mirror of
https://github.com/NanjingForestryUniversity/supermachine-tobacco.git
synced 2025-11-08 14:23:55 +00:00
添加文档和整理
This commit is contained in:
parent
be54646190
commit
62440b5bb9
@ -13,7 +13,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 25,
|
"execution_count": 1,
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"pycharm": {
|
"pycharm": {
|
||||||
"name": "#%%\n"
|
"name": "#%%\n"
|
||||||
@ -40,7 +40,7 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 26,
|
"execution_count": 2,
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"pycharm": {
|
"pycharm": {
|
||||||
"name": "#%%\n"
|
"name": "#%%\n"
|
||||||
@ -49,19 +49,7 @@
|
|||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"img_path = r\"data/dataset_old/img/yangeng.bmp\"\n",
|
"img_path = r\"data/dataset_old/img/yangeng.bmp\"\n",
|
||||||
"label_path = r\"data/dataset_old/label/yangeng.bmp\""
|
"label_path = r\"data/dataset_old/label/yangeng.bmp\"\n",
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": 27,
|
|
||||||
"metadata": {
|
|
||||||
"pycharm": {
|
|
||||||
"name": "#%%\n"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# 读取图片和色彩空间转换\n",
|
"# 读取图片和色彩空间转换\n",
|
||||||
"img = cv2.imread(img_path)\n",
|
"img = cv2.imread(img_path)\n",
|
||||||
"label_img = cv2.imread(label_path)\n",
|
"label_img = cv2.imread(label_path)\n",
|
||||||
|
|||||||
@ -7,13 +7,11 @@
|
|||||||
"name": "#%% md\n"
|
"name": "#%% md\n"
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"source": [
|
"source": []
|
||||||
"# 模型的训练"
|
|
||||||
]
|
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 1,
|
"execution_count": 5,
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"pycharm": {
|
"pycharm": {
|
||||||
"name": "#%%\n"
|
"name": "#%%\n"
|
||||||
@ -28,110 +26,139 @@
|
|||||||
"from utils import read_labeled_img"
|
"from utils import read_labeled_img"
|
||||||
]
|
]
|
||||||
},
|
},
|
||||||
{
|
|
||||||
"cell_type": "markdown",
|
|
||||||
"metadata": {
|
|
||||||
"pycharm": {
|
|
||||||
"name": "#%% md\n"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"source": [
|
|
||||||
"## 读取数据与构建数据集"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 7,
|
"execution_count": null,
|
||||||
"metadata": {
|
|
||||||
"pycharm": {
|
|
||||||
"name": "#%%\n"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"outputs": [],
|
"outputs": [],
|
||||||
"source": [
|
"source": [
|
||||||
"data_dir = \"data/dataset\"\n",
|
"train_from_existed = True # 是否从现有数据训练,如果是的话,那就从dataset_file训练,否则就用data_dir里头的数据\n",
|
||||||
"color_dict = {(0, 0, 255): \"yangeng\", (255, 0, 0): 'beijing'}\n",
|
"data_dir = \"data/dataset\" # 数据集,文件夹下必须包含`img`和`label`两个文件夹,放置相同文件名的图片和label\n",
|
||||||
"label_index = {\"yangeng\": 1, \"beijing\": 0}\n",
|
"dataset_file = \"data/dataset/dataset_2022-07-20_10-04.mat\"\n",
|
||||||
"dataset = read_labeled_img(data_dir, color_dict=color_dict, is_ps_color_space=False)\n",
|
|
||||||
"rus = RandomUnderSampler(random_state=0)\n",
|
|
||||||
"x_list, y_list = np.concatenate([v for k, v in dataset.items()], axis=0).tolist(), \\\n",
|
|
||||||
" np.concatenate([np.ones((v.shape[0],)) * label_index[k] for k, v in dataset.items()], axis=0).tolist()\n",
|
|
||||||
"\n",
|
"\n",
|
||||||
"x_resampled, y_resampled = rus.fit_resample(x_list, y_list)\n",
|
"color_dict = {(0, 0, 255): \"yangeng\", (255, 0, 0): 'beijing'} # 颜色对应的类别\n",
|
||||||
"dataset = {\"inside\": np.array(x_resampled)}"
|
"label_index = {\"yangeng\": 1, \"beijing\": 0} # 类别对应的序号\n",
|
||||||
]
|
"show_samples = False # 是否展示样本\n",
|
||||||
|
"\n",
|
||||||
|
"# 定义一些训练量\n",
|
||||||
|
"threshold = 5 # 正样本周围多大范围内的还算是正样本\n",
|
||||||
|
"node_num = 20 # 如果使用ELM作为分类器物,有多少的节点\n",
|
||||||
|
"negative_sample_num = None # None或者一个数字,对应生成的负样本数量"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "markdown",
|
"cell_type": "markdown",
|
||||||
"metadata": {
|
|
||||||
"pycharm": {
|
|
||||||
"name": "#%% md\n"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"source": [
|
"source": [
|
||||||
"## 模型训练"
