||||
|
|
||||||
|
|
||||||
|
def valve_log(log_path: pathlib.Path, valve_num: [int, str]):
|
||||||
|
"""
|
||||||
|
将喷阀的开启次数记录到文件log_path当中。
|
||||||
|
"""
|
||||||
|
valve_str = "截至 " + datetime.now().strftime('%Y-%m-%d %H:%M:%S') + f' 喷阀使用次数: {valve_num}.'
|
||||||
|
with open(log_path, "a") as f:
|
||||||
|
f.write(str(valve_str) + "\n")
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
# color_dict = {(0, 0, 255): "yangeng", (255, 0, 0): "bejing", (0, 255, 0): "hongdianxian",
|
||||||
|
# (255, 0, 255): "chengsebangbangtang", (0, 255, 255): "lvdianxian"}
|
||||||
|
# dataset = read_labeled_img("data/dataset", color_dict=color_dict, is_ps_color_space=False)
|
||||||
|
# lab_scatter(dataset, class_max_num=20000, is_3d=False, is_ps_color_space=False)
|
||||||
|
a = np.array([[1, 1, 0, 0, 1, 0, 0, 1], [0, 0, 1, 0, 0, 1, 1, 1]]).astype(np.uint8)
|
||||||
|
# a.repeat(3, axis=0)
|
||||||
|
# b = valve_merge(a, 2)
|
||||||
|
# print(b)
|
||||||
|
c = valve_expend(a)
|
||||||
|
print(c)
|
||||||
101
utils/activations.py
Normal file
101
utils/activations.py
Normal file
@ -0,0 +1,101 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Activation functions
|
||||||
|
"""
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
|
||||||
|
# SiLU https://arxiv.org/pdf/1606.08415.pdf ----------------------------------------------------------------------------
|
||||||
|
class SiLU(nn.Module): # export-friendly version of nn.SiLU()
|
||||||
|
@staticmethod
|
||||||
|
def forward(x):
|
||||||
|
return x * torch.sigmoid(x)
|
||||||
|
|
||||||
|
|
||||||
|
class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
|
||||||
|
@staticmethod
|
||||||
|
def forward(x):
|
||||||
|
# return x * F.hardsigmoid(x) # for TorchScript and CoreML
|
||||||
|
return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
|
||||||
|
|
||||||
|
|
||||||
|
# Mish https://github.com/digantamisra98/Mish --------------------------------------------------------------------------
|
||||||
|
class Mish(nn.Module):
|
||||||
|
@staticmethod
|
||||||
|
def forward(x):
|
||||||
|
return x * F.softplus(x).tanh()
|
||||||
|
|
||||||
|
|
||||||
|
class MemoryEfficientMish(nn.Module):
|
||||||
|
class F(torch.autograd.Function):
|
||||||
|
@staticmethod
|
||||||
|
def forward(ctx, x):
|
||||||
|
ctx.save_for_backward(x)
|
||||||
|
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def backward(ctx, grad_output):
|
||||||
|
x = ctx.saved_tensors[0]
|
||||||
|
sx = torch.sigmoid(x)
|
||||||
|
fx = F.softplus(x).tanh()
|
||||||
|
return grad_output * (fx + x * sx * (1 - fx * fx))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return self.F.apply(x)
|
||||||
|
|
||||||
|
|
||||||
|
# FReLU https://arxiv.org/abs/2007.11824 -------------------------------------------------------------------------------
|
||||||
|
class FReLU(nn.Module):
|
||||||
|
def __init__(self, c1, k=3): # ch_in, kernel
|
||||||
|
super().__init__()
|
||||||
|
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
|
||||||
|
self.bn = nn.BatchNorm2d(c1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
return torch.max(x, self.bn(self.conv(x)))
|
||||||
|
|
||||||
|
|
||||||
|
# ACON https://arxiv.org/pdf/2009.04759.pdf ----------------------------------------------------------------------------
|
||||||
|
class AconC(nn.Module):
|
||||||
|
r""" ACON activation (activate or not).
|
||||||
|
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
|
||||||
|
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, c1):
|
||||||
|
super().__init__()
|
||||||
|
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
|
||||||
|
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
|
||||||
|
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
dpx = (self.p1 - self.p2) * x
|
||||||
|
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
|
||||||
|
|
||||||
|
|
||||||
|
class MetaAconC(nn.Module):
|
||||||
|
r""" ACON activation (activate or not).
|
||||||
|
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
|
||||||
|
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
|
||||||
|
super().__init__()
|
||||||
|
c2 = max(r, c1 // r)
|
||||||
|
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
|
||||||
|
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
|
||||||
|
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
|
||||||
|
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
|
||||||
|
# self.bn1 = nn.BatchNorm2d(c2)
|
||||||
|
# self.bn2 = nn.BatchNorm2d(c1)
|
||||||
|
|
||||||
|
def forward(self, x):
|
||||||
|
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
|
||||||
|
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
|
||||||
|
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
|
||||||
|
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
|
||||||
|
dpx = (self.p1 - self.p2) * x
|
||||||
|
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
|
||||||
277
utils/augmentations.py
Normal file
277
utils/augmentations.py
Normal file
@ -0,0 +1,277 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Image augmentation functions
|
||||||
|
"""
|
||||||
|
|
||||||
|
import math
|
||||||
|
import random
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from utils.general import LOGGER, check_version, colorstr, resample_segments, segment2box
|
||||||
|
from utils.metrics import bbox_ioa
|
||||||
|
|
||||||
|
|
||||||
|
class Albumentations:
|
||||||
|
# YOLOv5 Albumentations class (optional, only used if package is installed)
|
||||||
|
def __init__(self):
|
||||||
|
self.transform = None
|
||||||
|
try:
|
||||||
|
import albumentations as A
|
||||||
|
check_version(A.__version__, '1.0.3', hard=True) # version requirement
|
||||||
|
|
||||||
|
self.transform = A.Compose([
|
||||||
|
A.Blur(p=0.01),
|
||||||
|
A.MedianBlur(p=0.01),
|
||||||
|
A.ToGray(p=0.01),
|
||||||
|
A.CLAHE(p=0.01),
|
||||||
|
A.RandomBrightnessContrast(p=0.0),
|
||||||
|
A.RandomGamma(p=0.0),
|
||||||
|
A.ImageCompression(quality_lower=75, p=0.0)],
|
||||||
|
bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
|
||||||
|
|
||||||
|
LOGGER.info(colorstr('albumentations: ') + ', '.join(f'{x}' for x in self.transform.transforms if x.p))
|
||||||
|
except ImportError: # package not installed, skip
|
||||||
|
pass
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.info(colorstr('albumentations: ') + f'{e}')
|
||||||
|
|
||||||
|
def __call__(self, im, labels, p=1.0):
|
||||||
|
if self.transform and random.random() < p:
|
||||||
|
new = self.transform(image=im, bboxes=labels[:, 1:], class_labels=labels[:, 0]) # transformed
|
||||||
|
im, labels = new['image'], np.array([[c, *b] for c, b in zip(new['class_labels'], new['bboxes'])])
|
||||||
|
return im, labels
|
||||||
|
|
||||||
|
|
||||||
|
def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
|
||||||
|
# HSV color-space augmentation
|
||||||
|
if hgain or sgain or vgain:
|
||||||
|
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
|
||||||
|
hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
|
||||||
|
dtype = im.dtype # uint8
|
||||||
|
|
||||||
|
x = np.arange(0, 256, dtype=r.dtype)
|
||||||
|
lut_hue = ((x * r[0]) % 180).astype(dtype)
|
||||||
|
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
|
||||||
|
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
|
||||||
|
|
||||||
|
im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
|
||||||
|
cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
|
||||||
|
|
||||||
|
|
||||||
|
def hist_equalize(im, clahe=True, bgr=False):
|
||||||
|
# Equalize histogram on BGR image 'im' with im.shape(n,m,3) and range 0-255
|
||||||
|
yuv = cv2.cvtColor(im, cv2.COLOR_BGR2YUV if bgr else cv2.COLOR_RGB2YUV)
|
||||||
|
if clahe:
|
||||||
|
c = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
|
||||||
|
yuv[:, :, 0] = c.apply(yuv[:, :, 0])
|
||||||
|
else:
|
||||||
|
yuv[:, :, 0] = cv2.equalizeHist(yuv[:, :, 0]) # equalize Y channel histogram
|
||||||
|
return cv2.cvtColor(yuv, cv2.COLOR_YUV2BGR if bgr else cv2.COLOR_YUV2RGB) # convert YUV image to RGB
|
||||||
|
|
||||||
|
|
||||||
|
def replicate(im, labels):
|
||||||
|
# Replicate labels
|
||||||
|
h, w = im.shape[:2]
|
||||||
|
boxes = labels[:, 1:].astype(int)
|
||||||
|
x1, y1, x2, y2 = boxes.T
|
||||||
|
s = ((x2 - x1) + (y2 - y1)) / 2 # side length (pixels)
|
||||||
|
for i in s.argsort()[:round(s.size * 0.5)]: # smallest indices
|
||||||
|
x1b, y1b, x2b, y2b = boxes[i]
|
||||||
|
bh, bw = y2b - y1b, x2b - x1b
|
||||||
|
yc, xc = int(random.uniform(0, h - bh)), int(random.uniform(0, w - bw)) # offset x, y
|
||||||
|
x1a, y1a, x2a, y2a = [xc, yc, xc + bw, yc + bh]
|
||||||
|
im[y1a:y2a, x1a:x2a] = im[y1b:y2b, x1b:x2b] # im4[ymin:ymax, xmin:xmax]
|
||||||
|
labels = np.append(labels, [[labels[i, 0], x1a, y1a, x2a, y2a]], axis=0)
|
||||||
|
|
||||||
|
return im, labels
|
||||||
|
|
||||||
|
|
||||||
|
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
|
||||||
|
# Resize and pad image while meeting stride-multiple constraints
|
||||||
|
shape = im.shape[:2] # current shape [height, width]
|
||||||
|
if isinstance(new_shape, int):
|
||||||
|
new_shape = (new_shape, new_shape)
|
||||||
|
|
||||||
|
# Scale ratio (new / old)
|
||||||
|
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
|
||||||
|
if not scaleup: # only scale down, do not scale up (for better val mAP)
|
||||||
|
r = min(r, 1.0)
|
||||||
|
|
||||||
|
# Compute padding
|
||||||
|
ratio = r, r # width, height ratios
|
||||||
|
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
|
||||||
|
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
|
||||||
|
if auto: # minimum rectangle
|
||||||
|
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
|
||||||
|
elif scaleFill: # stretch
|
||||||
|
dw, dh = 0.0, 0.0
|
||||||
|
new_unpad = (new_shape[1], new_shape[0])
|
||||||
|
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
|
||||||
|
|
||||||
|
dw /= 2 # divide padding into 2 sides
|
||||||
|
dh /= 2
|
||||||
|
|
||||||
|
if shape[::-1] != new_unpad: # resize
|
||||||
|
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
|
||||||
|
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
||||||
|
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
||||||
|
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
|
||||||
|
return im, ratio, (dw, dh)
|
||||||
|
|
||||||
|
|
||||||
|
def random_perspective(im, targets=(), segments=(), degrees=10, translate=.1, scale=.1, shear=10, perspective=0.0,
|
||||||
|
border=(0, 0)):
|
||||||
|
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(0.1, 0.1), scale=(0.9, 1.1), shear=(-10, 10))
|
||||||
|
# targets = [cls, xyxy]
|
||||||
|
|
||||||
|
height = im.shape[0] + border[0] * 2 # shape(h,w,c)
|
||||||
|
width = im.shape[1] + border[1] * 2
|
||||||
|
|
||||||
|
# Center
|
||||||
|
C = np.eye(3)
|
||||||
|
C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
|
||||||
|
C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
|
||||||
|
|
||||||
|
# Perspective
|
||||||
|
P = np.eye(3)
|
||||||
|
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
|
||||||
|
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
|
||||||
|
|
||||||
|
# Rotation and Scale
|
||||||
|
R = np.eye(3)
|
||||||
|
a = random.uniform(-degrees, degrees)
|
||||||
|
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
|
||||||
|
s = random.uniform(1 - scale, 1 + scale)
|
||||||
|
# s = 2 ** random.uniform(-scale, scale)
|
||||||
|
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
|
||||||
|
|
||||||
|
# Shear
|
||||||
|
S = np.eye(3)
|
||||||
|
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
|
||||||
|
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
|
||||||
|
|
||||||
|
# Translation
|
||||||
|
T = np.eye(3)
|
||||||
|
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
|
||||||
|
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
|
||||||
|
|
||||||
|
# Combined rotation matrix
|
||||||
|
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
|
||||||
|
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
|
||||||
|
if perspective:
|
||||||
|
im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
|
||||||
|
else: # affine
|
||||||
|
im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
|
||||||
|
|
||||||
|
# Visualize
|
||||||
|
# import matplotlib.pyplot as plt
|
||||||
|
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
|
||||||
|
# ax[0].imshow(im[:, :, ::-1]) # base
|
||||||
|
# ax[1].imshow(im2[:, :, ::-1]) # warped
|
||||||
|
|
||||||
|
# Transform label coordinates
|
||||||
|
n = len(targets)
|
||||||
|
if n:
|
||||||
|
use_segments = any(x.any() for x in segments)
|
||||||
|
new = np.zeros((n, 4))
|
||||||
|
if use_segments: # warp segments
|
||||||
|
segments = resample_segments(segments) # upsample
|
||||||
|
for i, segment in enumerate(segments):
|
||||||
|
xy = np.ones((len(segment), 3))
|
||||||
|
xy[:, :2] = segment
|
||||||
|
xy = xy @ M.T # transform
|
||||||
|
xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
|
||||||
|
|
||||||
|
# clip
|
||||||
|
new[i] = segment2box(xy, width, height)
|
||||||
|
|
||||||
|
else: # warp boxes
|
||||||
|
xy = np.ones((n * 4, 3))
|
||||||
|
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
|
||||||
|
xy = xy @ M.T # transform
|
||||||
|
xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
|
||||||
|
|
||||||
|
# create new boxes
|
||||||
|
x = xy[:, [0, 2, 4, 6]]
|
||||||
|
y = xy[:, [1, 3, 5, 7]]
|
||||||
|
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
|
||||||
|
|
||||||
|
# clip
|
||||||
|
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
|
||||||
|
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
|
||||||
|
|
||||||
|
# filter candidates
|
||||||
|
i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10)
|
||||||
|
targets = targets[i]
|
||||||
|
targets[:, 1:5] = new[i]
|
||||||
|
|
||||||
|
return im, targets
|
||||||
|
|
||||||
|
|
||||||
|
def copy_paste(im, labels, segments, p=0.5):
|
||||||
|
# Implement Copy-Paste augmentation https://arxiv.org/abs/2012.07177, labels as nx5 np.array(cls, xyxy)
|
||||||
|
n = len(segments)
|
||||||
|
if p and n:
|
||||||
|
h, w, c = im.shape # height, width, channels
|
||||||
|
im_new = np.zeros(im.shape, np.uint8)
|
||||||
|
for j in random.sample(range(n), k=round(p * n)):
|
||||||
|
l, s = labels[j], segments[j]
|
||||||
|
box = w - l[3], l[2], w - l[1], l[4]
|
||||||
|
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
|
||||||
|
if (ioa < 0.30).all(): # allow 30% obscuration of existing labels
|
||||||
|
labels = np.concatenate((labels, [[l[0], *box]]), 0)
|
||||||
|
segments.append(np.concatenate((w - s[:, 0:1], s[:, 1:2]), 1))
|
||||||
|
cv2.drawContours(im_new, [segments[j].astype(np.int32)], -1, (255, 255, 255), cv2.FILLED)
|
||||||
|
|
||||||
|
result = cv2.bitwise_and(src1=im, src2=im_new)
|
||||||
|
result = cv2.flip(result, 1) # augment segments (flip left-right)
|
||||||
|
i = result > 0 # pixels to replace
|
||||||
|
# i[:, :] = result.max(2).reshape(h, w, 1) # act over ch
|
||||||
|
im[i] = result[i] # cv2.imwrite('debug.jpg', im) # debug
|
||||||
|
|
||||||
|
return im, labels, segments
|
||||||
|
|
||||||
|
|
||||||
|
def cutout(im, labels, p=0.5):
|
||||||
|
# Applies image cutout augmentation https://arxiv.org/abs/1708.04552
|
||||||
|
if random.random() < p:
|
||||||
|
h, w = im.shape[:2]
|
||||||
|
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
|
||||||
|
for s in scales:
|
||||||
|
mask_h = random.randint(1, int(h * s)) # create random masks
|
||||||
|
mask_w = random.randint(1, int(w * s))
|
||||||
|
|
||||||
|
# box
|
||||||
|
xmin = max(0, random.randint(0, w) - mask_w // 2)
|
||||||
|
ymin = max(0, random.randint(0, h) - mask_h // 2)
|
||||||
|
xmax = min(w, xmin + mask_w)
|
||||||
|
ymax = min(h, ymin + mask_h)
|
||||||
|
|
||||||
|
# apply random color mask
|
||||||
|
im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
|
||||||
|
|
||||||
|
# return unobscured labels
|
||||||
|
if len(labels) and s > 0.03:
|
||||||
|
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
|
||||||
|
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
|
||||||
|
labels = labels[ioa < 0.60] # remove >60% obscured labels
|
||||||
|
|
||||||
|
return labels
|
||||||
|
|
||||||
|
|
||||||
|
def mixup(im, labels, im2, labels2):
|
||||||
|
# Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
|
||||||
|
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
|
||||||
|
im = (im * r + im2 * (1 - r)).astype(np.uint8)
|
||||||
|
labels = np.concatenate((labels, labels2), 0)
|
||||||
|
return im, labels
|
||||||
|
|
||||||
|
|
||||||
|
def box_candidates(box1, box2, wh_thr=2, ar_thr=100, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
|
||||||
|
# Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
|
||||||
|
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
|
||||||
|
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
|
||||||
|
ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
|
||||||
|
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
|
||||||
165
utils/autoanchor.py
Normal file
165
utils/autoanchor.py
Normal file
@ -0,0 +1,165 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
AutoAnchor utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
import random
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import yaml
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from utils.general import LOGGER, colorstr, emojis
|
||||||
|
|
||||||
|
PREFIX = colorstr('AutoAnchor: ')
|
||||||
|
|
||||||
|
|
||||||
|
def check_anchor_order(m):
|
||||||
|
# Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
|
||||||
|
a = m.anchors.prod(-1).view(-1) # anchor area
|
||||||
|
da = a[-1] - a[0] # delta a
|
||||||
|
ds = m.stride[-1] - m.stride[0] # delta s
|
||||||
|
if da.sign() != ds.sign(): # same order
|
||||||
|
LOGGER.info(f'{PREFIX}Reversing anchor order')
|
||||||
|
m.anchors[:] = m.anchors.flip(0)
|
||||||
|
|
||||||
|
|
||||||
|
def check_anchors(dataset, model, thr=4.0, imgsz=640):
|
||||||
|
# Check anchor fit to data, recompute if necessary
|
||||||
|
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
|
||||||
|
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
|
||||||
|
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
|
||||||
|
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
|
||||||
|
|
||||||
|
def metric(k): # compute metric
|
||||||
|
r = wh[:, None] / k[None]
|
||||||
|
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
|
||||||
|
best = x.max(1)[0] # best_x
|
||||||
|
aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
|
||||||
|
bpr = (best > 1 / thr).float().mean() # best possible recall
|
||||||
|
return bpr, aat
|
||||||
|
|
||||||
|
anchors = m.anchors.clone() * m.stride.to(m.anchors.device).view(-1, 1, 1) # current anchors
|
||||||
|
bpr, aat = metric(anchors.cpu().view(-1, 2))
|
||||||
|
s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
|
||||||
|
if bpr > 0.98: # threshold to recompute
|
||||||
|
LOGGER.info(emojis(f'{s}Current anchors are a good fit to dataset ✅'))
|
||||||
|
else:
|
||||||
|
LOGGER.info(emojis(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...'))
|
||||||
|
na = m.anchors.numel() // 2 # number of anchors
|
||||||
|
try:
|
||||||
|
anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.info(f'{PREFIX}ERROR: {e}')
|
||||||
|
new_bpr = metric(anchors)[0]
|
||||||
|
if new_bpr > bpr: # replace anchors
|
||||||
|
anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
|
||||||
|
m.anchors[:] = anchors.clone().view_as(m.anchors) / m.stride.to(m.anchors.device).view(-1, 1, 1) # loss
|
||||||
|
check_anchor_order(m)
|
||||||
|
LOGGER.info(f'{PREFIX}New anchors saved to model. Update model *.yaml to use these anchors in the future.')
|
||||||
|
else:
|
||||||
|
LOGGER.info(f'{PREFIX}Original anchors better than new anchors. Proceeding with original anchors.')
|
||||||
|
|
||||||
|
|
||||||
|
def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
|
||||||
|
""" Creates kmeans-evolved anchors from training dataset
|
||||||
|
|
||||||
|
Arguments:
|
||||||
|
dataset: path to data.yaml, or a loaded dataset
|
||||||
|
n: number of anchors
|
||||||
|
img_size: image size used for training
|
||||||
|
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
|
||||||
|
gen: generations to evolve anchors using genetic algorithm
|
||||||
|
verbose: print all results
|
||||||
|
|
||||||
|
Return:
|
||||||
|
k: kmeans evolved anchors
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
from utils.autoanchor import *; _ = kmean_anchors()
|
||||||
|
"""
|
||||||
|
from scipy.cluster.vq import kmeans
|
||||||
|
|
||||||
|
npr = np.random
|
||||||
|
thr = 1 / thr
|
||||||
|
|
||||||
|
def metric(k, wh): # compute metrics
|
||||||
|
r = wh[:, None] / k[None]
|
||||||
|
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
|
||||||
|
# x = wh_iou(wh, torch.tensor(k)) # iou metric
|
||||||
|
return x, x.max(1)[0] # x, best_x
|
||||||
|
|
||||||
|
def anchor_fitness(k): # mutation fitness
|
||||||
|
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
|
||||||
|
return (best * (best > thr).float()).mean() # fitness
|
||||||
|
|
||||||
|
def print_results(k, verbose=True):
|
||||||
|
k = k[np.argsort(k.prod(1))] # sort small to large
|
||||||
|
x, best = metric(k, wh0)
|
||||||
|
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
|
||||||
|
s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
|
||||||
|
f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
|
||||||
|
f'past_thr={x[x > thr].mean():.3f}-mean: '
|
||||||
|
for i, x in enumerate(k):
|
||||||
|
s += '%i,%i, ' % (round(x[0]), round(x[1]))
|
||||||
|
if verbose:
|
||||||
|
LOGGER.info(s[:-2])
|
||||||
|
return k
|
||||||
|
|
||||||
|
if isinstance(dataset, str): # *.yaml file
|
||||||
|
with open(dataset, errors='ignore') as f:
|
||||||
|
data_dict = yaml.safe_load(f) # model dict
|
||||||
|
from utils.datasets import LoadImagesAndLabels
|
||||||
|
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
|
||||||
|
|
||||||
|
# Get label wh
|
||||||
|
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
|
||||||
|
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
|
||||||
|
|
||||||
|
# Filter
|
||||||
|
i = (wh0 < 3.0).any(1).sum()
|
||||||
|
if i:
|
||||||
|
LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found. {i} of {len(wh0)} labels are < 3 pixels in size.')
|
||||||
|
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
|
||||||
|
# wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
|
||||||
|
|
||||||
|
# Kmeans calculation
|
||||||
|
LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
|
||||||
|
s = wh.std(0) # sigmas for whitening
|
||||||
|
k = kmeans(wh / s, n, iter=30)[0] * s # points
|
||||||
|
if len(k) != n: # kmeans may return fewer points than requested if wh is insufficient or too similar
|
||||||
|
LOGGER.warning(f'{PREFIX}WARNING: scipy.cluster.vq.kmeans returned only {len(k)} of {n} requested points')
|
||||||
|
k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
|
||||||
|
wh = torch.tensor(wh, dtype=torch.float32) # filtered
|
||||||
|
wh0 = torch.tensor(wh0, dtype=torch.float32) # unfiltered
|
||||||
|
k = print_results(k, verbose=False)
|
||||||
|
|
||||||
|
# Plot
|
||||||
|
# k, d = [None] * 20, [None] * 20
|
||||||
|
# for i in tqdm(range(1, 21)):
|
||||||
|
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
|
||||||
|
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
|
||||||
|
# ax = ax.ravel()
|
||||||
|
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
|
||||||
|
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
|
||||||
|
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
|
||||||
|
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
|
||||||
|
# fig.savefig('wh.png', dpi=200)
|
||||||
|
|
||||||
|
# Evolve
|
||||||
|
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
|
||||||
|
pbar = tqdm(range(gen), desc=f'{PREFIX}Evolving anchors with Genetic Algorithm:') # progress bar
|
||||||
|
for _ in pbar:
|
||||||
|
v = np.ones(sh)
|
||||||
|
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
|
||||||
|
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
|
||||||
|
kg = (k.copy() * v).clip(min=2.0)
|
||||||
|
fg = anchor_fitness(kg)
|
||||||
|
if fg > f:
|
||||||
|
f, k = fg, kg.copy()
|
||||||
|
pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
|
||||||
|
if verbose:
|
||||||
|
print_results(k, verbose)
|
||||||
|
|
||||||
|
return print_results(k)
|
||||||
57
utils/autobatch.py
Normal file
57
utils/autobatch.py
Normal file
@ -0,0 +1,57 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Auto-batch utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
from copy import deepcopy
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from torch.cuda import amp
|
||||||
|
|
||||||
|
from utils.general import LOGGER, colorstr
|
||||||
|
from utils.torch_utils import profile
|
||||||
|
|
||||||
|
|
||||||
|
def check_train_batch_size(model, imgsz=640):
|
||||||
|
# Check YOLOv5 training batch size
|
||||||
|
with amp.autocast():
|
||||||
|
return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
|
||||||
|
|
||||||
|
|
||||||
|
def autobatch(model, imgsz=640, fraction=0.9, batch_size=16):
|
||||||
|
# Automatically estimate best batch size to use `fraction` of available CUDA memory
|
||||||
|
# Usage:
|
||||||
|
# import torch
|
||||||
|
# from utils.autobatch import autobatch
|
||||||
|
# model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False)
|
||||||
|
# print(autobatch(model))
|
||||||
|
|
||||||
|
prefix = colorstr('AutoBatch: ')
|
||||||
|
LOGGER.info(f'{prefix}Computing optimal batch size for --imgsz {imgsz}')
|
||||||
|
device = next(model.parameters()).device # get model device
|
||||||
|
if device.type == 'cpu':
|
||||||
|
LOGGER.info(f'{prefix}CUDA not detected, using default CPU batch-size {batch_size}')
|
||||||
|
return batch_size
|
||||||
|
|
||||||
|
d = str(device).upper() # 'CUDA:0'
|
||||||
|
properties = torch.cuda.get_device_properties(device) # device properties
|
||||||
|
t = properties.total_memory / 1024 ** 3 # (GiB)
|
||||||
|
r = torch.cuda.memory_reserved(device) / 1024 ** 3 # (GiB)
|
||||||
|
a = torch.cuda.memory_allocated(device) / 1024 ** 3 # (GiB)
|
||||||
|
f = t - (r + a) # free inside reserved
|
||||||
|
LOGGER.info(f'{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
|
||||||
|
|
||||||
|
batch_sizes = [1, 2, 4, 8, 16]
|
||||||
|
try:
|
||||||
|
img = [torch.zeros(b, 3, imgsz, imgsz) for b in batch_sizes]
|
||||||
|
y = profile(img, model, n=3, device=device)
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.warning(f'{prefix}{e}')
|
||||||
|
|
||||||
|
y = [x[2] for x in y if x] # memory [2]
|
||||||
|
batch_sizes = batch_sizes[:len(y)]
|
||||||
|
p = np.polyfit(batch_sizes, y, deg=1) # first degree polynomial fit
|
||||||
|
b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
|
||||||
|
LOGGER.info(f'{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%)')
|
||||||
|
return b
|
||||||
92
utils/benchmarks.py
Normal file
92
utils/benchmarks.py
Normal file
@ -0,0 +1,92 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Run YOLOv5 benchmarks on all supported export formats
|
||||||
|
|
||||||
|
Format | `export.py --include` | Model
|
||||||
|
--- | --- | ---
|
||||||
|
PyTorch | - | yolov5s.pt
|
||||||
|
TorchScript | `torchscript` | yolov5s.torchscript
|
||||||
|
ONNX | `onnx` | yolov5s.onnx
|
||||||
|
OpenVINO | `openvino` | yolov5s_openvino_model/
|
||||||
|
TensorRT | `engine` | yolov5s.engine
|
||||||
|
CoreML | `coreml` | yolov5s.mlmodel
|
||||||
|
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
|
||||||
|
TensorFlow GraphDef | `pb` | yolov5s.pb
|
||||||
|
TensorFlow Lite | `tflite` | yolov5s.tflite
|
||||||
|
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
|
||||||
|
TensorFlow.js | `tfjs` | yolov5s_web_model/
|
||||||
|
|
||||||
|
Requirements:
|
||||||
|
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
|
||||||
|
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
$ python utils/benchmarks.py --weights yolov5s.pt --img 640
|
||||||
|
"""
|
||||||
|
|
||||||
|
import argparse
|
||||||
|
import sys
|
||||||
|
import time
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
FILE = Path(__file__).resolve()
|
||||||
|
ROOT = FILE.parents[1] # YOLOv5 root directory
|
||||||
|
if str(ROOT) not in sys.path:
|
||||||
|
sys.path.append(str(ROOT)) # add ROOT to PATH
|
||||||
|
# ROOT = ROOT.relative_to(Path.cwd()) # relative
|
||||||
|
|
||||||
|
import export
|
||||||
|
import val
|
||||||
|
from utils import notebook_init
|
||||||
|
from utils.general import LOGGER, print_args
|
||||||
|
|
||||||
|
|
||||||
|
def run(weights=ROOT / 'yolov5s.pt', # weights path
|
||||||
|
imgsz=640, # inference size (pixels)
|
||||||
|
batch_size=1, # batch size
|
||||||
|
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
|
||||||
|
):
|
||||||
|
y, t = [], time.time()
|
||||||
|
formats = export.export_formats()
|
||||||
|
for i, (name, f, suffix) in formats.iterrows(): # index, (name, file, suffix)
|
||||||
|
try:
|
||||||
|
w = weights if f == '-' else export.run(weights=weights, imgsz=[imgsz], include=[f], device='cpu')[-1]
|
||||||
|
assert suffix in str(w), 'export failed'
|
||||||
|
result = val.run(data, w, batch_size, imgsz=imgsz, plots=False, device='cpu', task='benchmark')
|
||||||
|
metrics = result[0] # metrics (mp, mr, map50, map, *losses(box, obj, cls))
|
||||||
|
speeds = result[2] # times (preprocess, inference, postprocess)
|
||||||
|
y.append([name, metrics[3], speeds[1]]) # mAP, t_inference
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.warning(f'WARNING: Benchmark failure for {name}: {e}')
|
||||||
|
y.append([name, None, None]) # mAP, t_inference
|
||||||
|
|
||||||
|
# Print results
|
||||||
|
LOGGER.info('\n')
|
||||||
|
parse_opt()
|
||||||
|
notebook_init() # print system info
|
||||||
|
py = pd.DataFrame(y, columns=['Format', 'mAP@0.5:0.95', 'Inference time (ms)'])
|
||||||
|
LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
|
||||||
|
LOGGER.info(str(py))
|
||||||
|
return py
|
||||||
|
|
||||||
|
|
||||||
|
def parse_opt():
|
||||||
|
parser = argparse.ArgumentParser()
|
||||||
|
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
|
||||||
|
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
|
||||||
|
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
|
||||||
|
opt = parser.parse_args()
|
||||||
|
print_args(FILE.stem, opt)
|
||||||
|
return opt
|
||||||
|
|
||||||
|
|
||||||
|
def main(opt):
|
||||||
|
run(**vars(opt))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
opt = parse_opt()
|
||||||
|
main(opt)
|
||||||
78
utils/callbacks.py
Normal file
78
utils/callbacks.py
Normal file
@ -0,0 +1,78 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Callback utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
|
||||||
|
class Callbacks:
|
||||||
|
""""
|
||||||
|
Handles all registered callbacks for YOLOv5 Hooks
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
# Define the available callbacks
|
||||||
|
self._callbacks = {
|
||||||
|
'on_pretrain_routine_start': [],
|
||||||
|
'on_pretrain_routine_end': [],
|
||||||
|
|
||||||
|
'on_train_start': [],
|
||||||
|
'on_train_epoch_start': [],
|
||||||
|
'on_train_batch_start': [],
|
||||||
|
'optimizer_step': [],
|
||||||
|
'on_before_zero_grad': [],
|
||||||
|
'on_train_batch_end': [],
|
||||||
|
'on_train_epoch_end': [],
|
||||||
|
|
||||||
|
'on_val_start': [],
|
||||||
|
'on_val_batch_start': [],
|
||||||
|
'on_val_image_end': [],
|
||||||
|
'on_val_batch_end': [],
|
||||||
|
'on_val_end': [],
|
||||||
|
|
||||||
|
'on_fit_epoch_end': [], # fit = train + val
|
||||||
|
'on_model_save': [],
|
||||||
|
'on_train_end': [],
|
||||||
|
'on_params_update': [],
|
||||||
|
'teardown': [],
|
||||||
|
}
|
||||||
|
self.stop_training = False # set True to interrupt training
|
||||||
|
|
||||||
|
def register_action(self, hook, name='', callback=None):
|
||||||
|
"""
|
||||||
|
Register a new action to a callback hook
|
||||||
|
|
||||||
|
Args:
|
||||||
|
hook The callback hook name to register the action to
|
||||||
|
name The name of the action for later reference
|
||||||
|
callback The callback to fire
|
||||||
|
"""
|
||||||
|
assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
|
||||||
|
assert callable(callback), f"callback '{callback}' is not callable"
|
||||||
|
self._callbacks[hook].append({'name': name, 'callback': callback})
|
||||||
|
|
||||||
|
def get_registered_actions(self, hook=None):
|
||||||
|
""""
|
||||||
|
Returns all the registered actions by callback hook
|
||||||
|
|
||||||
|
Args:
|
||||||
|
hook The name of the hook to check, defaults to all
|
||||||
|
"""
|
||||||
|
if hook:
|
||||||
|
return self._callbacks[hook]
|
||||||
|
else:
|
||||||
|
return self._callbacks
|
||||||
|
|
||||||
|
def run(self, hook, *args, **kwargs):
|
||||||
|
"""
|
||||||
|
Loop through the registered actions and fire all callbacks
|
||||||
|
|
||||||
|
Args:
|
||||||
|
hook The name of the hook to check, defaults to all
|
||||||
|
args Arguments to receive from YOLOv5
|
||||||
|
kwargs Keyword Arguments to receive from YOLOv5
|
||||||
|
"""
|
||||||
|
|
||||||
|
assert hook in self._callbacks, f"hook '{hook}' not found in callbacks {self._callbacks}"
|
||||||
|
|
||||||
|
for logger in self._callbacks[hook]:
|
||||||
|
logger['callback'](*args, **kwargs)
|
||||||
1092
utils/dataloaders.py
Normal file
1092
utils/dataloaders.py
Normal file
File diff suppressed because it is too large
Load Diff
1037
utils/datasets.py
Executable file
1037
utils/datasets.py
Executable file
File diff suppressed because it is too large
Load Diff
153
utils/downloads.py
Normal file
153
utils/downloads.py
Normal file
@ -0,0 +1,153 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Download utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os
|
||||||
|
import platform
|
||||||
|
import subprocess
|
||||||
|
import time
|
||||||
|
import urllib
|
||||||
|
from pathlib import Path
|
||||||
|
from zipfile import ZipFile
|
||||||
|
|
||||||
|
import requests
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
def gsutil_getsize(url=''):
|
||||||
|
# gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du
|
||||||
|
s = subprocess.check_output(f'gsutil du {url}', shell=True).decode('utf-8')
|
||||||
|
return eval(s.split(' ')[0]) if len(s) else 0 # bytes
|
||||||
|
|
||||||
|
|
||||||
|
def safe_download(file, url, url2=None, min_bytes=1E0, error_msg=''):
|
||||||
|
# Attempts to download file from url or url2, checks and removes incomplete downloads < min_bytes
|
||||||
|
file = Path(file)
|
||||||
|
assert_msg = f"Downloaded file '{file}' does not exist or size is < min_bytes={min_bytes}"
|
||||||
|
try: # url1
|
||||||
|
print(f'Downloading {url} to {file}...')
|
||||||
|
torch.hub.download_url_to_file(url, str(file))
|
||||||
|
assert file.exists() and file.stat().st_size > min_bytes, assert_msg # check
|
||||||
|
except Exception as e: # url2
|
||||||
|
file.unlink(missing_ok=True) # remove partial downloads
|
||||||
|
print(f'ERROR: {e}\nRe-attempting {url2 or url} to {file}...')
|
||||||
|
os.system(f"curl -L '{url2 or url}' -o '{file}' --retry 3 -C -") # curl download, retry and resume on fail
|
||||||
|
finally:
|
||||||
|
if not file.exists() or file.stat().st_size < min_bytes: # check
|
||||||
|
file.unlink(missing_ok=True) # remove partial downloads
|
||||||
|
print(f"ERROR: {assert_msg}\n{error_msg}")
|
||||||
|
print('')
|
||||||
|
|
||||||
|
|
||||||
|
def attempt_download(file, repo='ultralytics/yolov5'): # from utils.downloads import *; attempt_download()
|
||||||
|
# Attempt file download if does not exist
|
||||||
|
file = Path(str(file).strip().replace("'", ''))
|
||||||
|
|
||||||
|
if not file.exists():
|
||||||
|
# URL specified
|
||||||
|
name = Path(urllib.parse.unquote(str(file))).name # decode '%2F' to '/' etc.
|
||||||
|
if str(file).startswith(('http:/', 'https:/')): # download
|
||||||
|
url = str(file).replace(':/', '://') # Pathlib turns :// -> :/
|
||||||
|
file = name.split('?')[0] # parse authentication https://url.com/file.txt?auth...
|
||||||
|
if Path(file).is_file():
|
||||||
|
print(f'Found {url} locally at {file}') # file already exists
|
||||||
|
else:
|
||||||
|
safe_download(file=file, url=url, min_bytes=1E5)
|
||||||
|
return file
|
||||||
|
|
||||||
|
# GitHub assets
|
||||||
|
file.parent.mkdir(parents=True, exist_ok=True) # make parent dir (if required)
|
||||||
|
try:
|
||||||
|
response = requests.get(f'https://api.github.com/repos/{repo}/releases/latest').json() # github api
|
||||||
|
assets = [x['name'] for x in response['assets']] # release assets, i.e. ['yolov5s.pt', 'yolov5m.pt', ...]