|
"## 读取数据"
|
||||||
]
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false
|
||||||
|
}
|
||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": 8,
|
"execution_count": 10,
|
||||||
"metadata": {
|
|
||||||
"pycharm": {
|
|
||||||
"name": "#%%\n"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"# 定义一些常量\n",
|
|
||||||
"threshold = 5\n",
|
|
||||||
"node_num = 20\n",
|
|
||||||
"negative_sample_num = None # None或者一个数字\n",
|
|
||||||
"world_boundary = np.array([0, 0, 0, 255, 255, 255])\n",
|
|
||||||
"# 对数据进行预处理\n",
|
|
||||||
"x = np.concatenate([v for k, v in dataset.items()], axis=0)\n",
|
|
||||||
"negative_sample_num = int(x.shape[0] * 1.2) if negative_sample_num is None else negative_sample_num\n"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": 2,
|
|
||||||
"metadata": {
|
|
||||||
"pycharm": {
|
|
||||||
"name": "#%%\n"
|
|
||||||
}
|
|
||||||
},
|
|
||||||
"outputs": [],
|
|
||||||
"source": [
|
|
||||||
"model = AnonymousColorDetector()"
|
|
||||||
]
|
|
||||||
},
|
|
||||||
{
|
|
||||||
"cell_type": "code",
|
|
||||||
"execution_count": 3,
|
|
||||||
"outputs": [
|
"outputs": [
|
||||||
{
|
{
|
||||||
"name": "stdout",
|
"ename": "FileNotFoundError",
|
||||||
"output_type": "stream",
|
"evalue": "[Errno 2] No such file or directory: 'data/dataset/label'",
|
||||||
"text": [
|
"output_type": "error",
|
||||||
" precision recall f1-score support\n",
|
"traceback": [
|
||||||
"\n",
|
"\u001B[0;31m---------------------------------------------------------------------------\u001B[0m",
|
||||||
" 0.0 0.99 0.99 0.99 26314\n",
|
"\u001B[0;31mFileNotFoundError\u001B[0m Traceback (most recent call last)",
|
||||||
" 1.0 0.99 0.99 0.99 24492\n",
|
"\u001B[0;32m/var/folders/wh/kr5c3dr12834pfk3j7yqnrq40000gn/T/ipykernel_30867/1942905945.py\u001B[0m in \u001B[0;36m<module>\u001B[0;34m\u001B[0m\n\u001B[0;32m----> 1\u001B[0;31m \u001B[0mdataset\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mread_labeled_img\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mdata_dir\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mcolor_dict\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0mcolor_dict\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mis_ps_color_space\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;32mFalse\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[0m\u001B[1;32m 2\u001B[0m \u001B[0;32mif\u001B[0m \u001B[0mshow_samples\u001B[0m\u001B[0;34m:\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 3\u001B[0m \u001B[0;32mfrom\u001B[0m \u001B[0mutils\u001B[0m \u001B[0;32mimport\u001B[0m \u001B[0mlab_scatter\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 4\u001B[0m \u001B[0mlab_scatter\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mdataset\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mclass_max_num\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;36m30000\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mis_3d\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;32mTrue\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mis_ps_color_space\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;32mFalse\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n",
|
||||||
"\n",
|
"\u001B[0;32m~/PycharmProjects/tobacco_color/utils.py\u001B[0m in \u001B[0;36mread_labeled_img\u001B[0;34m(dataset_dir, color_dict, ext, is_ps_color_space)\u001B[0m\n\u001B[1;32m 37\u001B[0m \u001B[0;34m:\u001B[0m\u001B[0;32mreturn\u001B[0m\u001B[0;34m:\u001B[0m \u001B[0m字典形式的数据集\u001B[0m\u001B[0;34m{\u001B[0m\u001B[0mlabel\u001B[0m\u001B[0;34m:\u001B[0m \u001B[0mvector\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mn\u001B[0m \u001B[0mx\u001B[0m \u001B[0;36m3\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m}\u001B[0m\u001B[0;34m,\u001B[0m\u001B[0mvector为lab色彩空间\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 38\u001B[0m \"\"\"\n\u001B[0;32m---> 39\u001B[0;31m img_names = [img_name for img_name in os.listdir(os.path.join(dataset_dir, 'label'))\n\u001B[0m\u001B[1;32m 40\u001B[0m if img_name.endswith(ext)]\n\u001B[1;32m 41\u001B[0m \u001B[0mtotal_dataset\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mMergeDict\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n",