|
||||||
|
tag = response['tag_name'] # i.e. 'v1.0'
|
||||||
|
except Exception: # fallback plan
|
||||||
|
assets = ['yolov5n.pt', 'yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt',
|
||||||
|
'yolov5n6.pt', 'yolov5s6.pt', 'yolov5m6.pt', 'yolov5l6.pt', 'yolov5x6.pt']
|
||||||
|
try:
|
||||||
|
tag = subprocess.check_output('git tag', shell=True, stderr=subprocess.STDOUT).decode().split()[-1]
|
||||||
|
except Exception:
|
||||||
|
tag = 'v6.0' # current release
|
||||||
|
|
||||||
|
if name in assets:
|
||||||
|
safe_download(file,
|
||||||
|
url=f'https://github.com/{repo}/releases/download/{tag}/{name}',
|
||||||
|
# url2=f'https://storage.googleapis.com/{repo}/ckpt/{name}', # backup url (optional)
|
||||||
|
min_bytes=1E5,
|
||||||
|
error_msg=f'{file} missing, try downloading from https://github.com/{repo}/releases/')
|
||||||
|
|
||||||
|
return str(file)
|
||||||
|
|
||||||
|
|
||||||
|
def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'):
|
||||||
|
# Downloads a file from Google Drive. from yolov5.utils.downloads import *; gdrive_download()
|
||||||
|
t = time.time()
|
||||||
|
file = Path(file)
|
||||||
|
cookie = Path('cookie') # gdrive cookie
|
||||||
|
print(f'Downloading https://drive.google.com/uc?export=download&id={id} as {file}... ', end='')
|
||||||
|
file.unlink(missing_ok=True) # remove existing file
|
||||||
|
cookie.unlink(missing_ok=True) # remove existing cookie
|
||||||
|
|
||||||
|
# Attempt file download
|
||||||
|
out = "NUL" if platform.system() == "Windows" else "/dev/null"
|
||||||
|
os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={id}" > {out}')
|
||||||
|
if os.path.exists('cookie'): # large file
|
||||||
|
s = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={get_token()}&id={id}" -o {file}'
|
||||||
|
else: # small file
|
||||||
|
s = f'curl -s -L -o {file} "drive.google.com/uc?export=download&id={id}"'
|
||||||
|
r = os.system(s) # execute, capture return
|
||||||
|
cookie.unlink(missing_ok=True) # remove existing cookie
|
||||||
|
|
||||||
|
# Error check
|
||||||
|
if r != 0:
|
||||||
|
file.unlink(missing_ok=True) # remove partial
|
||||||
|
print('Download error ') # raise Exception('Download error')
|
||||||
|
return r
|
||||||
|
|
||||||
|
# Unzip if archive
|
||||||
|
if file.suffix == '.zip':
|
||||||
|
print('unzipping... ', end='')
|
||||||
|
ZipFile(file).extractall(path=file.parent) # unzip
|
||||||
|
file.unlink() # remove zip
|
||||||
|
|
||||||
|
print(f'Done ({time.time() - t:.1f}s)')
|
||||||
|
return r
|
||||||
|
|
||||||
|
|
||||||
|
def get_token(cookie="./cookie"):
|
||||||
|
with open(cookie) as f:
|
||||||
|
for line in f:
|
||||||
|
if "download" in line:
|
||||||
|
return line.split()[-1]
|
||||||
|
return ""
|
||||||
|
|
||||||
|
# Google utils: https://cloud.google.com/storage/docs/reference/libraries ----------------------------------------------
|
||||||
|
#
|
||||||
|
#
|
||||||
|
# def upload_blob(bucket_name, source_file_name, destination_blob_name):
|
||||||
|
# # Uploads a file to a bucket
|
||||||
|
# # https://cloud.google.com/storage/docs/uploading-objects#storage-upload-object-python
|
||||||
|
#
|
||||||
|
# storage_client = storage.Client()
|
||||||
|
# bucket = storage_client.get_bucket(bucket_name)
|
||||||
|
# blob = bucket.blob(destination_blob_name)
|
||||||
|
#
|
||||||
|
# blob.upload_from_filename(source_file_name)
|
||||||
|
#
|
||||||
|
# print('File {} uploaded to {}.'.format(
|
||||||
|
# source_file_name,
|
||||||
|
# destination_blob_name))
|
||||||
|
#
|
||||||
|
#
|
||||||
|
# def download_blob(bucket_name, source_blob_name, destination_file_name):
|
||||||
|
# # Uploads a blob from a bucket
|
||||||
|
# storage_client = storage.Client()
|
||||||
|
# bucket = storage_client.get_bucket(bucket_name)
|
||||||
|
# blob = bucket.blob(source_blob_name)
|
||||||
|
#
|
||||||
|
# blob.download_to_filename(destination_file_name)
|
||||||
|
#
|
||||||
|
# print('Blob {} downloaded to {}.'.format(
|
||||||
|
# source_blob_name,
|
||||||
|
# destination_file_name))
|
||||||
880
utils/general.py
Executable file
880
utils/general.py
Executable file
@ -0,0 +1,880 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
General utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
import contextlib
|
||||||
|
import glob
|
||||||
|
import logging
|
||||||
|
import math
|
||||||
|
import os
|
||||||
|
import platform
|
||||||
|
import random
|
||||||
|
import re
|
||||||
|
import shutil
|
||||||
|
import signal
|
||||||
|
import time
|
||||||
|
import urllib
|
||||||
|
from itertools import repeat
|
||||||
|
from multiprocessing.pool import ThreadPool
|
||||||
|
from pathlib import Path
|
||||||
|
from subprocess import check_output
|
||||||
|
from zipfile import ZipFile
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
import pkg_resources as pkg
|
||||||
|
import torch
|
||||||
|
import torchvision
|
||||||
|
import yaml
|
||||||
|
|
||||||
|
from utils.downloads import gsutil_getsize
|
||||||
|
from utils.metrics import box_iou, fitness
|
||||||
|
|
||||||
|
# Settings
|
||||||
|
FILE = Path(__file__).resolve()
|
||||||
|
ROOT = FILE.parents[1] # YOLOv5 root directory
|
||||||
|
DATASETS_DIR = ROOT.parent / 'datasets' # YOLOv5 datasets directory
|
||||||
|
NUM_THREADS = min(8, max(1, os.cpu_count() - 1)) # number of YOLOv5 multiprocessing threads
|
||||||
|
VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true' # global verbose mode
|
||||||
|
FONT = 'Arial.ttf' # https://ultralytics.com/assets/Arial.ttf
|
||||||
|
|
||||||
|
torch.set_printoptions(linewidth=320, precision=5, profile='long')
|
||||||
|
np.set_printoptions(linewidth=320, formatter={'float_kind': '{:11.5g}'.format}) # format short g, %precision=5
|
||||||
|
pd.options.display.max_columns = 10
|
||||||
|
cv2.setNumThreads(0) # prevent OpenCV from multithreading (incompatible with PyTorch DataLoader)
|
||||||
|
os.environ['NUMEXPR_MAX_THREADS'] = str(NUM_THREADS) # NumExpr max threads
|
||||||
|
|
||||||
|
|
||||||
|
def is_kaggle():
|
||||||
|
# Is environment a Kaggle Notebook?
|
||||||
|
try:
|
||||||
|
assert os.environ.get('PWD') == '/kaggle/working'
|
||||||
|
assert os.environ.get('KAGGLE_URL_BASE') == 'https://www.kaggle.com'
|
||||||
|
return True
|
||||||
|
except AssertionError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def is_writeable(dir, test=False):
|
||||||
|
# Return True if directory has write permissions, test opening a file with write permissions if test=True
|
||||||
|
if test: # method 1
|
||||||
|
file = Path(dir) / 'tmp.txt'
|
||||||
|
try:
|
||||||
|
with open(file, 'w'): # open file with write permissions
|
||||||
|
pass
|
||||||
|
file.unlink() # remove file
|
||||||
|
return True
|
||||||
|
except OSError:
|
||||||
|
return False
|
||||||
|
else: # method 2
|
||||||
|
return os.access(dir, os.R_OK) # possible issues on Windows
|
||||||
|
|
||||||
|
|
||||||
|
def set_logging(name=None, verbose=VERBOSE):
|
||||||
|
# Sets level and returns logger
|
||||||
|
if is_kaggle():
|
||||||
|
for h in logging.root.handlers:
|
||||||
|
logging.root.removeHandler(h) # remove all handlers associated with the root logger object
|
||||||
|
rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
|
||||||
|
# logging.basicConfig(format="%(message)s", level=logging.INFO if (verbose and rank in (-1, 0)) else logging.WARNING)
|
||||||
|
return logging.getLogger(name)
|
||||||
|
|
||||||
|
|
||||||
|
LOGGER = set_logging('yolov5') # define globally (used in train.py, val.py, detect.py, etc.)
|
||||||
|
|
||||||
|
|
||||||
|
def user_config_dir(dir='Ultralytics', env_var='YOLOV5_CONFIG_DIR'):
|
||||||
|
# Return path of user configuration directory. Prefer environment variable if exists. Make dir if required.
|
||||||
|
env = os.getenv(env_var)
|
||||||
|
if env:
|
||||||
|
path = Path(env) # use environment variable
|
||||||
|
else:
|
||||||
|
cfg = {'Windows': 'AppData/Roaming', 'Linux': '.config', 'Darwin': 'Library/Application Support'} # 3 OS dirs
|
||||||
|
path = Path.home() / cfg.get(platform.system(), '') # OS-specific config dir
|
||||||
|
path = (path if is_writeable(path) else Path('/tmp')) / dir # GCP and AWS lambda fix, only /tmp is writeable
|
||||||
|
path.mkdir(exist_ok=True) # make if required
|
||||||
|
return path
|
||||||
|
|
||||||
|
|
||||||
|
CONFIG_DIR = user_config_dir() # Ultralytics settings dir
|
||||||
|
|
||||||
|
|
||||||
|
class Profile(contextlib.ContextDecorator):
|
||||||
|
# Usage: @Profile() decorator or 'with Profile():' context manager
|
||||||
|
def __enter__(self):
|
||||||
|
self.start = time.time()
|
||||||
|
|
||||||
|
def __exit__(self, type, value, traceback):
|
||||||
|
print(f'Profile results: {time.time() - self.start:.5f}s')
|
||||||
|
|
||||||
|
|
||||||
|
class Timeout(contextlib.ContextDecorator):
|
||||||
|
# Usage: @Timeout(seconds) decorator or 'with Timeout(seconds):' context manager
|
||||||
|
def __init__(self, seconds, *, timeout_msg='', suppress_timeout_errors=True):
|
||||||
|
self.seconds = int(seconds)
|
||||||
|
self.timeout_message = timeout_msg
|
||||||
|
self.suppress = bool(suppress_timeout_errors)
|
||||||
|
|
||||||
|
def _timeout_handler(self, signum, frame):
|
||||||
|
raise TimeoutError(self.timeout_message)
|
||||||
|
|
||||||
|
def __enter__(self):
|
||||||
|
signal.signal(signal.SIGALRM, self._timeout_handler) # Set handler for SIGALRM
|
||||||
|
signal.alarm(self.seconds) # start countdown for SIGALRM to be raised
|
||||||
|
|
||||||
|
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||||
|
signal.alarm(0) # Cancel SIGALRM if it's scheduled
|
||||||
|
if self.suppress and exc_type is TimeoutError: # Suppress TimeoutError
|
||||||
|
return True
|
||||||
|
|
||||||
|
|
||||||
|
class WorkingDirectory(contextlib.ContextDecorator):
|
||||||
|
# Usage: @WorkingDirectory(dir) decorator or 'with WorkingDirectory(dir):' context manager
|
||||||
|
def __init__(self, new_dir):
|
||||||
|
self.dir = new_dir # new dir
|
||||||
|
self.cwd = Path.cwd().resolve() # current dir
|
||||||
|
|
||||||
|
def __enter__(self):
|
||||||
|
os.chdir(self.dir)
|
||||||
|
|
||||||
|
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||||
|
os.chdir(self.cwd)
|
||||||
|
|
||||||
|
|
||||||
|
def try_except(func):
|
||||||
|
# try-except function. Usage: @try_except decorator
|
||||||
|
def handler(*args, **kwargs):
|
||||||
|
try:
|
||||||
|
func(*args, **kwargs)
|
||||||
|
except Exception as e:
|
||||||
|
print(e)
|
||||||
|
|
||||||
|
return handler
|
||||||
|
|
||||||
|
|
||||||
|
def methods(instance):
|
||||||
|
# Get class/instance methods
|
||||||
|
return [f for f in dir(instance) if callable(getattr(instance, f)) and not f.startswith("__")]
|
||||||
|
|
||||||
|
|
||||||
|
def print_args(name, opt):
|
||||||
|
# Print argparser arguments
|
||||||
|
LOGGER.info(colorstr(f'{name}: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
|
||||||
|
|
||||||
|
|
||||||
|
def init_seeds(seed=0):
|
||||||
|
# Initialize random number generator (RNG) seeds https://pytorch.org/docs/stable/notes/randomness.html
|
||||||
|
# cudnn seed 0 settings are slower and more reproducible, else faster and less reproducible
|
||||||
|
import torch.backends.cudnn as cudnn
|
||||||
|
random.seed(seed)
|
||||||
|
np.random.seed(seed)
|
||||||
|
torch.manual_seed(seed)
|
||||||
|
cudnn.benchmark, cudnn.deterministic = (False, True) if seed == 0 else (True, False)
|
||||||
|
|
||||||
|
|
||||||
|
def intersect_dicts(da, db, exclude=()):
|
||||||
|
# Dictionary intersection of matching keys and shapes, omitting 'exclude' keys, using da values
|
||||||
|
return {k: v for k, v in da.items() if k in db and not any(x in k for x in exclude) and v.shape == db[k].shape}
|
||||||
|
|
||||||
|
|
||||||
|
def get_latest_run(search_dir='.'):
|
||||||
|
# Return path to most recent 'last.pt' in /runs (i.e. to --resume from)
|
||||||
|
last_list = glob.glob(f'{search_dir}/**/last*.pt', recursive=True)
|
||||||
|
return max(last_list, key=os.path.getctime) if last_list else ''
|
||||||
|
|
||||||
|
|
||||||
|
def is_docker():
|
||||||
|
# Is environment a Docker container?
|
||||||
|
return Path('/workspace').exists() # or Path('/.dockerenv').exists()
|
||||||
|
|
||||||
|
|
||||||
|
def is_colab():
|
||||||
|
# Is environment a Google Colab instance?
|
||||||
|
try:
|
||||||
|
import google.colab
|
||||||
|
return True
|
||||||
|
except ImportError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def is_pip():
|
||||||
|
# Is file in a pip package?
|
||||||
|
return 'site-packages' in Path(__file__).resolve().parts
|
||||||
|
|
||||||
|
|
||||||
|
def is_ascii(s=''):
|
||||||
|
# Is string composed of all ASCII (no UTF) characters? (note str().isascii() introduced in python 3.7)
|
||||||
|
s = str(s) # convert list, tuple, None, etc. to str
|
||||||
|
return len(s.encode().decode('ascii', 'ignore')) == len(s)
|
||||||
|
|
||||||
|
|
||||||
|
def is_chinese(s='人工智能'):
|
||||||
|
# Is string composed of any Chinese characters?
|
||||||
|
return True if re.search('[\u4e00-\u9fff]', str(s)) else False
|
||||||
|
|
||||||
|
|
||||||
|
def emojis(str=''):
|
||||||
|
# Return platform-dependent emoji-safe version of string
|
||||||
|
return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
|
||||||
|
|
||||||
|
|
||||||
|
def file_size(path):
|
||||||
|
# Return file/dir size (MB)
|
||||||
|
path = Path(path)
|
||||||
|
if path.is_file():
|
||||||
|
return path.stat().st_size / 1E6
|
||||||
|
elif path.is_dir():
|
||||||
|
return sum(f.stat().st_size for f in path.glob('**/*') if f.is_file()) / 1E6
|
||||||
|
else:
|
||||||
|
return 0.0
|
||||||
|
|
||||||
|
|
||||||
|
def check_online():
|
||||||
|
# Check internet connectivity
|
||||||
|
import socket
|
||||||
|
try:
|
||||||
|
socket.create_connection(("1.1.1.1", 443), 5) # check host accessibility
|
||||||
|
return True
|
||||||
|
except OSError:
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
@try_except
|
||||||
|
@WorkingDirectory(ROOT)
|
||||||
|
def check_git_status():
|
||||||
|
# Recommend 'git pull' if code is out of date
|
||||||
|
msg = ', for updates see https://github.com/ultralytics/yolov5'
|
||||||
|
s = colorstr('github: ') # string
|
||||||
|
assert Path('.git').exists(), s + 'skipping check (not a git repository)' + msg
|
||||||
|
assert not is_docker(), s + 'skipping check (Docker image)' + msg
|
||||||
|
assert check_online(), s + 'skipping check (offline)' + msg
|
||||||
|
|
||||||
|
cmd = 'git fetch && git config --get remote.origin.url'
|
||||||
|
url = check_output(cmd, shell=True, timeout=5).decode().strip().rstrip('.git') # git fetch
|
||||||
|
branch = check_output('git rev-parse --abbrev-ref HEAD', shell=True).decode().strip() # checked out
|
||||||
|
n = int(check_output(f'git rev-list {branch}..origin/master --count', shell=True)) # commits behind
|
||||||
|
if n > 0:
|
||||||
|
s += f"⚠️ YOLOv5 is out of date by {n} commit{'s' * (n > 1)}. Use `git pull` or `git clone {url}` to update."
|
||||||
|
else:
|
||||||
|
s += f'up to date with {url} ✅'
|
||||||
|
LOGGER.info(emojis(s)) # emoji-safe
|
||||||
|
|
||||||
|
|
||||||
|
def check_python(minimum='3.6.2'):
|
||||||
|
# Check current python version vs. required python version
|
||||||
|
check_version(platform.python_version(), minimum, name='Python ', hard=True)
|
||||||
|
|
||||||
|
|
||||||
|
def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=False, hard=False, verbose=False):
|
||||||
|
# Check version vs. required version
|
||||||
|
current, minimum = (pkg.parse_version(x) for x in (current, minimum))
|
||||||
|
result = (current == minimum) if pinned else (current >= minimum) # bool
|
||||||
|
s = f'{name}{minimum} required by YOLOv5, but {name}{current} is currently installed' # string
|
||||||
|
if hard:
|
||||||
|
assert result, s # assert min requirements met
|
||||||
|
if verbose and not result:
|
||||||
|
LOGGER.warning(s)
|
||||||
|
return result
|
||||||
|
|
||||||
|
|
||||||
|
@try_except
|
||||||
|
def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True):
|
||||||
|
# Check installed dependencies meet requirements (pass *.txt file or list of packages)
|
||||||
|
prefix = colorstr('red', 'bold', 'requirements:')
|
||||||
|
check_python() # check python version
|
||||||
|
if isinstance(requirements, (str, Path)): # requirements.txt file
|
||||||
|
file = Path(requirements)
|
||||||
|
assert file.exists(), f"{prefix} {file.resolve()} not found, check failed."
|
||||||
|
with file.open() as f:
|
||||||
|
requirements = [f'{x.name}{x.specifier}' for x in pkg.parse_requirements(f) if x.name not in exclude]
|
||||||
|
else: # list or tuple of packages
|
||||||
|
requirements = [x for x in requirements if x not in exclude]
|
||||||
|
|
||||||
|
n = 0 # number of packages updates
|
||||||
|
for r in requirements:
|
||||||
|
try:
|
||||||
|
pkg.require(r)
|
||||||
|
except Exception: # DistributionNotFound or VersionConflict if requirements not met
|
||||||
|
s = f"{prefix} {r} not found and is required by YOLOv5"
|
||||||
|
if install:
|
||||||
|
LOGGER.info(f"{s}, attempting auto-update...")
|
||||||
|
try:
|
||||||
|
assert check_online(), f"'pip install {r}' skipped (offline)"
|
||||||
|
LOGGER.info(check_output(f"pip install '{r}'", shell=True).decode())
|
||||||
|
n += 1
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.warning(f'{prefix} {e}')
|
||||||
|
else:
|
||||||
|
LOGGER.info(f'{s}. Please install and rerun your command.')
|
||||||
|
|
||||||
|
if n: # if packages updated
|
||||||
|
source = file.resolve() if 'file' in locals() else requirements
|
||||||
|
s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
|
||||||
|
f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
|
||||||
|
LOGGER.info(emojis(s))
|
||||||
|
|
||||||
|
|
||||||
|
def check_img_size(imgsz, s=32, floor=0):
|
||||||
|
# Verify image size is a multiple of stride s in each dimension
|
||||||
|
if isinstance(imgsz, int): # integer i.e. img_size=640
|
||||||
|
new_size = max(make_divisible(imgsz, int(s)), floor)
|
||||||
|
else: # list i.e. img_size=[640, 480]
|
||||||
|
new_size = [max(make_divisible(x, int(s)), floor) for x in imgsz]
|
||||||
|
if new_size != imgsz:
|
||||||
|
LOGGER.warning(f'WARNING: --img-size {imgsz} must be multiple of max stride {s}, updating to {new_size}')
|
||||||
|
return new_size
|
||||||
|
|
||||||
|
|
||||||
|
def check_imshow():
|
||||||
|
# Check if environment supports image displays
|
||||||
|
try:
|
||||||
|
assert not is_docker(), 'cv2.imshow() is disabled in Docker environments'
|
||||||
|
assert not is_colab(), 'cv2.imshow() is disabled in Google Colab environments'
|
||||||
|
cv2.imshow('test', np.zeros((1, 1, 3)))
|
||||||
|
cv2.waitKey(1)
|
||||||
|
cv2.destroyAllWindows()
|
||||||
|
cv2.waitKey(1)
|
||||||
|
return True
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.warning(f'WARNING: Environment does not support cv2.imshow() or PIL Image.show() image displays\n{e}')
|
||||||
|
return False
|
||||||
|
|
||||||
|
|
||||||
|
def check_suffix(file='yolov5s.pt', suffix=('.pt',), msg=''):
|
||||||
|
# Check file(s) for acceptable suffix
|
||||||
|
if file and suffix:
|
||||||
|
if isinstance(suffix, str):
|
||||||
|
suffix = [suffix]
|
||||||
|
for f in file if isinstance(file, (list, tuple)) else [file]:
|
||||||
|
s = Path(f).suffix.lower() # file suffix
|
||||||
|
if len(s):
|
||||||
|
assert s in suffix, f"{msg}{f} acceptable suffix is {suffix}"
|
||||||
|
|
||||||
|
|
||||||
|
def check_yaml(file, suffix=('.yaml', '.yml')):
|
||||||
|
# Search/download YAML file (if necessary) and return path, checking suffix
|
||||||
|
return check_file(file, suffix)
|
||||||
|
|
||||||
|
|
||||||
|
def check_file(file, suffix=''):
|
||||||
|
# Search/download file (if necessary) and return path
|
||||||
|
check_suffix(file, suffix) # optional
|
||||||
|
file = str(file) # convert to str()
|
||||||
|
if Path(file).is_file() or file == '': # exists
|
||||||
|
return file
|
||||||
|
elif file.startswith(('http:/', 'https:/')): # download
|
||||||
|
url = str(Path(file)).replace(':/', '://') # Pathlib turns :// -> :/
|
||||||
|
file = Path(urllib.parse.unquote(file).split('?')[0]).name # '%2F' to '/', split https://url.com/file.txt?auth
|
||||||
|
if Path(file).is_file():
|
||||||
|
LOGGER.info(f'Found {url} locally at {file}') # file already exists
|
||||||
|
else:
|
||||||
|
LOGGER.info(f'Downloading {url} to {file}...')
|
||||||
|
torch.hub.download_url_to_file(url, file)
|
||||||
|
assert Path(file).exists() and Path(file).stat().st_size > 0, f'File download failed: {url}' # check
|
||||||
|
return file
|
||||||
|
else: # search
|
||||||
|
files = []
|
||||||
|
for d in 'data', 'models', 'utils': # search directories
|
||||||
|
files.extend(glob.glob(str(ROOT / d / '**' / file), recursive=True)) # find file
|
||||||
|
assert len(files), f'File not found: {file}' # assert file was found
|
||||||
|
assert len(files) == 1, f"Multiple files match '{file}', specify exact path: {files}" # assert unique
|
||||||
|
return files[0] # return file
|
||||||
|
|
||||||
|
|
||||||
|
def check_font(font=FONT):
|
||||||
|
# Download font to CONFIG_DIR if necessary
|
||||||
|
font = Path(font)
|
||||||
|
if not font.exists() and not (CONFIG_DIR / font.name).exists():
|
||||||
|
url = "https://ultralytics.com/assets/" + font.name
|
||||||
|
LOGGER.info(f'Downloading {url} to {CONFIG_DIR / font.name}...')
|
||||||
|
torch.hub.download_url_to_file(url, str(font), progress=False)
|
||||||
|
|
||||||
|
|
||||||
|
def check_dataset(data, autodownload=True):
|
||||||
|
# Download and/or unzip dataset if not found locally
|
||||||
|
# Usage: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128_with_yaml.zip
|
||||||
|
|
||||||
|
# Download (optional)
|
||||||
|
extract_dir = ''
|
||||||
|
if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
|
||||||
|
download(data, dir=DATASETS_DIR, unzip=True, delete=False, curl=False, threads=1)
|
||||||
|
data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
|
||||||
|
extract_dir, autodownload = data.parent, False
|
||||||
|
|
||||||
|
# Read yaml (optional)
|
||||||
|
if isinstance(data, (str, Path)):
|
||||||
|
with open(data, errors='ignore') as f:
|
||||||
|
data = yaml.safe_load(f) # dictionary
|
||||||
|
|
||||||
|
# Resolve paths
|
||||||
|
path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
|
||||||
|
if not path.is_absolute():
|
||||||
|
path = (ROOT / path).resolve()
|
||||||
|
for k in 'train', 'val', 'test':
|
||||||
|
if data.get(k): # prepend path
|
||||||
|
data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]
|
||||||
|
|
||||||
|
# Parse yaml
|
||||||
|
assert 'nc' in data, "Dataset 'nc' key missing."
|
||||||
|
if 'names' not in data:
|
||||||
|
data['names'] = [f'class{i}' for i in range(data['nc'])] # assign class names if missing
|
||||||
|
train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
|
||||||
|
if val:
|
||||||
|
val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
|
||||||
|
if not all(x.exists() for x in val):
|
||||||
|
LOGGER.info('\nDataset not found, missing paths: %s' % [str(x) for x in val if not x.exists()])
|
||||||
|
if s and autodownload: # download script
|
||||||
|
root = path.parent if 'path' in data else '..' # unzip directory i.e. '../'
|
||||||
|
if s.startswith('http') and s.endswith('.zip'): # URL
|
||||||
|
f = Path(s).name # filename
|
||||||
|
LOGGER.info(f'Downloading {s} to {f}...')
|
||||||
|
torch.hub.download_url_to_file(s, f)
|
||||||
|
Path(root).mkdir(parents=True, exist_ok=True) # create root
|
||||||
|
ZipFile(f).extractall(path=root) # unzip
|
||||||
|
Path(f).unlink() # remove zip
|
||||||
|
r = None # success
|
||||||
|
elif s.startswith('bash '): # bash script
|
||||||
|
LOGGER.info(f'Running {s} ...')
|
||||||
|
r = os.system(s)
|
||||||
|
else: # python script
|
||||||
|
r = exec(s, {'yaml': data}) # return None
|
||||||
|
LOGGER.info(f"Dataset autodownload {f'success, saved to {root}' if r in (0, None) else 'failure'}\n")
|
||||||
|
else:
|
||||||
|
raise Exception('Dataset not found.')
|
||||||
|
|
||||||
|
return data # dictionary
|
||||||
|
|
||||||
|
|
||||||
|
def url2file(url):
|
||||||
|
# Convert URL to filename, i.e. https://url.com/file.txt?auth -> file.txt
|
||||||
|
url = str(Path(url)).replace(':/', '://') # Pathlib turns :// -> :/
|
||||||
|
file = Path(urllib.parse.unquote(url)).name.split('?')[0] # '%2F' to '/', split https://url.com/file.txt?auth
|
||||||
|
return file
|
||||||
|
|
||||||
|
|
||||||
|
def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1):
|
||||||
|
# Multi-threaded file download and unzip function, used in data.yaml for autodownload
|
||||||
|
def download_one(url, dir):
|
||||||
|
# Download 1 file
|
||||||
|
f = dir / Path(url).name # filename
|
||||||
|
if Path(url).is_file(): # exists in current path
|
||||||
|
Path(url).rename(f) # move to dir
|
||||||
|
elif not f.exists():
|
||||||
|
LOGGER.info(f'Downloading {url} to {f}...')
|
||||||
|
if curl:
|
||||||
|
os.system(f"curl -L '{url}' -o '{f}' --retry 9 -C -") # curl download, retry and resume on fail
|
||||||
|
else:
|
||||||
|
torch.hub.download_url_to_file(url, f, progress=True) # torch download
|
||||||
|
if unzip and f.suffix in ('.zip', '.gz'):
|
||||||
|
LOGGER.info(f'Unzipping {f}...')
|
||||||
|
if f.suffix == '.zip':
|
||||||
|
ZipFile(f).extractall(path=dir) # unzip
|
||||||
|
elif f.suffix == '.gz':
|
||||||
|
os.system(f'tar xfz {f} --directory {f.parent}') # unzip
|
||||||
|
if delete:
|
||||||
|
f.unlink() # remove zip
|
||||||
|
|
||||||
|
dir = Path(dir)
|
||||||
|
dir.mkdir(parents=True, exist_ok=True) # make directory
|
||||||
|
if threads > 1:
|
||||||
|
pool = ThreadPool(threads)
|
||||||
|
pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multi-threaded
|
||||||
|
pool.close()
|
||||||
|
pool.join()
|
||||||
|
else:
|
||||||
|
for u in [url] if isinstance(url, (str, Path)) else url:
|
||||||
|
download_one(u, dir)
|
||||||
|
|
||||||
|
|
||||||
|
def make_divisible(x, divisor):
|
||||||
|
# Returns nearest x divisible by divisor
|
||||||
|
if isinstance(divisor, torch.Tensor):
|
||||||
|
divisor = int(divisor.max()) # to int
|
||||||
|
return math.ceil(x / divisor) * divisor
|
||||||
|
|
||||||
|
|
||||||
|
def clean_str(s):
|
||||||
|
# Cleans a string by replacing special characters with underscore _
|
||||||
|
return re.sub(pattern="[|@#!¡·$€%&()=?¿^*;:,¨´><+]", repl="_", string=s)
|
||||||
|
|
||||||
|
|
||||||
|
def one_cycle(y1=0.0, y2=1.0, steps=100):
|
||||||
|
# lambda function for sinusoidal ramp from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
|
||||||
|
return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
|
||||||
|
|
||||||
|
|
||||||
|
def colorstr(*input):
|
||||||
|
# Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
|
||||||
|
*args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
|
||||||
|
colors = {'black': '\033[30m', # basic colors
|
||||||
|
'red': '\033[31m',
|
||||||
|
'green': '\033[32m',
|
||||||
|
'yellow': '\033[33m',
|
||||||
|
'blue': '\033[34m',
|
||||||
|
'magenta': '\033[35m',
|
||||||
|
'cyan': '\033[36m',
|
||||||
|
'white': '\033[37m',
|
||||||
|
'bright_black': '\033[90m', # bright colors
|
||||||
|
'bright_red': '\033[91m',
|
||||||
|
'bright_green': '\033[92m',
|
||||||
|
'bright_yellow': '\033[93m',
|
||||||
|
'bright_blue': '\033[94m',
|
||||||
|
'bright_magenta': '\033[95m',
|
||||||
|
'bright_cyan': '\033[96m',
|
||||||
|
'bright_white': '\033[97m',
|
||||||
|
'end': '\033[0m', # misc
|
||||||
|
'bold': '\033[1m',
|
||||||
|
'underline': '\033[4m'}
|
||||||
|
return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
|
||||||
|
|
||||||
|
|
||||||
|
def labels_to_class_weights(labels, nc=80):
|
||||||
|
# Get class weights (inverse frequency) from training labels
|
||||||
|
if labels[0] is None: # no labels loaded
|
||||||
|
return torch.Tensor()
|
||||||
|
|
||||||
|
labels = np.concatenate(labels, 0) # labels.shape = (866643, 5) for COCO
|
||||||
|
classes = labels[:, 0].astype(np.int) # labels = [class xywh]
|
||||||
|
weights = np.bincount(classes, minlength=nc) # occurrences per class
|
||||||
|
|
||||||
|
# Prepend gridpoint count (for uCE training)
|
||||||
|
# gpi = ((320 / 32 * np.array([1, 2, 4])) ** 2 * 3).sum() # gridpoints per image
|
||||||
|
# weights = np.hstack([gpi * len(labels) - weights.sum() * 9, weights * 9]) ** 0.5 # prepend gridpoints to start
|
||||||
|
|
||||||
|
weights[weights == 0] = 1 # replace empty bins with 1
|
||||||
|
weights = 1 / weights # number of targets per class
|
||||||
|
weights /= weights.sum() # normalize
|
||||||
|
return torch.from_numpy(weights)
|
||||||
|
|
||||||
|
|
||||||
|
def labels_to_image_weights(labels, nc=80, class_weights=np.ones(80)):
|
||||||
|
# Produces image weights based on class_weights and image contents
|
||||||
|
class_counts = np.array([np.bincount(x[:, 0].astype(np.int), minlength=nc) for x in labels])
|
||||||
|
image_weights = (class_weights.reshape(1, nc) * class_counts).sum(1)
|
||||||
|
# index = random.choices(range(n), weights=image_weights, k=1) # weight image sample
|
||||||
|
return image_weights
|
||||||
|
|
||||||
|
|
||||||
|
def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
|
||||||
|
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
|
||||||
|
# a = np.loadtxt('data/coco.names', dtype='str', delimiter='\n')
|
||||||
|
# b = np.loadtxt('data/coco_paper.names', dtype='str', delimiter='\n')
|
||||||
|
# x1 = [list(a[i] == b).index(True) + 1 for i in range(80)] # darknet to coco
|
||||||
|
# x2 = [list(b[i] == a).index(True) if any(b[i] == a) else None for i in range(91)] # coco to darknet
|
||||||
|
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34,
|
||||||
|
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63,
|
||||||
|
64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
def xyxy2xywh(x):
|
||||||
|
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-right
|
||||||
|
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
||||||
|
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
|
||||||
|
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
|
||||||
|
y[:, 2] = x[:, 2] - x[:, 0] # width
|
||||||
|
y[:, 3] = x[:, 3] - x[:, 1] # height
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
def xywh2xyxy(x):
|
||||||
|
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
|
||||||
|
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
||||||
|
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
|
||||||
|
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
|
||||||
|
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
|
||||||
|
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
def xywhn2xyxy(x, w=640, h=640, padw=0, padh=0):
|
||||||
|
# Convert nx4 boxes from [x, y, w, h] normalized to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
|
||||||
|
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
||||||
|
y[:, 0] = w * (x[:, 0] - x[:, 2] / 2) + padw # top left x
|
||||||
|
y[:, 1] = h * (x[:, 1] - x[:, 3] / 2) + padh # top left y
|
||||||
|
y[:, 2] = w * (x[:, 0] + x[:, 2] / 2) + padw # bottom right x
|
||||||
|
y[:, 3] = h * (x[:, 1] + x[:, 3] / 2) + padh # bottom right y
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
def xyxy2xywhn(x, w=640, h=640, clip=False, eps=0.0):
|
||||||
|
# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] normalized where xy1=top-left, xy2=bottom-right
|
||||||
|
if clip:
|
||||||
|
clip_coords(x, (h - eps, w - eps)) # warning: inplace clip
|
||||||
|
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
||||||
|
y[:, 0] = ((x[:, 0] + x[:, 2]) / 2) / w # x center
|
||||||
|
y[:, 1] = ((x[:, 1] + x[:, 3]) / 2) / h # y center
|
||||||
|
y[:, 2] = (x[:, 2] - x[:, 0]) / w # width
|
||||||
|
y[:, 3] = (x[:, 3] - x[:, 1]) / h # height
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
def xyn2xy(x, w=640, h=640, padw=0, padh=0):
|
||||||
|
# Convert normalized segments into pixel segments, shape (n,2)
|
||||||
|
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
||||||
|
y[:, 0] = w * x[:, 0] + padw # top left x
|
||||||
|
y[:, 1] = h * x[:, 1] + padh # top left y
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
def segment2box(segment, width=640, height=640):
|
||||||
|
# Convert 1 segment label to 1 box label, applying inside-image constraint, i.e. (xy1, xy2, ...) to (xyxy)
|
||||||
|
x, y = segment.T # segment xy
|
||||||
|
inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
|
||||||
|
x, y, = x[inside], y[inside]
|
||||||
|
return np.array([x.min(), y.min(), x.max(), y.max()]) if any(x) else np.zeros((1, 4)) # xyxy
|
||||||
|
|
||||||
|
|
||||||
|
def segments2boxes(segments):
|
||||||
|
# Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
|
||||||
|
boxes = []
|
||||||
|
for s in segments:
|
||||||
|
x, y = s.T # segment xy
|
||||||
|
boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
|
||||||
|
return xyxy2xywh(np.array(boxes)) # cls, xywh
|
||||||
|
|
||||||
|
|
||||||
|
def resample_segments(segments, n=1000):
|
||||||
|
# Up-sample an (n,2) segment
|
||||||
|
for i, s in enumerate(segments):
|
||||||
|
x = np.linspace(0, len(s) - 1, n)
|
||||||
|
xp = np.arange(len(s))
|
||||||
|
segments[i] = np.concatenate([np.interp(x, xp, s[:, i]) for i in range(2)]).reshape(2, -1).T # segment xy
|
||||||
|
return segments
|
||||||
|
|
||||||
|
|
||||||
|
def scale_coords(img1_shape, coords, img0_shape, ratio_pad=None):
|
||||||
|
# Rescale coords (xyxy) from img1_shape to img0_shape
|
||||||
|
if ratio_pad is None: # calculate from img0_shape
|
||||||
|
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
|
||||||
|
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
|
||||||
|
else:
|
||||||
|
gain = ratio_pad[0][0]
|
||||||
|
pad = ratio_pad[1]
|
||||||
|
|
||||||
|
coords[:, [0, 2]] -= pad[0] # x padding
|
||||||
|
coords[:, [1, 3]] -= pad[1] # y padding
|
||||||
|
coords[:, :4] /= gain
|
||||||
|
clip_coords(coords, img0_shape)
|
||||||
|
return coords
|
||||||
|
|
||||||
|
|
||||||
|
def clip_coords(boxes, shape):
|
||||||
|
# Clip bounding xyxy bounding boxes to image shape (height, width)
|
||||||
|
if isinstance(boxes, torch.Tensor): # faster individually
|
||||||
|
boxes[:, 0].clamp_(0, shape[1]) # x1
|
||||||
|
boxes[:, 1].clamp_(0, shape[0]) # y1
|
||||||
|
boxes[:, 2].clamp_(0, shape[1]) # x2
|
||||||
|
boxes[:, 3].clamp_(0, shape[0]) # y2
|
||||||
|
else: # np.array (faster grouped)
|
||||||
|
boxes[:, [0, 2]] = boxes[:, [0, 2]].clip(0, shape[1]) # x1, x2
|
||||||
|
boxes[:, [1, 3]] = boxes[:, [1, 3]].clip(0, shape[0]) # y1, y2
|
||||||
|
|
||||||
|
|
||||||
|
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False,
|
||||||
|
labels=(), max_det=300):
|
||||||
|
"""Runs Non-Maximum Suppression (NMS) on inference results
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
|
||||||
|
"""
|
||||||
|
|
||||||
|
nc = prediction.shape[2] - 5 # number of classes
|
||||||
|
xc = prediction[..., 4] > conf_thres # candidates
|
||||||
|
|
||||||
|
# Checks
|
||||||
|
assert 0 <= conf_thres <= 1, f'Invalid Confidence threshold {conf_thres}, valid values are between 0.0 and 1.0'
|
||||||
|
assert 0 <= iou_thres <= 1, f'Invalid IoU {iou_thres}, valid values are between 0.0 and 1.0'
|
||||||
|
|
||||||
|
# Settings
|
||||||
|
min_wh, max_wh = 2, 7680 # (pixels) minimum and maximum box width and height
|
||||||
|
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
|
||||||
|
time_limit = 10.0 # seconds to quit after
|
||||||
|
redundant = True # require redundant detections
|
||||||
|
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
|
||||||
|
merge = False # use merge-NMS
|
||||||
|
|
||||||
|
t = time.time()
|
||||||
|
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0]
|
||||||
|
for xi, x in enumerate(prediction): # image index, image inference