|
||||||
" accuracy 0.99 50806\n",
|
"\u001B[0;31mFileNotFoundError\u001B[0m: [Errno 2] No such file or directory: 'data/dataset/label'"
|
||||||
" macro avg 0.99 0.99 0.99 50806\n",
|
|
||||||
"weighted avg 0.99 0.99 0.99 50806\n",
|
|
||||||
"\n"
|
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
],
|
],
|
||||||
"source": [
|
"source": [
|
||||||
"# model.fit(x, world_boundary, threshold, negative_sample_size=negative_sample_num, train_size=0.7,\n",
|
"dataset = read_labeled_img(data_dir, color_dict=color_dict, is_ps_color_space=False)\n",
|
||||||
"# is_save_dataset=True, model_selection='dt')\n",
|
"if show_samples:\n",
|
||||||
"data = scipy.io.loadmat('data/dataset/dataset_2022-07-20_10-04.mat')\n",
|
" from utils import lab_scatter\n",
|
||||||
"x, y = data['x'], data['y'].ravel()\n",
|
" lab_scatter(dataset, class_max_num=30000, is_3d=True, is_ps_color_space=False)"
|
||||||
"model.fit(x, y=y, is_generate_negative=False, model_selection='dt')\n",
|
],
|
||||||
"model.save()"
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 数据平衡化"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 11,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"ename": "NameError",
|
||||||
|
"evalue": "name 'dataset' is not defined",
|
||||||
|
"output_type": "error",
|
||||||
|
"traceback": [
|
||||||
|
"\u001B[0;31m---------------------------------------------------------------------------\u001B[0m",
|
||||||
|
"\u001B[0;31mNameError\u001B[0m Traceback (most recent call last)",
|
||||||
|
"\u001B[0;32m/var/folders/wh/kr5c3dr12834pfk3j7yqnrq40000gn/T/ipykernel_30867/603974095.py\u001B[0m in \u001B[0;36m<module>\u001B[0;34m\u001B[0m\n\u001B[1;32m 1\u001B[0m \u001B[0mrus\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mRandomUnderSampler\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mrandom_state\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;36m0\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[0;32m----> 2\u001B[0;31m \u001B[0mx_list\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0my_list\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mnp\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mconcatenate\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0mv\u001B[0m \u001B[0;32mfor\u001B[0m \u001B[0mk\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mv\u001B[0m \u001B[0;32min\u001B[0m \u001B[0mdataset\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mitems\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m]\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0maxis\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;36m0\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mtolist\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m,\u001B[0m\u001B[0;31m \u001B[0m\u001B[0;31m\\\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[0m\u001B[1;32m 3\u001B[0m \u001B[0mnp\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mconcatenate\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0mnp\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mones\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mv\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mshape\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0;36m0\u001B[0m\u001B[0;34m]\u001B[0m\u001B[0;34m,\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m)\u001B[0m \u001B[0;34m*\u001B[0m \u001B[0mlabel_index\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0mk\u001B[0m\u001B[0;34m]\u001B[0m \u001B[0;32mfor\u001B[0m \u001B[0mk\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mv\u001B[0m \u001B[0;32min\u001B[0m \u001B[0mdataset\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mitems\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m]\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0maxis\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;36m0\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mtolist\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 4\u001B[0m \u001B[0mx_resampled\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0my_resampled\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mrus\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mfit_resample\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mx_list\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0my_list\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 5\u001B[0m \u001B[0mdataset\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0;34m{\u001B[0m\u001B[0;34m\"inside\"\u001B[0m\u001B[0;34m:\u001B[0m \u001B[0mnp\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0marray\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mx_resampled\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m}\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n",
|
||||||
|
"\u001B[0;31mNameError\u001B[0m: name 'dataset' is not defined"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"rus = RandomUnderSampler(random_state=0)\n",
|
||||||
|
"x_list, y_list = np.concatenate([v for k, v in dataset.items()], axis=0).tolist(), \\\n",
|
||||||
|
" np.concatenate([np.ones((v.shape[0],)) * label_index[k] for k, v in dataset.items()], axis=0).tolist()\n",
|
||||||
|
"x_resampled, y_resampled = rus.fit_resample(x_list, y_list)\n",
|
||||||
|
"dataset = {\"inside\": np.array(x_resampled)}"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false,
|
||||||
|
"pycharm": {
|
||||||
|
"name": "#%%\n"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "markdown",
|
||||||
|
"source": [
|
||||||
|
"## 模型训练"
|
||||||
|
],
|
||||||
|
"metadata": {
|
||||||
|
"collapsed": false
|
||||||
|
}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"cell_type": "code",
|
||||||
|
"execution_count": 12,
|
||||||
|
"outputs": [
|
||||||
|
{
|
||||||
|
"ename": "NameError",
|
||||||
|
"evalue": "name 'dataset' is not defined",
|
||||||
|
"output_type": "error",
|
||||||
|
"traceback": [
|
||||||
|
"\u001B[0;31m---------------------------------------------------------------------------\u001B[0m",
|
||||||
|
"\u001B[0;31mNameError\u001B[0m Traceback (most recent call last)",
|
||||||
|
"\u001B[0;32m/var/folders/wh/kr5c3dr12834pfk3j7yqnrq40000gn/T/ipykernel_30867/1828483636.py\u001B[0m in \u001B[0;36m<module>\u001B[0;34m\u001B[0m\n\u001B[1;32m 1\u001B[0m \u001B[0;31m# 对数据进行预处理\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[0;32m----> 2\u001B[0;31m \u001B[0mx\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mnp\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mconcatenate\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0mv\u001B[0m \u001B[0;32mfor\u001B[0m \u001B[0mk\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mv\u001B[0m \u001B[0;32min\u001B[0m \u001B[0mdataset\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mitems\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m]\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0maxis\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;36m0\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[0m\u001B[1;32m 3\u001B[0m \u001B[0mnegative_sample_num\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mint\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mx\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mshape\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0;36m0\u001B[0m\u001B[0;34m]\u001B[0m \u001B[0;34m*\u001B[0m \u001B[0;36m1.2\u001B[0m\u001B[0;34m)\u001B[0m \u001B[0;32mif\u001B[0m \u001B[0mnegative_sample_num\u001B[0m \u001B[0;32mis\u001B[0m \u001B[0;32mNone\u001B[0m \u001B[0;32melse\u001B[0m \u001B[0mnegative_sample_num\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 4\u001B[0m \u001B[0mmodel\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mAnonymousColorDetector\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n",
|
||||||
|