|
||||||
|
# Apply constraints
|
||||||
|
x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
|
||||||
|
x = x[xc[xi]] # confidence
|
||||||
|
|
||||||
|
# Cat apriori labels if autolabelling
|
||||||
|
if labels and len(labels[xi]):
|
||||||
|
lb = labels[xi]
|
||||||
|
v = torch.zeros((len(lb), nc + 5), device=x.device)
|
||||||
|
v[:, :4] = lb[:, 1:5] # box
|
||||||
|
v[:, 4] = 1.0 # conf
|
||||||
|
v[range(len(lb)), lb[:, 0].long() + 5] = 1.0 # cls
|
||||||
|
x = torch.cat((x, v), 0)
|
||||||
|
|
||||||
|
# If none remain process next image
|
||||||
|
if not x.shape[0]:
|
||||||
|
continue
|
||||||
|
|
||||||
|
# Compute conf
|
||||||
|
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
|
||||||
|
|
||||||
|
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
|
||||||
|
box = xywh2xyxy(x[:, :4])
|
||||||
|
|
||||||
|
# Detections matrix nx6 (xyxy, conf, cls)
|
||||||
|
if multi_label:
|
||||||
|
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
|
||||||
|
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
|
||||||
|
else: # best class only
|
||||||
|
conf, j = x[:, 5:].max(1, keepdim=True)
|
||||||
|
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
|
||||||
|
|
||||||
|
# Filter by class
|
||||||
|
if classes is not None:
|
||||||
|
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
|
||||||
|
|
||||||
|
# Apply finite constraint
|
||||||
|
# if not torch.isfinite(x).all():
|
||||||
|
# x = x[torch.isfinite(x).all(1)]
|
||||||
|
|
||||||
|
# Check shape
|
||||||
|
n = x.shape[0] # number of boxes
|
||||||
|
if not n: # no boxes
|
||||||
|
continue
|
||||||
|
elif n > max_nms: # excess boxes
|
||||||
|
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
|
||||||
|
|
||||||
|
# Batched NMS
|
||||||
|
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
|
||||||
|
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
|
||||||
|
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS
|
||||||
|
if i.shape[0] > max_det: # limit detections
|
||||||
|
i = i[:max_det]
|
||||||
|
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
|
||||||
|
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
|
||||||
|
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
|
||||||
|
weights = iou * scores[None] # box weights
|
||||||
|
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
|
||||||
|
if redundant:
|
||||||
|
i = i[iou.sum(1) > 1] # require redundancy
|
||||||
|
|
||||||
|
output[xi] = x[i]
|
||||||
|
if (time.time() - t) > time_limit:
|
||||||
|
LOGGER.warning(f'WARNING: NMS time limit {time_limit}s exceeded')
|
||||||
|
break # time limit exceeded
|
||||||
|
|
||||||
|
return output
|
||||||
|
|
||||||
|
|
||||||
|
def strip_optimizer(f='best.pt', s=''): # from utils.general import *; strip_optimizer()
|
||||||
|
# Strip optimizer from 'f' to finalize training, optionally save as 's'
|
||||||
|
x = torch.load(f, map_location=torch.device('cpu'))
|
||||||
|
if x.get('ema'):
|
||||||
|
x['model'] = x['ema'] # replace model with ema
|
||||||
|
for k in 'optimizer', 'best_fitness', 'wandb_id', 'ema', 'updates': # keys
|
||||||
|
x[k] = None
|
||||||
|
x['epoch'] = -1
|
||||||
|
x['model'].half() # to FP16
|
||||||
|
for p in x['model'].parameters():
|
||||||
|
p.requires_grad = False
|
||||||
|
torch.save(x, s or f)
|
||||||
|
mb = os.path.getsize(s or f) / 1E6 # filesize
|
||||||
|
LOGGER.info(f"Optimizer stripped from {f},{(' saved as %s,' % s) if s else ''} {mb:.1f}MB")
|
||||||
|
|
||||||
|
|
||||||
|
def print_mutation(results, hyp, save_dir, bucket, prefix=colorstr('evolve: ')):
|
||||||
|
evolve_csv = save_dir / 'evolve.csv'
|
||||||
|
evolve_yaml = save_dir / 'hyp_evolve.yaml'
|
||||||
|
keys = ('metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
|
||||||
|
'val/box_loss', 'val/obj_loss', 'val/cls_loss') + tuple(hyp.keys()) # [results + hyps]
|
||||||
|
keys = tuple(x.strip() for x in keys)
|
||||||
|
vals = results + tuple(hyp.values())
|
||||||
|
n = len(keys)
|
||||||
|
|
||||||
|
# Download (optional)
|
||||||
|
if bucket:
|
||||||
|
url = f'gs://{bucket}/evolve.csv'
|
||||||
|
if gsutil_getsize(url) > (evolve_csv.stat().st_size if evolve_csv.exists() else 0):
|
||||||
|
os.system(f'gsutil cp {url} {save_dir}') # download evolve.csv if larger than local
|
||||||
|
|
||||||
|
# Log to evolve.csv
|
||||||
|
s = '' if evolve_csv.exists() else (('%20s,' * n % keys).rstrip(',') + '\n') # add header
|
||||||
|
with open(evolve_csv, 'a') as f:
|
||||||
|
f.write(s + ('%20.5g,' * n % vals).rstrip(',') + '\n')
|
||||||
|
|
||||||
|
# Save yaml
|
||||||
|
with open(evolve_yaml, 'w') as f:
|
||||||
|
data = pd.read_csv(evolve_csv)
|
||||||
|
data = data.rename(columns=lambda x: x.strip()) # strip keys
|
||||||
|
i = np.argmax(fitness(data.values[:, :4])) #
|
||||||
|
generations = len(data)
|
||||||
|
f.write('# YOLOv5 Hyperparameter Evolution Results\n' +
|
||||||
|
f'# Best generation: {i}\n' +
|
||||||
|
f'# Last generation: {generations - 1}\n' +
|
||||||
|
'# ' + ', '.join(f'{x.strip():>20s}' for x in keys[:7]) + '\n' +
|
||||||
|
'# ' + ', '.join(f'{x:>20.5g}' for x in data.values[i, :7]) + '\n\n')
|
||||||
|
yaml.safe_dump(data.loc[i][7:].to_dict(), f, sort_keys=False)
|
||||||
|
|
||||||
|
# Print to screen
|
||||||
|
LOGGER.info(prefix + f'{generations} generations finished, current result:\n' +
|
||||||
|
prefix + ', '.join(f'{x.strip():>20s}' for x in keys) + '\n' +
|
||||||
|
prefix + ', '.join(f'{x:20.5g}' for x in vals) + '\n\n')
|
||||||
|
|
||||||
|
if bucket:
|
||||||
|
os.system(f'gsutil cp {evolve_csv} {evolve_yaml} gs://{bucket}') # upload
|
||||||
|
|
||||||
|
|
||||||
|
def apply_classifier(x, model, img, im0):
|
||||||
|
# Apply a second stage classifier to YOLO outputs
|
||||||
|
# Example model = torchvision.models.__dict__['efficientnet_b0'](pretrained=True).to(device).eval()
|
||||||
|
im0 = [im0] if isinstance(im0, np.ndarray) else im0
|
||||||
|
for i, d in enumerate(x): # per image
|
||||||
|
if d is not None and len(d):
|
||||||
|
d = d.clone()
|
||||||
|
|
||||||
|
# Reshape and pad cutouts
|
||||||
|
b = xyxy2xywh(d[:, :4]) # boxes
|
||||||
|
b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # rectangle to square
|
||||||
|
b[:, 2:] = b[:, 2:] * 1.3 + 30 # pad
|
||||||
|
d[:, :4] = xywh2xyxy(b).long()
|
||||||
|
|
||||||
|
# Rescale boxes from img_size to im0 size
|
||||||
|
scale_coords(img.shape[2:], d[:, :4], im0[i].shape)
|
||||||
|
|
||||||
|
# Classes
|
||||||
|
pred_cls1 = d[:, 5].long()
|
||||||
|
ims = []
|
||||||
|
for j, a in enumerate(d): # per item
|
||||||
|
cutout = im0[i][int(a[1]):int(a[3]), int(a[0]):int(a[2])]
|
||||||
|
im = cv2.resize(cutout, (224, 224)) # BGR
|
||||||
|
# cv2.imwrite('example%i.jpg' % j, cutout)
|
||||||
|
|
||||||
|
im = im[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
|
||||||
|
im = np.ascontiguousarray(im, dtype=np.float32) # uint8 to float32
|
||||||
|
im /= 255 # 0 - 255 to 0.0 - 1.0
|
||||||
|
ims.append(im)
|
||||||
|
|
||||||
|
pred_cls2 = model(torch.Tensor(ims).to(d.device)).argmax(1) # classifier prediction
|
||||||
|
x[i] = x[i][pred_cls1 == pred_cls2] # retain matching class detections
|
||||||
|
|
||||||
|
return x
|
||||||
|
|
||||||
|
|
||||||
|
def increment_path(path, exist_ok=False, sep='', mkdir=False):
|
||||||
|
# Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
|
||||||
|
path = Path(path) # os-agnostic
|
||||||
|
if path.exists() and not exist_ok:
|
||||||
|
path, suffix = (path.with_suffix(''), path.suffix) if path.is_file() else (path, '')
|
||||||
|
dirs = glob.glob(f"{path}{sep}*") # similar paths
|
||||||
|
matches = [re.search(rf"%s{sep}(\d+)" % path.stem, d) for d in dirs]
|
||||||
|
i = [int(m.groups()[0]) for m in matches if m] # indices
|
||||||
|
n = max(i) + 1 if i else 2 # increment number
|
||||||
|
path = Path(f"{path}{sep}{n}{suffix}") # increment path
|
||||||
|
if mkdir:
|
||||||
|
path.mkdir(parents=True, exist_ok=True) # make directory
|
||||||
|
return path
|
||||||
|
|
||||||
|
|
||||||
|
# Variables
|
||||||
|
NCOLS = 0 if is_docker() else shutil.get_terminal_size().columns # terminal window size for tqdm
|
||||||
222
utils/loss.py
Normal file
222
utils/loss.py
Normal file
@ -0,0 +1,222 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Loss functions
|
||||||
|
"""
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
from utils.metrics import bbox_iou
|
||||||
|
from utils.torch_utils import de_parallel
|
||||||
|
|
||||||
|
|
||||||
|
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
|
||||||
|
# return positive, negative label smoothing BCE targets
|
||||||
|
return 1.0 - 0.5 * eps, 0.5 * eps
|
||||||
|
|
||||||
|
|
||||||
|
class BCEBlurWithLogitsLoss(nn.Module):
|
||||||
|
# BCEwithLogitLoss() with reduced missing label effects.
|
||||||
|
def __init__(self, alpha=0.05):
|
||||||
|
super().__init__()
|
||||||
|
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
|
||||||
|
self.alpha = alpha
|
||||||
|
|
||||||
|
def forward(self, pred, true):
|
||||||
|
loss = self.loss_fcn(pred, true)
|
||||||
|
pred = torch.sigmoid(pred) # prob from logits
|
||||||
|
dx = pred - true # reduce only missing label effects
|
||||||
|
# dx = (pred - true).abs() # reduce missing label and false label effects
|
||||||
|
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
|
||||||
|
loss *= alpha_factor
|
||||||
|
return loss.mean()
|
||||||
|
|
||||||
|
|
||||||
|
class FocalLoss(nn.Module):
|
||||||
|
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
|
||||||
|
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
|
||||||
|
super().__init__()
|
||||||
|
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
|
||||||
|
self.gamma = gamma
|
||||||
|
self.alpha = alpha
|
||||||
|
self.reduction = loss_fcn.reduction
|
||||||
|
self.loss_fcn.reduction = 'none' # required to apply FL to each element
|
||||||
|
|
||||||
|
def forward(self, pred, true):
|
||||||
|
loss = self.loss_fcn(pred, true)
|
||||||
|
# p_t = torch.exp(-loss)
|
||||||
|
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
|
||||||
|
|
||||||
|
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
|
||||||
|
pred_prob = torch.sigmoid(pred) # prob from logits
|
||||||
|
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
|
||||||
|
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
|
||||||
|
modulating_factor = (1.0 - p_t) ** self.gamma
|
||||||
|
loss *= alpha_factor * modulating_factor
|
||||||
|
|
||||||
|
if self.reduction == 'mean':
|
||||||
|
return loss.mean()
|
||||||
|
elif self.reduction == 'sum':
|
||||||
|
return loss.sum()
|
||||||
|
else: # 'none'
|
||||||
|
return loss
|
||||||
|
|
||||||
|
|
||||||
|
class QFocalLoss(nn.Module):
|
||||||
|
# Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
|
||||||
|
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
|
||||||
|
super().__init__()
|
||||||
|
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
|
||||||
|
self.gamma = gamma
|
||||||
|
self.alpha = alpha
|
||||||
|
self.reduction = loss_fcn.reduction
|
||||||
|
self.loss_fcn.reduction = 'none' # required to apply FL to each element
|
||||||
|
|
||||||
|
def forward(self, pred, true):
|
||||||
|
loss = self.loss_fcn(pred, true)
|
||||||
|
|
||||||
|
pred_prob = torch.sigmoid(pred) # prob from logits
|
||||||
|
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
|
||||||
|
modulating_factor = torch.abs(true - pred_prob) ** self.gamma
|
||||||
|
loss *= alpha_factor * modulating_factor
|
||||||
|
|
||||||
|
if self.reduction == 'mean':
|
||||||
|
return loss.mean()
|
||||||
|
elif self.reduction == 'sum':
|
||||||
|
return loss.sum()
|
||||||
|
else: # 'none'
|
||||||
|
return loss
|
||||||
|
|
||||||
|
|
||||||
|
class ComputeLoss:
|
||||||
|
# Compute losses
|
||||||
|
def __init__(self, model, autobalance=False):
|
||||||
|
self.sort_obj_iou = False
|
||||||
|
device = next(model.parameters()).device # get model device
|
||||||
|
h = model.hyp # hyperparameters
|
||||||
|
|
||||||
|
# Define criteria
|
||||||
|
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
|
||||||
|
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
|
||||||
|
|
||||||
|
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
|
||||||
|
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
|
||||||
|
|
||||||
|
# Focal loss
|
||||||
|
g = h['fl_gamma'] # focal loss gamma
|
||||||
|
if g > 0:
|
||||||
|
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
|
||||||
|
|
||||||
|
det = de_parallel(model).model[-1] # Detect() module
|
||||||
|
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
|
||||||
|
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
|
||||||
|
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
|
||||||
|
for k in 'na', 'nc', 'nl', 'anchors':
|
||||||
|
setattr(self, k, getattr(det, k))
|
||||||
|
|
||||||
|
def __call__(self, p, targets): # predictions, targets, model
|
||||||
|
device = targets.device
|
||||||
|
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
|
||||||
|
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
|
||||||
|
|
||||||
|
# Losses
|
||||||
|
for i, pi in enumerate(p): # layer index, layer predictions
|
||||||
|
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
|
||||||
|
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
|
||||||
|
|
||||||
|
n = b.shape[0] # number of targets
|
||||||
|
if n:
|
||||||
|
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
|
||||||
|
|
||||||
|
# Regression
|
||||||
|
pxy = ps[:, :2].sigmoid() * 2 - 0.5
|
||||||
|
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
|
||||||
|
pbox = torch.cat((pxy, pwh), 1) # predicted box
|
||||||
|
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
|
||||||
|
lbox += (1.0 - iou).mean() # iou loss
|
||||||
|
|
||||||
|
# Objectness
|
||||||
|
score_iou = iou.detach().clamp(0).type(tobj.dtype)
|
||||||
|
if self.sort_obj_iou:
|
||||||
|
sort_id = torch.argsort(score_iou)
|
||||||
|
b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
|
||||||
|
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
|
||||||
|
|
||||||
|
# Classification
|
||||||
|
if self.nc > 1: # cls loss (only if multiple classes)
|
||||||
|
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
|
||||||
|
t[range(n), tcls[i]] = self.cp
|
||||||
|
lcls += self.BCEcls(ps[:, 5:], t) # BCE
|
||||||
|
|
||||||
|
# Append targets to text file
|
||||||
|
# with open('targets.txt', 'a') as file:
|
||||||
|
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
|
||||||
|
|
||||||
|
obji = self.BCEobj(pi[..., 4], tobj)
|
||||||
|
lobj += obji * self.balance[i] # obj loss
|
||||||
|
if self.autobalance:
|
||||||
|
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
|
||||||
|
|
||||||
|
if self.autobalance:
|
||||||
|
self.balance = [x / self.balance[self.ssi] for x in self.balance]
|
||||||
|
lbox *= self.hyp['box']
|
||||||
|
lobj *= self.hyp['obj']
|
||||||
|
lcls *= self.hyp['cls']
|
||||||
|
bs = tobj.shape[0] # batch size
|
||||||
|
|
||||||
|
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
|
||||||
|
|
||||||
|
def build_targets(self, p, targets):
|
||||||
|
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
|
||||||
|
na, nt = self.na, targets.shape[0] # number of anchors, targets
|
||||||
|
tcls, tbox, indices, anch = [], [], [], []
|
||||||
|
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
|
||||||
|
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
|
||||||
|
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
|
||||||
|
|
||||||
|
g = 0.5 # bias
|
||||||
|
off = torch.tensor([[0, 0],
|
||||||
|
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
|
||||||
|
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
|
||||||
|
], device=targets.device).float() * g # offsets
|
||||||
|
|
||||||
|
for i in range(self.nl):
|
||||||
|
anchors = self.anchors[i]
|
||||||
|
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
|
||||||
|
|
||||||
|
# Match targets to anchors
|
||||||
|
t = targets * gain
|
||||||
|
if nt:
|
||||||
|
# Matches
|
||||||
|
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
|
||||||
|
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
|
||||||
|
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
|
||||||
|
t = t[j] # filter
|
||||||
|
|
||||||
|
# Offsets
|
||||||
|
gxy = t[:, 2:4] # grid xy
|
||||||
|
gxi = gain[[2, 3]] - gxy # inverse
|
||||||
|
j, k = ((gxy % 1 < g) & (gxy > 1)).T
|
||||||
|
l, m = ((gxi % 1 < g) & (gxi > 1)).T
|
||||||
|
j = torch.stack((torch.ones_like(j), j, k, l, m))
|
||||||
|
t = t.repeat((5, 1, 1))[j]
|
||||||
|
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
|
||||||
|
else:
|
||||||
|
t = targets[0]
|
||||||
|
offsets = 0
|
||||||
|
|
||||||
|
# Define
|
||||||
|
b, c = t[:, :2].long().T # image, class
|
||||||
|
gxy = t[:, 2:4] # grid xy
|
||||||
|
gwh = t[:, 4:6] # grid wh
|
||||||
|
gij = (gxy - offsets).long()
|
||||||
|
gi, gj = gij.T # grid xy indices
|
||||||
|
|
||||||
|
# Append
|
||||||
|
a = t[:, 6].long() # anchor indices
|
||||||
|
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
|
||||||
|
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
|
||||||
|
anch.append(anchors[a]) # anchors
|
||||||
|
tcls.append(c) # class
|
||||||
|
|
||||||
|
return tcls, tbox, indices, anch
|
||||||
342
utils/metrics.py
Normal file
342
utils/metrics.py
Normal file
@ -0,0 +1,342 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Model validation metrics
|
||||||
|
"""
|
||||||
|
|
||||||
|
import math
|
||||||
|
import warnings
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
def fitness(x):
|
||||||
|
# Model fitness as a weighted combination of metrics
|
||||||
|
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
|
||||||
|
return (x[:, :4] * w).sum(1)
|
||||||
|
|
||||||
|
|
||||||
|
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16):
|
||||||
|
""" Compute the average precision, given the recall and precision curves.
|
||||||
|
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
|
||||||
|
# Arguments
|
||||||
|
tp: True positives (nparray, nx1 or nx10).
|
||||||
|
conf: Objectness value from 0-1 (nparray).
|
||||||
|
pred_cls: Predicted object classes (nparray).
|
||||||
|
target_cls: True object classes (nparray).
|
||||||
|
plot: Plot precision-recall curve at mAP@0.5
|
||||||
|
save_dir: Plot save directory
|
||||||
|
# Returns
|
||||||
|
The average precision as computed in py-faster-rcnn.