"\u001B[0;31mNameError\u001B[0m: name 'dataset' is not defined"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"# 对数据进行预处理\n",
|
||||||
|
"x = np.concatenate([v for k, v in dataset.items()], axis=0)\n",
|
||||||
|
"negative_sample_num = int(x.shape[0] * 1.2) if negative_sample_num is None else negative_sample_num\n",
|
||||||
|
"model = AnonymousColorDetector()"
|
||||||
],
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"collapsed": false,
|
"collapsed": false,
|
||||||
@ -142,9 +169,31 @@
|
|||||||
},
|
},
|
||||||
{
|
{
|
||||||
"cell_type": "code",
|
"cell_type": "code",
|
||||||
"execution_count": null,
|
"execution_count": 14,
|
||||||
"outputs": [],
|
"outputs": [
|
||||||
"source": [],
|
{
|
||||||
|
"ename": "NameError",
|
||||||
|
"evalue": "name 'train_from_existed' is not defined",
|
||||||
|
"output_type": "error",
|
||||||
|
"traceback": [
|
||||||
|
"\u001B[0;31m---------------------------------------------------------------------------\u001B[0m",
|
||||||
|
"\u001B[0;31mNameError\u001B[0m Traceback (most recent call last)",
|
||||||
|
"\u001B[0;32m/var/folders/wh/kr5c3dr12834pfk3j7yqnrq40000gn/T/ipykernel_30867/103680055.py\u001B[0m in \u001B[0;36m<module>\u001B[0;34m\u001B[0m\n\u001B[0;32m----> 1\u001B[0;31m \u001B[0;32mif\u001B[0m \u001B[0mtrain_from_existed\u001B[0m\u001B[0;34m:\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[0m\u001B[1;32m 2\u001B[0m \u001B[0mdata\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mscipy\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mio\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mloadmat\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mdataset_file\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 3\u001B[0m \u001B[0mx\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0my\u001B[0m \u001B[0;34m=\u001B[0m \u001B[0mdata\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0;34m'x'\u001B[0m\u001B[0;34m]\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mdata\u001B[0m\u001B[0;34m[\u001B[0m\u001B[0;34m'y'\u001B[0m\u001B[0;34m]\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mravel\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 4\u001B[0m \u001B[0mmodel\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0mfit\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0mx\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0my\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0my\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mis_generate_negative\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;32mFalse\u001B[0m\u001B[0;34m,\u001B[0m \u001B[0mmodel_selection\u001B[0m\u001B[0;34m=\u001B[0m\u001B[0;34m'dt'\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n\u001B[1;32m 5\u001B[0m \u001B[0mmodel\u001B[0m\u001B[0;34m.\u001B[0m\u001B[0msave\u001B[0m\u001B[0;34m(\u001B[0m\u001B[0;34m)\u001B[0m\u001B[0;34m\u001B[0m\u001B[0;34m\u001B[0m\u001B[0m\n",
|
||||||
|
"\u001B[0;31mNameError\u001B[0m: name 'train_from_existed' is not defined"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"source": [
|
||||||
|
"if train_from_existed:\n",
|
||||||
|
" data = scipy.io.loadmat(dataset_file)\n",
|
||||||
|
" x, y = data['x'], data['y'].ravel()\n",
|
||||||
|
" model.fit(x, y=y, is_generate_negative=False, model_selection='dt')\n",
|
||||||
|
"else:\n",
|
||||||
|
" world_boundary = np.array([0, 0, 0, 255, 255, 255])\n",
|
||||||
|
" model.fit(x, world_boundary, threshold, negative_sample_size=negative_sample_num, train_size=0.7,\n",
|
||||||
|
" is_save_dataset=True, model_selection='dt')\n",
|
||||||
|
"model.save()"
|
||||||
|
],
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"collapsed": false,
|
"collapsed": false,
|
||||||
"pycharm": {
|
"pycharm": {
|
||||||
|
|||||||
66
README.md
66
README.md
@ -2,4 +2,68 @@
|
|||||||
|
|
||||||
2022年7月18日开始开发的项目,使用彩色相机进行烟梗颜色的识别。
|
2022年7月18日开始开发的项目,使用彩色相机进行烟梗颜色的识别。
|
||||||
|
|
||||||
项目中的数据放置于[链接](https://macrosolid-my.sharepoint.com/:f:/g/personal/feijinti_miaow_fun/ElIAerke0rVMjcSyrbjetAYBpide1s-rPEY9JDZWrrhiUA?e=hrzOfa)