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Sort by objectness
|
||||||
|
i = np.argsort(-conf)
|
||||||
|
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
|
||||||
|
|
||||||
|
# Find unique classes
|
||||||
|
unique_classes, nt = np.unique(target_cls, return_counts=True)
|
||||||
|
nc = unique_classes.shape[0] # number of classes, number of detections
|
||||||
|
|
||||||
|
# Create Precision-Recall curve and compute AP for each class
|
||||||
|
px, py = np.linspace(0, 1, 1000), [] # for plotting
|
||||||
|
ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
|
||||||
|
for ci, c in enumerate(unique_classes):
|
||||||
|
i = pred_cls == c
|
||||||
|
n_l = nt[ci] # number of labels
|
||||||
|
n_p = i.sum() # number of predictions
|
||||||
|
|
||||||
|
if n_p == 0 or n_l == 0:
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
# Accumulate FPs and TPs
|
||||||
|
fpc = (1 - tp[i]).cumsum(0)
|
||||||
|
tpc = tp[i].cumsum(0)
|
||||||
|
|
||||||
|
# Recall
|
||||||
|
recall = tpc / (n_l + eps) # recall curve
|
||||||
|
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
|
||||||
|
|
||||||
|
# Precision
|
||||||
|
precision = tpc / (tpc + fpc) # precision curve
|
||||||
|
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
|
||||||
|
|
||||||
|
# AP from recall-precision curve
|
||||||
|
for j in range(tp.shape[1]):
|
||||||
|
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
|
||||||
|
if plot and j == 0:
|
||||||
|
py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
|
||||||
|
|
||||||
|
# Compute F1 (harmonic mean of precision and recall)
|
||||||
|
f1 = 2 * p * r / (p + r + eps)
|
||||||
|
names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
|
||||||
|
names = {i: v for i, v in enumerate(names)} # to dict
|
||||||
|
if plot:
|
||||||
|
plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
|
||||||
|
plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
|
||||||
|
plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
|
||||||
|
plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
|
||||||
|
|
||||||
|
i = f1.mean(0).argmax() # max F1 index
|
||||||
|
p, r, f1 = p[:, i], r[:, i], f1[:, i]
|
||||||
|
tp = (r * nt).round() # true positives
|
||||||
|
fp = (tp / (p + eps) - tp).round() # false positives
|
||||||
|
return tp, fp, p, r, f1, ap, unique_classes.astype('int32')
|
||||||
|
|
||||||
|
|
||||||
|
def compute_ap(recall, precision):
|
||||||
|
""" Compute the average precision, given the recall and precision curves
|
||||||
|
# Arguments
|
||||||
|
recall: The recall curve (list)
|
||||||
|
precision: The precision curve (list)
|
||||||
|
# Returns
|
||||||
|
Average precision, precision curve, recall curve
|
||||||
|
"""
|
||||||
|
|
||||||
|
# Append sentinel values to beginning and end
|
||||||
|
mrec = np.concatenate(([0.0], recall, [1.0]))
|
||||||
|
mpre = np.concatenate(([1.0], precision, [0.0]))
|
||||||
|
|
||||||
|
# Compute the precision envelope
|
||||||
|
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
|
||||||
|
|
||||||
|
# Integrate area under curve
|
||||||
|
method = 'interp' # methods: 'continuous', 'interp'
|
||||||
|
if method == 'interp':
|
||||||
|
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
|
||||||
|
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
|
||||||
|
else: # 'continuous'
|
||||||
|
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
|
||||||
|
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
|
||||||
|
|
||||||
|
return ap, mpre, mrec
|
||||||
|
|
||||||
|
|
||||||
|
class ConfusionMatrix:
|
||||||
|
# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
|
||||||
|
def __init__(self, nc, conf=0.25, iou_thres=0.45):
|
||||||
|
self.matrix = np.zeros((nc + 1, nc + 1))
|
||||||
|
self.nc = nc # number of classes
|
||||||
|
self.conf = conf
|
||||||
|
self.iou_thres = iou_thres
|
||||||
|
|
||||||
|
def process_batch(self, detections, labels):
|
||||||
|
"""
|
||||||
|
Return intersection-over-union (Jaccard index) of boxes.
|
||||||
|
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
|
||||||
|
Arguments:
|
||||||
|
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
|
||||||
|
labels (Array[M, 5]), class, x1, y1, x2, y2
|
||||||
|
Returns:
|
||||||
|
None, updates confusion matrix accordingly
|
||||||
|
"""
|
||||||
|
detections = detections[detections[:, 4] > self.conf]
|
||||||
|
gt_classes = labels[:, 0].int()
|
||||||
|
detection_classes = detections[:, 5].int()
|
||||||
|
iou = box_iou(labels[:, 1:], detections[:, :4])
|
||||||
|
|
||||||
|
x = torch.where(iou > self.iou_thres)
|
||||||
|
if x[0].shape[0]:
|
||||||
|
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
|
||||||
|
if x[0].shape[0] > 1:
|
||||||
|
matches = matches[matches[:, 2].argsort()[::-1]]
|
||||||
|
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
|
||||||
|
matches = matches[matches[:, 2].argsort()[::-1]]
|
||||||
|
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
|
||||||
|
else:
|
||||||
|
matches = np.zeros((0, 3))
|
||||||
|
|
||||||
|
n = matches.shape[0] > 0
|
||||||
|
m0, m1, _ = matches.transpose().astype(np.int16)
|
||||||
|
for i, gc in enumerate(gt_classes):
|
||||||
|
j = m0 == i
|
||||||
|
if n and sum(j) == 1:
|
||||||
|
self.matrix[detection_classes[m1[j]], gc] += 1 # correct
|
||||||
|
else:
|
||||||
|
self.matrix[self.nc, gc] += 1 # background FP
|
||||||
|
|
||||||
|
if n:
|
||||||
|
for i, dc in enumerate(detection_classes):
|
||||||
|
if not any(m1 == i):
|
||||||
|
self.matrix[dc, self.nc] += 1 # background FN
|
||||||
|
|
||||||
|
def matrix(self):
|
||||||
|
return self.matrix
|
||||||
|
|
||||||
|
def tp_fp(self):
|
||||||
|
tp = self.matrix.diagonal() # true positives
|
||||||
|
fp = self.matrix.sum(1) - tp # false positives
|
||||||
|
# fn = self.matrix.sum(0) - tp # false negatives (missed detections)
|
||||||
|
return tp[:-1], fp[:-1] # remove background class
|
||||||
|
|
||||||
|
def plot(self, normalize=True, save_dir='', names=()):
|
||||||
|
try:
|
||||||
|
import seaborn as sn
|
||||||
|
|
||||||
|
array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
|
||||||
|
array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
|
||||||
|
|
||||||
|
fig = plt.figure(figsize=(12, 9), tight_layout=True)
|
||||||
|
nc, nn = self.nc, len(names) # number of classes, names
|
||||||
|
sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
|
||||||
|
labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
|
||||||
|
with warnings.catch_warnings():
|
||||||
|
warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
|
||||||
|
sn.heatmap(array, annot=nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True, vmin=0.0,
|
||||||
|
xticklabels=names + ['background FP'] if labels else "auto",
|
||||||
|
yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
|
||||||
|
fig.axes[0].set_xlabel('True')
|
||||||
|
fig.axes[0].set_ylabel('Predicted')
|
||||||
|
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
|
||||||
|
plt.close()
|
||||||
|
except Exception as e:
|
||||||
|
print(f'WARNING: ConfusionMatrix plot failure: {e}')
|
||||||
|
|
||||||
|
def print(self):
|
||||||
|
for i in range(self.nc + 1):
|
||||||
|
print(' '.join(map(str, self.matrix[i])))
|
||||||
|
|
||||||
|
|
||||||
|
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
|
||||||
|
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
|
||||||
|
box2 = box2.T
|
||||||
|
|
||||||
|
# Get the coordinates of bounding boxes
|
||||||
|
if x1y1x2y2: # x1, y1, x2, y2 = box1
|
||||||
|
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
|
||||||
|
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
|
||||||
|
else: # transform from xywh to xyxy
|
||||||
|
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
|
||||||
|
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
|
||||||
|
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
|
||||||
|
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
|
||||||
|
|
||||||
|
# Intersection area
|
||||||
|
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
|
||||||
|
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
|
||||||
|
|
||||||
|
# Union Area
|
||||||
|
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
|
||||||
|
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
|
||||||
|
union = w1 * h1 + w2 * h2 - inter + eps
|
||||||
|
|
||||||
|
iou = inter / union
|
||||||
|
if CIoU or DIoU or GIoU:
|
||||||
|
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
|
||||||
|
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
|
||||||
|
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
|
||||||
|
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
|
||||||
|
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
|
||||||
|
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
|
||||||
|
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
|
||||||
|
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
|
||||||
|
with torch.no_grad():
|
||||||
|
alpha = v / (v - iou + (1 + eps))
|
||||||
|
return iou - (rho2 / c2 + v * alpha) # CIoU
|
||||||
|
return iou - rho2 / c2 # DIoU
|
||||||
|
c_area = cw * ch + eps # convex area
|
||||||
|
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
|
||||||
|
return iou # IoU
|
||||||
|
|
||||||
|
|
||||||
|
def box_iou(box1, box2):
|
||||||
|
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
|
||||||
|
"""
|
||||||
|
Return intersection-over-union (Jaccard index) of boxes.
|
||||||
|
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
|
||||||
|
Arguments:
|
||||||
|
box1 (Tensor[N, 4])
|
||||||
|
box2 (Tensor[M, 4])
|
||||||
|
Returns:
|
||||||
|
iou (Tensor[N, M]): the NxM matrix containing the pairwise
|
||||||
|
IoU values for every element in boxes1 and boxes2
|
||||||
|
"""
|
||||||
|
|
||||||
|
def box_area(box):
|
||||||
|
# box = 4xn
|
||||||
|
return (box[2] - box[0]) * (box[3] - box[1])
|
||||||
|
|
||||||
|
area1 = box_area(box1.T)
|
||||||
|
area2 = box_area(box2.T)
|
||||||
|
|
||||||
|
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
|
||||||
|
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
|
||||||
|
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
|
||||||
|
|
||||||
|
|
||||||
|
def bbox_ioa(box1, box2, eps=1E-7):
|
||||||
|
""" Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
|
||||||
|
box1: np.array of shape(4)
|
||||||
|
box2: np.array of shape(nx4)
|
||||||
|
returns: np.array of shape(n)
|
||||||
|
"""
|
||||||
|
|
||||||
|
box2 = box2.transpose()
|
||||||
|
|
||||||
|
# Get the coordinates of bounding boxes
|
||||||
|
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
|
||||||
|
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
|
||||||
|
|
||||||
|
# Intersection area
|
||||||
|
inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
|
||||||
|
(np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
|
||||||
|
|
||||||
|
# box2 area
|
||||||
|
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
|
||||||
|
|
||||||
|
# Intersection over box2 area
|
||||||
|
return inter_area / box2_area
|
||||||
|
|
||||||
|
|
||||||
|
def wh_iou(wh1, wh2):
|
||||||
|
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
|
||||||
|
wh1 = wh1[:, None] # [N,1,2]
|
||||||
|
wh2 = wh2[None] # [1,M,2]
|
||||||
|
inter = torch.min(wh1, wh2).prod(2) # [N,M]
|
||||||
|
return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
|
||||||
|
|
||||||
|
|
||||||
|
# Plots ----------------------------------------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
|
||||||
|
# Precision-recall curve
|
||||||
|
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
|
||||||
|
py = np.stack(py, axis=1)
|
||||||
|
|
||||||
|
if 0 < len(names) < 21: # display per-class legend if < 21 classes
|
||||||
|
for i, y in enumerate(py.T):
|
||||||
|
ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
|
||||||
|
else:
|
||||||
|
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
|
||||||
|
|
||||||
|
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
|
||||||
|
ax.set_xlabel('Recall')
|
||||||
|
ax.set_ylabel('Precision')
|
||||||
|
ax.set_xlim(0, 1)
|
||||||
|
ax.set_ylim(0, 1)
|
||||||
|
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
|
||||||
|
fig.savefig(Path(save_dir), dpi=250)
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
|
||||||
|
def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
|
||||||
|
# Metric-confidence curve
|
||||||
|
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
|
||||||
|
|
||||||
|
if 0 < len(names) < 21: # display per-class legend if < 21 classes
|
||||||
|
for i, y in enumerate(py):
|
||||||
|
ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
|
||||||
|
else:
|
||||||
|
ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
|
||||||
|
|
||||||
|
y = py.mean(0)
|
||||||
|
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
|
||||||
|
ax.set_xlabel(xlabel)
|
||||||
|
ax.set_ylabel(ylabel)
|
||||||
|
ax.set_xlim(0, 1)
|
||||||
|
ax.set_ylim(0, 1)
|
||||||
|
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
|
||||||
|
fig.savefig(Path(save_dir), dpi=250)
|
||||||
|
plt.close()
|
||||||
471
utils/plots.py
Normal file
471
utils/plots.py
Normal file
@ -0,0 +1,471 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
Plotting utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
import math
|
||||||
|
import os
|
||||||
|
from copy import copy
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import matplotlib
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
import seaborn as sn
|
||||||
|
import torch
|
||||||
|
from PIL import Image, ImageDraw, ImageFont
|
||||||
|
|
||||||
|
from utils.general import (CONFIG_DIR, FONT, LOGGER, Timeout, check_font, check_requirements, clip_coords,
|
||||||
|
increment_path, is_ascii, is_chinese, try_except, xywh2xyxy, xyxy2xywh)
|
||||||
|
from utils.metrics import fitness
|
||||||
|
|
||||||
|
# Settings
|
||||||
|
RANK = int(os.getenv('RANK', -1))
|
||||||
|
matplotlib.rc('font', **{'size': 11})
|
||||||
|
matplotlib.use('Agg') # for writing to files only
|
||||||
|
|
||||||
|
|
||||||
|
class Colors:
|
||||||
|
# Ultralytics color palette https://ultralytics.com/
|
||||||
|
def __init__(self):
|
||||||
|
# hex = matplotlib.colors.TABLEAU_COLORS.values()
|
||||||
|
hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
|
||||||
|
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
|
||||||
|
self.palette = [self.hex2rgb('#' + c) for c in hex]
|
||||||
|
self.n = len(self.palette)
|
||||||
|
|
||||||
|
def __call__(self, i, bgr=False):
|
||||||
|
c = self.palette[int(i) % self.n]
|
||||||
|
return (c[2], c[1], c[0]) if bgr else c
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def hex2rgb(h): # rgb order (PIL)
|
||||||
|
return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
|
||||||
|
|
||||||
|
|
||||||
|
colors = Colors() # create instance for 'from utils.plots import colors'
|
||||||
|
|
||||||
|
|
||||||
|
def check_pil_font(font=FONT, size=10):
|
||||||
|
# Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
|
||||||
|
font = Path(font)
|
||||||
|
font = font if font.exists() else (CONFIG_DIR / font.name)
|
||||||
|
try:
|
||||||
|
return ImageFont.truetype(str(font) if font.exists() else font.name, size)
|
||||||
|
except Exception: # download if missing
|
||||||
|
check_font(font)
|
||||||
|
try:
|
||||||
|
return ImageFont.truetype(str(font), size)
|
||||||
|
except TypeError:
|
||||||
|
check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
|
||||||
|
|
||||||
|
|
||||||
|
class Annotator:
|
||||||
|
if RANK in (-1, 0):
|
||||||
|
check_pil_font() # download TTF if necessary
|
||||||
|
|
||||||
|
# YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
|
||||||
|
def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
|
||||||
|
assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
|
||||||
|
self.pil = pil or not is_ascii(example) or is_chinese(example)
|
||||||
|
if self.pil: # use PIL
|
||||||
|
self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
|
||||||
|
self.draw = ImageDraw.Draw(self.im)
|
||||||
|
self.font = check_pil_font(font='Arial.Unicode.ttf' if is_chinese(example) else font,
|
||||||
|
size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
|
||||||
|
else: # use cv2
|
||||||
|
self.im = im
|
||||||
|
self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
|
||||||
|
|
||||||
|
def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
|
||||||
|
# Add one xyxy box to image with label
|
||||||
|
if self.pil or not is_ascii(label):
|
||||||
|
self.draw.rectangle(box, width=self.lw, outline=color) # box
|
||||||
|
if label:
|
||||||
|
w, h = self.font.getsize(label) # text width, height
|
||||||
|
outside = box[1] - h >= 0 # label fits outside box
|
||||||
|
self.draw.rectangle((box[0],
|
||||||
|
box[1] - h if outside else box[1],
|
||||||
|
box[0] + w + 1,
|
||||||
|
box[1] + 1 if outside else box[1] + h + 1), fill=color)
|
||||||
|
# self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
|
||||||
|
self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
|
||||||
|
else: # cv2
|
||||||
|
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
|
||||||
|
cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
|
||||||
|
if label:
|
||||||
|
tf = max(self.lw - 1, 1) # font thickness
|
||||||
|
w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
|
||||||
|
outside = p1[1] - h - 3 >= 0 # label fits outside box
|
||||||
|
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
|
||||||
|
cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
|
||||||
|
cv2.putText(self.im, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, self.lw / 3, txt_color,
|
||||||
|
thickness=tf, lineType=cv2.LINE_AA)
|
||||||
|
|
||||||
|
def rectangle(self, xy, fill=None, outline=None, width=1):
|
||||||
|
# Add rectangle to image (PIL-only)
|
||||||
|
self.draw.rectangle(xy, fill, outline, width)
|
||||||
|
|
||||||
|
def text(self, xy, text, txt_color=(255, 255, 255)):
|
||||||
|
# Add text to image (PIL-only)
|
||||||
|
w, h = self.font.getsize(text) # text width, height
|
||||||
|
self.draw.text((xy[0], xy[1] - h + 1), text, fill=txt_color, font=self.font)
|
||||||
|
|
||||||
|
def result(self):
|
||||||
|
# Return annotated image as array
|
||||||
|
return np.asarray(self.im)
|
||||||
|
|
||||||
|
|
||||||
|
def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
|
||||||
|
"""
|
||||||
|
x: Features to be visualized
|
||||||
|
module_type: Module type
|
||||||
|
stage: Module stage within model
|
||||||
|
n: Maximum number of feature maps to plot
|
||||||
|
save_dir: Directory to save results
|
||||||
|
"""
|
||||||
|
if 'Detect' not in module_type:
|
||||||
|
batch, channels, height, width = x.shape # batch, channels, height, width
|
||||||
|
if height > 1 and width > 1:
|
||||||
|
f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
|
||||||
|
|
||||||
|
blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
|
||||||
|
n = min(n, channels) # number of plots
|
||||||
|
fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
|
||||||
|
ax = ax.ravel()
|
||||||
|
plt.subplots_adjust(wspace=0.05, hspace=0.05)
|
||||||
|
for i in range(n):
|
||||||
|
ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
|
||||||
|
ax[i].axis('off')
|
||||||
|
|
||||||
|
LOGGER.info(f'Saving {f}... ({n}/{channels})')
|
||||||
|
plt.savefig(f, dpi=300, bbox_inches='tight')
|
||||||
|
plt.close()
|
||||||
|
np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
|
||||||
|
|
||||||
|
|
||||||
|
def hist2d(x, y, n=100):
|
||||||
|
# 2d histogram used in labels.png and evolve.png
|
||||||
|
xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
|
||||||
|
hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
|
||||||
|
xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
|
||||||
|
yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
|
||||||
|
return np.log(hist[xidx, yidx])
|
||||||
|
|
||||||
|
|
||||||
|
def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
|
||||||
|
from scipy.signal import butter, filtfilt
|
||||||
|
|
||||||
|
# https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
|
||||||
|
def butter_lowpass(cutoff, fs, order):
|
||||||
|
nyq = 0.5 * fs
|
||||||
|
normal_cutoff = cutoff / nyq
|
||||||
|
return butter(order, normal_cutoff, btype='low', analog=False)
|
||||||
|
|
||||||
|
b, a = butter_lowpass(cutoff, fs, order=order)
|
||||||
|
return filtfilt(b, a, data) # forward-backward filter
|
||||||
|
|
||||||
|
|
||||||
|
def output_to_target(output):
|
||||||
|
# Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
|
||||||
|
targets = []
|
||||||
|
for i, o in enumerate(output):
|
||||||
|
for *box, conf, cls in o.cpu().numpy():
|
||||||
|
targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
|
||||||
|
return np.array(targets)
|
||||||
|
|
||||||
|
|
||||||
|
def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=1920, max_subplots=16):
|
||||||
|
# Plot image grid with labels
|
||||||
|
if isinstance(images, torch.Tensor):
|
||||||
|
images = images.cpu().float().numpy()
|
||||||
|
if isinstance(targets, torch.Tensor):
|
||||||
|
targets = targets.cpu().numpy()
|
||||||
|
if np.max(images[0]) <= 1:
|
||||||
|
images *= 255 # de-normalise (optional)
|
||||||
|
bs, _, h, w = images.shape # batch size, _, height, width
|
||||||
|
bs = min(bs, max_subplots) # limit plot images
|
||||||
|
ns = np.ceil(bs ** 0.5) # number of subplots (square)
|
||||||
|
|
||||||
|
# Build Image
|
||||||
|
mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
|
||||||
|
for i, im in enumerate(images):
|
||||||
|
if i == max_subplots: # if last batch has fewer images than we expect
|
||||||
|
break
|
||||||
|
x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
|
||||||
|
im = im.transpose(1, 2, 0)
|
||||||
|
mosaic[y:y + h, x:x + w, :] = im
|
||||||
|
|
||||||
|
# Resize (optional)
|
||||||
|
scale = max_size / ns / max(h, w)
|
||||||
|
if scale < 1:
|
||||||
|
h = math.ceil(scale * h)
|
||||||
|
w = math.ceil(scale * w)
|
||||||
|
mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
|
||||||
|
|
||||||
|
# Annotate
|
||||||
|
fs = int((h + w) * ns * 0.01) # font size
|
||||||
|
annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
|
||||||
|
for i in range(i + 1):
|
||||||
|
x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
|
||||||
|
annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
|
||||||
|
if paths:
|
||||||
|
annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
|
||||||
|
if len(targets) > 0:
|
||||||
|
ti = targets[targets[:, 0] == i] # image targets
|
||||||
|
boxes = xywh2xyxy(ti[:, 2:6]).T
|
||||||
|
classes = ti[:, 1].astype('int')
|
||||||
|
labels = ti.shape[1] == 6 # labels if no conf column
|
||||||
|
conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
|
||||||
|
|
||||||
|
if boxes.shape[1]:
|
||||||
|
if boxes.max() <= 1.01: # if normalized with tolerance 0.01
|
||||||
|
boxes[[0, 2]] *= w # scale to pixels
|
||||||
|
boxes[[1, 3]] *= h
|
||||||
|
elif scale < 1: # absolute coords need scale if image scales
|
||||||
|
boxes *= scale
|
||||||
|
boxes[[0, 2]] += x
|
||||||
|
boxes[[1, 3]] += y
|
||||||
|
for j, box in enumerate(boxes.T.tolist()):
|
||||||
|
cls = classes[j]
|
||||||
|
color = colors(cls)
|
||||||
|
cls = names[cls] if names else cls
|
||||||
|
if labels or conf[j] > 0.25: # 0.25 conf thresh
|
||||||
|
label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
|
||||||
|
annotator.box_label(box, label, color=color)
|
||||||
|
annotator.im.save(fname) # save
|
||||||
|
|
||||||
|
|
||||||
|
def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
|
||||||
|
# Plot LR simulating training for full epochs
|
||||||
|
optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
|
||||||
|
y = []
|
||||||
|
for _ in range(epochs):
|
||||||
|
scheduler.step()
|
||||||
|
y.append(optimizer.param_groups[0]['lr'])
|
||||||
|
plt.plot(y, '.-', label='LR')
|
||||||
|
plt.xlabel('epoch')
|
||||||
|
plt.ylabel('LR')
|
||||||
|
plt.grid()
|
||||||
|
plt.xlim(0, epochs)
|
||||||
|
plt.ylim(0)
|
||||||
|
plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
|
||||||
|
def plot_val_txt(): # from utils.plots import *; plot_val()
|
||||||
|
# Plot val.txt histograms
|
||||||
|
x = np.loadtxt('val.txt', dtype=np.float32)
|
||||||
|
box = xyxy2xywh(x[:, :4])
|
||||||
|
cx, cy = box[:, 0], box[:, 1]
|
||||||
|
|
||||||
|
fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
|
||||||
|
ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
|
||||||
|
ax.set_aspect('equal')
|
||||||
|
plt.savefig('hist2d.png', dpi=300)
|
||||||
|
|
||||||
|
fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
|
||||||
|
ax[0].hist(cx, bins=600)
|
||||||
|
ax[1].hist(cy, bins=600)
|
||||||
|
plt.savefig('hist1d.png', dpi=200)
|
||||||
|
|
||||||
|
|
||||||
|
def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
|
||||||
|
# Plot targets.txt histograms
|
||||||
|
x = np.loadtxt('targets.txt', dtype=np.float32).T
|
||||||
|
s = ['x targets', 'y targets', 'width targets', 'height targets']
|
||||||
|
fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
|
||||||
|
ax = ax.ravel()
|
||||||
|
for i in range(4):
|
||||||
|
ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
|
||||||
|
ax[i].legend()
|
||||||
|
ax[i].set_title(s[i])
|
||||||
|
plt.savefig('targets.jpg', dpi=200)
|
||||||
|
|
||||||
|
|
||||||
|
def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
|
||||||
|
# Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
|
||||||
|
save_dir = Path(file).parent if file else Path(dir)
|
||||||
|
plot2 = False # plot additional results
|
||||||
|
if plot2:
|
||||||
|
ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
|
||||||
|
|
||||||
|
fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
|
||||||
|
# for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
|
||||||
|
for f in sorted(save_dir.glob('study*.txt')):
|
||||||
|
y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
|
||||||
|
x = np.arange(y.shape[1]) if x is None else np.array(x)
|
||||||
|
if plot2:
|
||||||
|
s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
|
||||||
|
for i in range(7):
|
||||||
|
ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
|
||||||
|
ax[i].set_title(s[i])
|
||||||
|
|
||||||
|
j = y[3].argmax() + 1
|
||||||
|
ax2.plot(y[5, 1:j], y[3, 1:j] * 1E2, '.-', linewidth=2, markersize=8,
|
||||||
|
label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
|
||||||
|
|
||||||
|
ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
|
||||||
|
'k.-', linewidth=2, markersize=8, alpha=.25, label='EfficientDet')
|
||||||
|
|
||||||
|
ax2.grid(alpha=0.2)
|
||||||
|
ax2.set_yticks(np.arange(20, 60, 5))
|
||||||
|
ax2.set_xlim(0, 57)
|
||||||
|
ax2.set_ylim(25, 55)
|
||||||
|
ax2.set_xlabel('GPU Speed (ms/img)')
|
||||||
|
ax2.set_ylabel('COCO AP val')
|
||||||
|
ax2.legend(loc='lower right')
|
||||||
|
f = save_dir / 'study.png'
|
||||||
|
print(f'Saving {f}...')
|
||||||
|
plt.savefig(f, dpi=300)
|
||||||
|
|
||||||
|
|
||||||
|
@try_except # known issue https://github.com/ultralytics/yolov5/issues/5395
|
||||||
|
@Timeout(30) # known issue https://github.com/ultralytics/yolov5/issues/5611
|
||||||
|
def plot_labels(labels, names=(), save_dir=Path('')):
|
||||||
|
# plot dataset labels
|
||||||
|
LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
|
||||||
|
c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
|
||||||
|
nc = int(c.max() + 1) # number of classes
|
||||||
|
x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
|
||||||
|
|
||||||
|
# seaborn correlogram
|
||||||
|
sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
|
||||||
|
plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
# matplotlib labels
|
||||||
|
matplotlib.use('svg') # faster
|
||||||
|
ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
|
||||||
|
y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
|
||||||
|
try: # color histogram bars by class
|
||||||
|
[y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
|
||||||
|
except Exception:
|
||||||
|
pass
|
||||||
|
ax[0].set_ylabel('instances')
|
||||||
|
if 0 < len(names) < 30:
|
||||||
|
ax[0].set_xticks(range(len(names)))
|
||||||
|
ax[0].set_xticklabels(names, rotation=90, fontsize=10)
|
||||||
|
else:
|
||||||
|
ax[0].set_xlabel('classes')
|
||||||
|
sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
|
||||||
|
sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
|
||||||
|
|
||||||
|
# rectangles
|
||||||
|
labels[:, 1:3] = 0.5 # center
|
||||||
|
labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
|
||||||
|
img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
|
||||||
|
for cls, *box in labels[:1000]:
|
||||||
|
ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
|
||||||
|
ax[1].imshow(img)
|
||||||
|
ax[1].axis('off')
|
||||||
|
|
||||||
|
for a in [0, 1, 2, 3]:
|
||||||
|
for s in ['top', 'right', 'left', 'bottom']:
|
||||||
|
ax[a].spines[s].set_visible(False)
|
||||||
|
|
||||||
|
plt.savefig(save_dir / 'labels.jpg', dpi=200)
|
||||||
|
matplotlib.use('Agg')
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
|
||||||
|
def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
|
||||||
|
# Plot evolve.csv hyp evolution results
|
||||||
|
evolve_csv = Path(evolve_csv)
|
||||||
|
data = pd.read_csv(evolve_csv)
|
||||||
|
keys = [x.strip() for x in data.columns]
|
||||||
|
x = data.values
|
||||||
|
f = fitness(x)
|
||||||
|
j = np.argmax(f) # max fitness index
|
||||||
|
plt.figure(figsize=(10, 12), tight_layout=True)
|
||||||
|
matplotlib.rc('font', **{'size': 8})
|
||||||
|
print(f'Best results from row {j} of {evolve_csv}:')
|
||||||
|
for i, k in enumerate(keys[7:]):
|
||||||
|
v = x[:, 7 + i]
|
||||||
|
mu = v[j] # best single result
|
||||||
|
plt.subplot(6, 5, i + 1)
|
||||||
|
plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
|
||||||
|
plt.plot(mu, f.max(), 'k+', markersize=15)
|
||||||
|
plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
|
||||||
|
if i % 5 != 0:
|
||||||
|
plt.yticks([])
|
||||||
|
print(f'{k:>15}: {mu:.3g}')
|
||||||
|
f = evolve_csv.with_suffix('.png') # filename
|
||||||
|
plt.savefig(f, dpi=200)
|
||||||
|
plt.close()
|
||||||
|
print(f'Saved {f}')
|
||||||
|
|
||||||
|
|
||||||
|
def plot_results(file='path/to/results.csv', dir=''):
|
||||||
|
# Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
|
||||||
|
save_dir = Path(file).parent if file else Path(dir)
|
||||||
|
fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
|
||||||
|
ax = ax.ravel()
|
||||||
|
files = list(save_dir.glob('results*.csv'))
|
||||||
|
assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
|
||||||
|
for fi, f in enumerate(files):
|
||||||
|
try:
|
||||||
|
data = pd.read_csv(f)
|
||||||
|
s = [x.strip() for x in data.columns]
|
||||||
|
x = data.values[:, 0]
|
||||||
|
for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
|
||||||
|
y = data.values[:, j]
|
||||||
|
# y[y == 0] = np.nan # don't show zero values
|
||||||
|
ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
|
||||||
|
ax[i].set_title(s[j], fontsize=12)
|
||||||
|
# if j in [8, 9, 10]: # share train and val loss y axes
|
||||||
|
# ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
|
||||||
|
except Exception as e:
|
||||||
|
LOGGER.info(f'Warning: Plotting error for {f}: {e}')
|
||||||
|
ax[1].legend()
|
||||||
|
fig.savefig(save_dir / 'results.png', dpi=200)
|
||||||
|
plt.close()
|
||||||
|
|
||||||
|
|
||||||
|
def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
|
||||||
|
# Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
|
||||||
|
ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
|
||||||
|
s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
|
||||||
|
files = list(Path(save_dir).glob('frames*.txt'))
|
||||||
|
for fi, f in enumerate(files):
|
||||||
|
try:
|
||||||
|
results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
|
||||||
|
n = results.shape[1] # number of rows
|
||||||
|
x = np.arange(start, min(stop, n) if stop else n)
|
||||||
|
results = results[:, x]
|
||||||
|
t = (results[0] - results[0].min()) # set t0=0s
|
||||||
|
results[0] = x
|
||||||
|
for i, a in enumerate(ax):
|
||||||
|
if i < len(results):
|
||||||
|
label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
|
||||||
|
a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
|
||||||
|
a.set_title(s[i])
|
||||||
|
a.set_xlabel('time (s)')
|
||||||
|
# if fi == len(files) - 1:
|
||||||
|
# a.set_ylim(bottom=0)
|
||||||
|
for side in ['top', 'right']:
|
||||||
|
a.spines[side].set_visible(False)
|
||||||
|
else:
|
||||||
|
a.remove()
|
||||||
|
except Exception as e:
|
||||||
|
print(f'Warning: Plotting error for {f}; {e}')
|
||||||
|
ax[1].legend()
|
||||||
|
plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
|
||||||
|
|
||||||
|
|
||||||
|
def save_one_box(xyxy, im, file='image.jpg', gain=1.02, pad=10, square=False, BGR=False, save=True):
|
||||||
|
# Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
|
||||||
|
xyxy = torch.tensor(xyxy).view(-1, 4)
|
||||||
|
b = xyxy2xywh(xyxy) # boxes
|
||||||
|
if square:
|
||||||
|
b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
|
||||||
|
b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
|
||||||
|
xyxy = xywh2xyxy(b).long()
|
||||||
|
clip_coords(xyxy, im.shape)
|
||||||
|
crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
|
||||||
|
if save:
|
||||||
|
file.parent.mkdir(parents=True, exist_ok=True) # make directory
|
||||||
|
cv2.imwrite(str(increment_path(file).with_suffix('.jpg')), crop)
|
||||||
|
return crop
|
||||||
329
utils/torch_utils.py
Normal file
329
utils/torch_utils.py
Normal file
@ -0,0 +1,329 @@
|
|||||||
|
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
|
||||||
|
"""
|
||||||
|
PyTorch utils
|
||||||
|
"""
|
||||||
|
|
||||||
|
import datetime
|
||||||
|
import math
|
||||||
|
import os
|
||||||
|
import platform
|
||||||
|
import subprocess
|
||||||
|
import time
|
||||||
|
import warnings
|
||||||
|
from contextlib import contextmanager
|
||||||
|
from copy import deepcopy
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.distributed as dist
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from utils.general import LOGGER
|
||||||
|
|
||||||
|
try:
|
||||||
|
import thop # for FLOPs computation
|
||||||
|
except ImportError:
|
||||||
|
thop = None
|
||||||
|
|
||||||
|
# Suppress PyTorch warnings
|
||||||
|
warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
|
||||||
|
|
||||||
|
|
||||||
|
@contextmanager
|
||||||
|
def torch_distributed_zero_first(local_rank: int):
|
||||||
|
"""
|
||||||
|
Decorator to make all processes in distributed training wait for each local_master to do something.
|
||||||
|
"""
|
||||||
|
if local_rank not in [-1, 0]:
|
||||||
|
dist.barrier(device_ids=[local_rank])
|
||||||
|
yield
|
||||||
|
if local_rank == 0:
|
||||||
|
dist.barrier(device_ids=[0])
|
||||||
|
|
||||||
|
|
||||||
|
def date_modified(path=__file__):
|
||||||
|
# return human-readable file modification date, i.e. '2021-3-26'
|
||||||
|
t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
|
||||||
|
return f'{t.year}-{t.month}-{t.day}'
|
||||||
|
|
||||||
|
|
||||||
|
def git_describe(path=Path(__file__).parent): # path must be a directory
|
||||||
|
# return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
|
||||||
|
s = f'git -C {path} describe --tags --long --always'
|
||||||
|
try:
|
||||||
|
return subprocess.check_output(s, shell=True, stderr=subprocess.STDOUT).decode()[:-1]
|
||||||
|
except subprocess.CalledProcessError:
|
||||||
|
return '' # not a git repository
|
||||||
|
|
||||||
|
|
||||||
|
def device_count():
|
||||||
|
# Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Only works on Linux.