|
## 如何进行模型训练和部署?
|
||||||
|
1. 项目当中需要包含`data`和`models`这两个文件夹,请下载到当前文件夹下,这是链接:[data](https://macrosolid-my.sharepoint.com/personal/feijinti_miaow_fun/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Ffeijinti%5Fmiaow%5Ffun%2FDocuments%2FPycharmProjects%2Ftobacco%5Fcolor%2Fdata&ga=1), [models](https://macrosolid-my.sharepoint.com/:f:/g/personal/feijinti_miaow_fun/EiyBjWEX90JGn8S-e5Kh7N8B1GWvfvDcNbpleWDTwkDm1w?e=wyL4EF)
|
||||||
|
2. 使用[01_dataset.ipynb](./01_dataset.ipynb) 进行数据集的分析文件格式需要设置为这种形式:
|
||||||
|
```text
|
||||||
|
dataset
|
||||||
|
├── label
|
||||||
|
│ ├── img1.bmp
|
||||||
|
│ └── ...
|
||||||
|
└── img
|
||||||
|
├── img1.bmp
|
||||||
|
└── ...
|
||||||
|
```
|
||||||
|
3. 使用[02_classification.ipynb](./02_classification.ipynb)进行训练
|
||||||
|
4. 使用[03_data_update.ipynb](02_classification.ipynb)进行数据的更新与添加
|
||||||
|
5. 使用`main_test.py`文件进行读图测试
|
||||||
|
6. **部署**,复制`utils.py`、`models.py`、`main.py`、`models`、`config.py`这5个文件或文件夹,运行main.py来提供预测服务。