|
||||||
|
assert platform.system() == 'Linux', 'device_count() function only works on Linux'
|
||||||
|
try:
|
||||||
|
cmd = 'nvidia-smi -L | wc -l'
|
||||||
|
return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
|
||||||
|
except Exception:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
|
||||||
|
def select_device(device='', batch_size=0, newline=True):
|
||||||
|
# device = 'cpu' or '0' or '0,1,2,3'
|
||||||
|
s = f'YOLOv5 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string
|
||||||
|
device = str(device).strip().lower().replace('cuda:', '') # to string, 'cuda:0' to '0'
|
||||||
|
cpu = device == 'cpu'
|
||||||
|
if cpu:
|
||||||
|
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
|
||||||
|
elif device: # non-cpu device requested
|
||||||
|
os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
|
||||||
|
assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
|
||||||
|
f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
|
||||||
|
|
||||||
|
cuda = not cpu and torch.cuda.is_available()
|
||||||
|
if cuda:
|
||||||
|
devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
|
||||||
|
n = len(devices) # device count
|
||||||
|
if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
|
||||||
|
assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
|
||||||
|
space = ' ' * (len(s) + 1)
|
||||||
|
for i, d in enumerate(devices):
|
||||||
|
p = torch.cuda.get_device_properties(i)
|
||||||
|
s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2:.0f}MiB)\n" # bytes to MB
|
||||||
|
else:
|
||||||
|
s += 'CPU\n'
|
||||||
|
|
||||||
|
if not newline:
|
||||||
|
s = s.rstrip()
|
||||||
|
LOGGER.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
|
||||||
|
return torch.device('cuda:0' if cuda else 'cpu')
|
||||||
|
|
||||||
|
|
||||||
|
def time_sync():
|
||||||
|
# pytorch-accurate time
|
||||||
|
if torch.cuda.is_available():
|
||||||
|
torch.cuda.synchronize()
|
||||||
|
return time.time()
|
||||||
|
|
||||||
|
|
||||||
|
def profile(input, ops, n=10, device=None):
|
||||||
|
# YOLOv5 speed/memory/FLOPs profiler
|
||||||
|
#
|
||||||
|
# Usage:
|
||||||
|
# input = torch.randn(16, 3, 640, 640)
|
||||||
|
# m1 = lambda x: x * torch.sigmoid(x)
|
||||||
|
# m2 = nn.SiLU()
|
||||||
|
# profile(input, [m1, m2], n=100) # profile over 100 iterations
|
||||||
|
|
||||||
|
results = []
|
||||||
|
device = device or select_device()
|
||||||
|
print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
|
||||||
|
f"{'input':>24s}{'output':>24s}")
|
||||||
|
|
||||||
|
for x in input if isinstance(input, list) else [input]:
|
||||||
|
x = x.to(device)
|
||||||
|
x.requires_grad = True
|
||||||
|
for m in ops if isinstance(ops, list) else [ops]:
|
||||||
|
m = m.to(device) if hasattr(m, 'to') else m # device
|
||||||
|
m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
|
||||||
|
tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
|
||||||
|
try:
|
||||||
|
flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
|
||||||
|
except Exception:
|
||||||
|
flops = 0
|
||||||
|
|
||||||
|
try:
|
||||||
|
for _ in range(n):
|
||||||
|
t[0] = time_sync()
|
||||||
|
y = m(x)
|
||||||
|
t[1] = time_sync()
|
||||||
|
try:
|
||||||
|
_ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
|
||||||
|
t[2] = time_sync()
|
||||||
|
except Exception: # no backward method
|
||||||
|
# print(e) # for debug
|
||||||
|
t[2] = float('nan')
|
||||||
|
tf += (t[1] - t[0]) * 1000 / n # ms per op forward
|
||||||
|
tb += (t[2] - t[1]) * 1000 / n # ms per op backward
|
||||||
|
mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
|
||||||
|
s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
|
||||||
|
s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
|
||||||
|
p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0 # parameters
|
||||||
|
print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
|
||||||
|
results.append([p, flops, mem, tf, tb, s_in, s_out])
|
||||||
|
except Exception as e:
|
||||||
|
print(e)
|
||||||
|
results.append(None)
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
return results
|
||||||
|
|
||||||
|
|
||||||
|
def is_parallel(model):
|
||||||
|
# Returns True if model is of type DP or DDP
|
||||||
|
return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
|
||||||
|
|
||||||
|
|
||||||
|
def de_parallel(model):
|
||||||
|
# De-parallelize a model: returns single-GPU model if model is of type DP or DDP
|
||||||
|
return model.module if is_parallel(model) else model
|
||||||
|
|
||||||
|
|
||||||
|
def initialize_weights(model):
|
||||||
|
for m in model.modules():
|
||||||
|
t = type(m)
|
||||||
|
if t is nn.Conv2d:
|
||||||
|
pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
||||||
|
elif t is nn.BatchNorm2d:
|
||||||
|
m.eps = 1e-3
|
||||||
|
m.momentum = 0.03
|
||||||
|
elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
|
||||||
|
m.inplace = True
|
||||||
|
|
||||||
|
|
||||||
|
def find_modules(model, mclass=nn.Conv2d):
|
||||||
|
# Finds layer indices matching module class 'mclass'
|
||||||
|
return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
|
||||||
|
|
||||||
|
|
||||||
|
def sparsity(model):
|
||||||
|
# Return global model sparsity
|
||||||
|
a, b = 0, 0
|
||||||
|
for p in model.parameters():
|
||||||
|
a += p.numel()
|
||||||
|
b += (p == 0).sum()
|
||||||
|
return b / a
|
||||||
|
|
||||||
|
|
||||||
|
def prune(model, amount=0.3):
|
||||||
|
# Prune model to requested global sparsity
|
||||||
|
import torch.nn.utils.prune as prune
|
||||||
|
print('Pruning model... ', end='')
|
||||||
|
for name, m in model.named_modules():
|
||||||
|
if isinstance(m, nn.Conv2d):
|
||||||
|
prune.l1_unstructured(m, name='weight', amount=amount) # prune
|
||||||
|
prune.remove(m, 'weight') # make permanent
|
||||||
|
print(' %.3g global sparsity' % sparsity(model))
|
||||||
|
|
||||||
|
|
||||||
|
def fuse_conv_and_bn(conv, bn):
|
||||||
|
# Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
|
||||||
|
fusedconv = nn.Conv2d(conv.in_channels,
|
||||||
|
conv.out_channels,
|
||||||
|
kernel_size=conv.kernel_size,
|
||||||
|
stride=conv.stride,
|
||||||
|
padding=conv.padding,
|
||||||
|
groups=conv.groups,
|
||||||
|
bias=True).requires_grad_(False).to(conv.weight.device)
|
||||||
|
|
||||||
|
# prepare filters
|
||||||
|
w_conv = conv.weight.clone().view(conv.out_channels, -1)
|
||||||
|
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
|
||||||
|
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
|
||||||
|
|
||||||
|
# prepare spatial bias
|
||||||
|
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
|
||||||
|
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
|
||||||
|
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
|
||||||
|
|
||||||
|
return fusedconv
|
||||||
|
|
||||||
|
|
||||||
|
def model_info(model, verbose=False, img_size=640):
|
||||||
|
# Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
|
||||||
|
n_p = sum(x.numel() for x in model.parameters()) # number parameters
|
||||||
|
n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
|
||||||
|
if verbose:
|
||||||
|
print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
|
||||||
|
for i, (name, p) in enumerate(model.named_parameters()):
|
||||||
|
name = name.replace('module_list.', '')
|
||||||
|
print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
|
||||||
|
(i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
|
||||||
|
|
||||||
|
try: # FLOPs
|
||||||
|
from thop import profile
|
||||||
|
stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32
|
||||||
|
img = torch.zeros((1, model.yaml.get('ch', 3), stride, stride), device=next(model.parameters()).device) # input
|
||||||
|
flops = profile(deepcopy(model), inputs=(img,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
|
||||||
|
img_size = img_size if isinstance(img_size, list) else [img_size, img_size] # expand if int/float
|
||||||
|
fs = ', %.1f GFLOPs' % (flops * img_size[0] / stride * img_size[1] / stride) # 640x640 GFLOPs
|
||||||
|
except (ImportError, Exception):
|
||||||
|
fs = ''
|
||||||
|
|
||||||
|
LOGGER.info(f"Model Summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
|
||||||
|
|
||||||
|
|
||||||
|
def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
|
||||||
|
# scales img(bs,3,y,x) by ratio constrained to gs-multiple
|
||||||
|
if ratio == 1.0:
|
||||||
|
return img
|
||||||
|
else:
|
||||||
|
h, w = img.shape[2:]
|
||||||
|
s = (int(h * ratio), int(w * ratio)) # new size
|
||||||
|
img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
|
||||||
|
if not same_shape: # pad/crop img
|
||||||
|
h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
|
||||||
|
return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
|
||||||
|
|
||||||
|
|
||||||
|
def copy_attr(a, b, include=(), exclude=()):
|
||||||
|
# Copy attributes from b to a, options to only include [...] and to exclude [...]
|
||||||
|
for k, v in b.__dict__.items():
|
||||||
|
if (len(include) and k not in include) or k.startswith('_') or k in exclude:
|
||||||
|
continue
|
||||||
|
else:
|
||||||
|
setattr(a, k, v)
|
||||||
|
|
||||||
|
|
||||||
|
class EarlyStopping:
|
||||||
|
# YOLOv5 simple early stopper
|
||||||
|
def __init__(self, patience=30):
|
||||||
|
self.best_fitness = 0.0 # i.e. mAP
|
||||||
|
self.best_epoch = 0
|
||||||
|
self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
|
||||||
|
self.possible_stop = False # possible stop may occur next epoch
|
||||||
|
|
||||||
|
def __call__(self, epoch, fitness):
|
||||||
|
if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
|
||||||
|
self.best_epoch = epoch
|
||||||
|
self.best_fitness = fitness
|
||||||
|
delta = epoch - self.best_epoch # epochs without improvement
|
||||||
|
self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
|
||||||
|
stop = delta >= self.patience # stop training if patience exceeded
|
||||||
|
if stop:
|
||||||
|
LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
|
||||||
|
f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
|
||||||
|
f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
|
||||||
|
f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
|
||||||
|
return stop
|
||||||
|
|
||||||
|
|
||||||
|
class ModelEMA:
|
||||||
|
""" Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
|
||||||
|
Keeps a moving average of everything in the model state_dict (parameters and buffers)
|
||||||
|
For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, model, decay=0.9999, updates=0):
|
||||||
|
# Create EMA
|
||||||
|
self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
|
||||||
|
# if next(model.parameters()).device.type != 'cpu':
|
||||||
|
# self.ema.half() # FP16 EMA
|
||||||
|
self.updates = updates # number of EMA updates
|
||||||
|
self.decay = lambda x: decay * (1 - math.exp(-x / 2000)) # decay exponential ramp (to help early epochs)
|
||||||
|
for p in self.ema.parameters():
|
||||||
|
p.requires_grad_(False)
|
||||||
|
|
||||||
|
def update(self, model):
|
||||||
|
# Update EMA parameters
|
||||||
|
with torch.no_grad():
|
||||||
|
self.updates += 1
|
||||||
|
d = self.decay(self.updates)
|
||||||
|
|
||||||
|
msd = de_parallel(model).state_dict() # model state_dict
|
||||||
|
for k, v in self.ema.state_dict().items():
|
||||||
|
if v.dtype.is_floating_point:
|
||||||
|
v *= d
|
||||||
|
v += (1 - d) * msd[k].detach()
|
||||||
|
|
||||||
|
def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
|
||||||
|
# Update EMA attributes
|
||||||
|
copy_attr(self.ema, model, include, exclude)
|
||||||
208
valve_test.py
Executable file
208
valve_test.py
Executable file
@ -0,0 +1,208 @@
|
|||||||
|
import socket
|
||||||
|
|
||||||
|
import cv2
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
|
||||||
|
class ValveTest:
|
||||||
|
def __init__(self, host=None, port=13452):
|
||||||
|
self.increase_modes = ['测下一个', '重复测试']
|
||||||
|
self.last_cmd = None
|
||||||
|
self.increase_mode = 0
|
||||||
|
self.reminder = None
|
||||||
|
self.update_reminder()
|
||||||
|
self.s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建 socket 对象
|
||||||
|
self.s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||||
|
host = socket.gethostname() if host is None else host # 获取本地主机名
|
||||||
|
print(f"Service Address {host}, {port}.")
|
||||||
|
self.s.bind((host, port)) # 绑定端口
|
||||||
|
self.s.listen(5) # 等待客户端连接
|
||||||
|
self.c = None
|
||||||
|
|
||||||
|
def update_reminder(self):
|
||||||
|
self.reminder = f"""======================================================================================
|
||||||
|
快,给我个指令😉😉😉︎:
|
||||||
|
a. 开始命令 st. e. 设置 光谱(a)相机 的延时,格式 e,500
|
||||||
|
b. 停止命令 sp. f. 设置 彩色(b)相机 的延时, 格式 f,500
|
||||||
|
c. 设置光谱相机分频系数,4的倍数且>=8, 格式 c,8 g. 发个da和db完全重叠的mask
|
||||||
|
d. 阀板的脉冲分频系数,>=2即可 h. 发个da和db呈现出X形的mask
|
||||||
|
m. 模式切换:测下一个喷阀还是重发?
|
||||||
|
你给我个小于256的数字,我就测试对应的喷阀。如果已经测试过一个,可以直接回车{self.increase_modes[self.increase_mode]}。
|
||||||
|
给q指令我就退出。
|
||||||
|
======================================================================================\n"""
|
||||||
|
|
||||||
|
def run(self):
|
||||||
|
print("我在等连接...")
|
||||||
|
self.c, addr = self.s.accept() # 建立客户端连接
|
||||||
|
print('和它的链接建立成功了:', addr)
|
||||||
|
self.c.settimeout(0.1)
|
||||||
|
while True:
|
||||||
|
data = ''
|
||||||
|
try:
|
||||||
|
data = self.c.recv(1024)
|
||||||
|
except Exception as e:
|
||||||
|
print(f"===================================================================")
|
||||||
|
if len(data) > 0:
|
||||||
|
print("receive data!!!")
|
||||||
|
print(data)
|
||||||
|
value = input(self.reminder)
|
||||||
|
if value == 'q':
|
||||||
|
print("好的,我退出啦")
|
||||||
|
self.s.close()
|
||||||
|
break
|
||||||
|
else:
|
||||||
|
self.process_cmd(value)
|
||||||
|
self.c.close() # 关闭连接
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def cmd_padding(cmd):
|
||||||
|
return b'\xAA' + cmd + b'\xFF\xFF\xBB'
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def param_cmd_parser(cmd, default_value, checker=None):
|
||||||
|
try:
|
||||||
|
value = int(cmd.split(',')[-1])
|
||||||
|
except:
|
||||||
|
print(f'你给的值不对啊,我先给你弄个{default_value}吧')
|
||||||
|
value = default_value
|
||||||
|
if checker is not None:
|
||||||
|
if not checker(value):
|
||||||
|
return None
|
||||||
|
return value
|
||||||
|
|
||||||
|
def process_cmd(self, value):
|
||||||
|
if value == 'a':
|
||||||
|
# a.开始命令
|
||||||
|
cmd = b'\x00\x03' + 'st'.encode('ascii') + b'\xFF'
|
||||||
|
elif value == 'b':
|
||||||
|
# b.停止命令
|
||||||
|
cmd = b'\x00\x03' + 'sp'.encode('ascii') + b'\xFF'
|
||||||
|
elif value.startswith('c'):
|
||||||
|
# c. 设置光谱相机分频,得是4的倍数而且>=8,格式:c,8
|
||||||
|
checker = lambda x: (x % 4 == 0) and (x >= 8)
|
||||||
|
value = self.param_cmd_parser(value, default_value=8, checker=checker)
|
||||||
|
if value is None:
|
||||||
|
print("值需要是4的倍数且大于8")
|
||||||
|
return
|
||||||
|
cmd = b'\x00\x0a' + 'sc'.encode('ascii') + f"{value:08d}".encode('ascii')
|
||||||
|
elif value.startswith('d'):
|
||||||
|
# d. 阀板的脉冲分频系数,>=2即可
|
||||||
|
checker = lambda x: x >= 2
|
||||||
|
value = self.param_cmd_parser(value, default_value=2, checker=checker)
|
||||||
|
if value is None:
|
||||||
|
print("你得大于等于2")
|
||||||
|
return
|
||||||
|
cmd = b'\x00\x0a' + 'sv'.encode('ascii') + f"{value:08d}".encode('ascii')
|
||||||
|
elif value.startswith('e'):
|
||||||
|
# e. 设置 光谱(a)相机 的延时,格式 e,500
|
||||||
|
checker = lambda x: (x >= 0)
|
||||||
|
value = self.param_cmd_parser(value, default_value=2, checker=checker)
|
||||||
|
if value is None:
|
||||||
|
print("你得大于等于0")
|
||||||
|
return
|
||||||
|
cmd = b'\x00\x0a' + 'sa'.encode('ascii') + f"{value:08d}".encode('ascii')
|
||||||
|
elif value.startswith('f'):
|
||||||
|
# f. 设置 RGB(b)相机 的延时,格式 e,500
|
||||||
|
checker = lambda x: (x >= 0)
|
||||||
|
value = self.param_cmd_parser(value, default_value=2, checker=checker)
|
||||||
|
if value is None:
|
||||||
|
print("你得大于等于0")
|
||||||
|
return
|
||||||
|
cmd = b'\x00\x0a' + 'sb'.encode('ascii') + f"{value:08d}".encode('ascii')
|
||||||
|
elif value == 'g':
|
||||||
|
# g.发个da和db完全重叠的mask
|
||||||
|
mask_a, mask_b = np.eye(256, dtype=np.uint8), np.eye(256, dtype=np.uint8)
|
||||||
|
mask_a, mask_b = [cv2.resize(mask, mask_size) for mask in [mask_a, mask_b]]
|
||||||
|
len_a, data_a = self.format_data(mask_a)
|
||||||
|
len_b, data_b = self.format_data(mask_b)
|
||||||
|
cmd = len_a + 'da'.encode('ascii') + data_a
|
||||||
|
self.send(cmd)
|
||||||
|
cmd = len_b + 'db'.encode('ascii') + data_b
|
||||||
|
elif value == 'h':
|
||||||
|
# h.发个da和db呈现出X形的mask
|
||||||
|
mask_a, mask_b = np.eye(256, dtype=np.uint8), np.eye(256, dtype=np.uint8).T
|
||||||
|
mask_a, mask_b = [cv2.resize(mask, mask_size) for mask in [mask_a, mask_b]]
|
||||||
|
len_a, data_a = self.format_data(mask_a)
|
||||||
|
len_b, data_b = self.format_data(mask_b)
|
||||||
|
cmd = len_a + 'da'.encode('ascii') + data_a
|
||||||
|
self.send(cmd)
|
||||||
|
cmd = len_b + 'db'.encode('ascii') + data_b
|
||||||
|
elif value == 'm':
|
||||||
|
self.increase_mode = int(1 - self.increase_mode)
|
||||||
|
self.update_reminder()
|
||||||
|
print("模式切换")
|
||||||
|
return
|
||||||
|
elif value == '' and self.last_cmd is not None:
|
||||||
|
if self.increase_mode == 0:
|
||||||
|
self.last_cmd += 1
|
||||||
|
if self.last_cmd > 256:
|
||||||
|
self.last_cmd = 1
|
||||||
|
print(f'自动变化到 喷阀测试 {self.last_cmd}')
|
||||||
|
value = self.last_cmd
|
||||||
|
cmd = b'\x00\x0A' + 'te'.encode('ascii') + f"{value - 1:08d}".encode('ascii')
|
||||||
|
else:
|
||||||
|
try:
|
||||||
|
value = int(value)
|
||||||
|
except Exception as e:
|
||||||
|
print(e)
|
||||||
|
print(f"你给的指令: {value} 咋看都不对")
|
||||||
|
return
|
||||||
|
if (value <= 256) and (value >= 1):
|
||||||
|
cmd = b'\x00\x0A' + 'te'.encode('ascii') + f"{value - 1:08d}".encode('ascii')
|
||||||
|
self.last_cmd = value
|
||||||
|
elif value == 257:
|
||||||
|
cmd = b'\x00\x0A' + 'te'.encode('ascii') + f"{value:08d}".encode('ascii')
|
||||||
|
print("恭喜你发现了这个隐藏的257号流水灯指令😝😝😝,好厉害。")
|
||||||
|
else:
|
||||||
|
print(f'你给的指令: {value} 值不对,我们有256个阀门, 范围是 [1, 256],略大一个好像也可以')
|
||||||
|
return
|
||||||
|
self.send(cmd)
|
||||||
|
|
||||||
|
def send(self, cmd: bytes) -> None:
|
||||||
|
cmd = self.cmd_padding(cmd)
|
||||||
|
print("我要 send 这个了:")
|
||||||
|
print(cmd.hex())
|
||||||
|
try:
|
||||||
|
self.c.send(cmd)
|
||||||
|
except Exception as e:
|
||||||
|
print(f"发失败了, 这是我找到的错误信息:\n{e}")
|
||||||
|
return
|
||||||
|
print("发好了")
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def format_data(array_to_send: np.ndarray) -> (bytes, bytes):
|
||||||
|
data = np.packbits(array_to_send, axis=-1)
|
||||||
|
data = data.tobytes()
|
||||||
|
data_len = (len(data) + 2).to_bytes(2, 'big')
|
||||||
|
return data_len, data
|
||||||
|
|
||||||
|
|
||||||
|
class VirtualValve:
|
||||||
|
def __init__(self, host, port):
|
||||||
|
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 声明socket类型,同时生成链接对象
|
||||||
|
self.client.connect((host, port)) # 建立一个链接,连接到本地的13452端口
|
||||||
|
|
||||||
|
def run(self):
|
||||||
|
while True:
|
||||||
|
# addr = client.accept()
|
||||||
|
# print '连接地址:', addr
|
||||||
|
data = self.client.recv(4096) # 接收一个信息,并指定接收的大小 为1024字节
|
||||||
|
print(data.hex()) # 输出我接收的信息
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
import argparse
|
||||||
|
parser = argparse.ArgumentParser(description='阀门测程序')
|
||||||
|
parser.add_argument('-c', default=False, action='store_true', help='是否是开个客户端', required=False)
|
||||||
|
parser.add_argument('-m', default='192.168.10.8', help='指定master主机名')
|
||||||
|
parser.add_argument('-p', default=13452, help='指定端口')
|
||||||
|
args = parser.parse_args()
|
||||||
|
mask_size = (1024, 256) # size of cv (Width, Height)
|
||||||
|
if args.c:
|
||||||
|
print("运行客户机")
|
||||||
|
virtual_valve = VirtualValve(host=args.m, port=args.p)
|
||||||
|
virtual_valve.run()
|
||||||
|
else:
|
||||||
|
print("运行主机")
|
||||||
|
valve_tester = ValveTest(host=args.m, port=args.p)
|
||||||
|
valve_tester.run()
|
||||||
Loading…
Reference in New Issue
Block a user