|
||||||
|
|
||||||
|
|
||||||
|
## 训练的原理
|
||||||
|
为了应对工业环境当中负样本少的特点,我们结合颜色有限空间的特性对我们的训练过程进行了优化,核心的优化方式在于制造负样本
|
||||||
|
|
||||||
|
### 负样本是怎么造出来的?
|
||||||
|
|
||||||
|
我们对于一个给定的色彩空间进行随机的生成一些数据,然后判断它是否是给定的正样本附近,如果是在附近,那么我们就把这些点看作是正样本,如果离得比较远,那么就会被当作是负样本。
|
||||||
|
|
||||||
|
### 训练的结果
|
||||||
|
|
||||||
|
这样子进行训练,模型就会被约束在我们给定的样本范围内,就像你看到的这样。
|
||||||
|
|
||||||
|
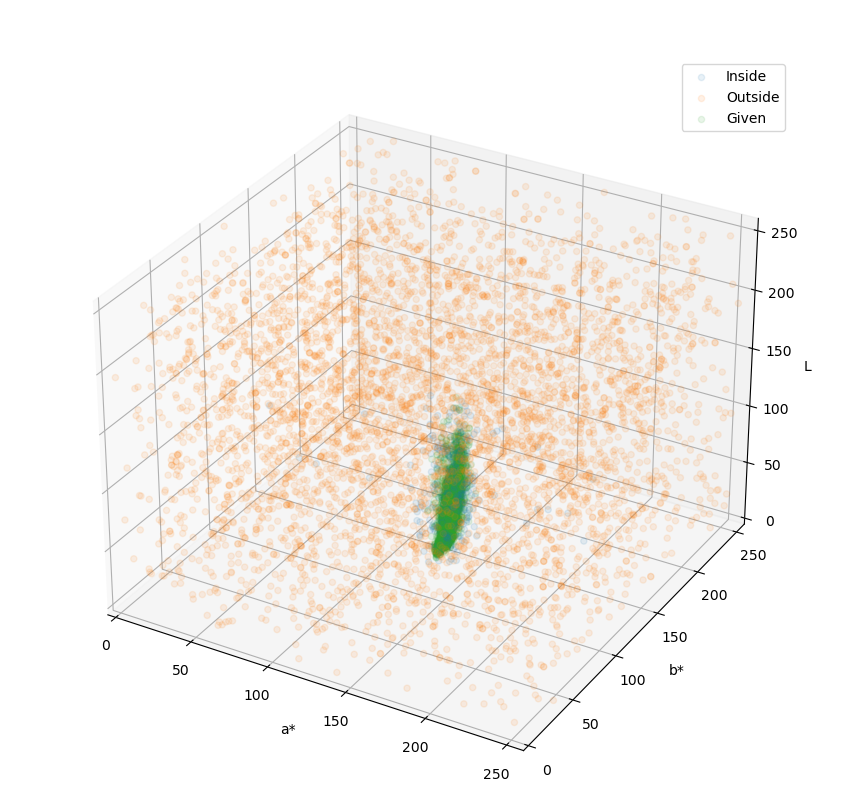
|
||||||
|
|
||||||
|
在这里,绿色就是目标的色彩范围,橙色的和蓝色则表明了模型的判定范围,模型认为蓝色的区域就是烟梗,而橙色的区域就不是烟梗。
|
||||||
|
|
||||||
|
可以看到,蓝色区域与绿色区域是高度重叠的,并且蓝色比绿色区域要大一些的,这正是我们想要的效果。这表明模型对于烟梗的颜色有适度的宽容,允许色彩有一定的偏差,但大体上是要达到烟梗颜色范围内的。
|
||||||
|
|
||||||
|
这样的好处在于,即使出现了新的杂质,只要这些杂质的色彩不在模型的宽容范围内(蓝色范围内),那么都会被判定为杂质。
|
||||||
|
|
||||||
|
## 预测过程的后处理(异色问题)
|
||||||
|
|
||||||
|
### 问题的发现
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在摄影过程中,由于相机、镜头和拍摄物体多方面的原因会出现色散边的现象,就像上图这样本来应该黄色的烟梗,边缘却变成了绿色或紫色的。
|
||||||
|
|
||||||
|
这是由于不同波长的光折射率不同,到达成像单元的位置会出现细小的偏差,而我们的成像单元又比较的细小,举例来说,这可能使得物体上同样的点发出的红光到了1号像素,而发出的绿光本来应该也射到1号像素却射到了相邻的2号像素,这就导致色彩不对了。
|
||||||
|
|
||||||
|
根据资料,一般的解决方案是对于不同波长的光进行折射率补偿,使用抗色散镜头。
|
||||||
|
|
||||||
|
## 镜头的影响
|
||||||
|
|
||||||
|
我们现有的镜头包括广角和窄角两个,这两个镜头有着不同的成像效果,如下图所示。
|
||||||
|
|
||||||
|
| 视角 | 广角镜头 | 窄角镜头 |
|
||||||
|
| -------- | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
||||||
|
| 普通视角 |  |  |
|
||||||
|
|
||||||
|
但是由于条件有限,我们这里就只能用算法的形式硬抗这些误差了。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 模型的更新
|
||||||
|
|
||||||
|
### 如何应对新的目标物?
|
||||||
|
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user