mirror of
https://github.com/NanjingForestryUniversity/supermachine-tobacco.git
synced 2025-11-08 22:33:54 +00:00
烟草分选机算法部分
| .gitignore | ||
| 01_dataset.ipynb | ||
| 02_classification.ipynb | ||
| 02_classification.py | ||
| 03_data_update.ipynb | ||
| 04_multi_classification.ipynb | ||
| elm.py | ||
| main_test.py | ||
| models.py | ||
| README.md | ||
| utils.py | ||
烟梗彩色相机识别
2022年7月18日开始开发的项目,使用彩色相机进行烟梗颜色的识别。
如何进行模型训练和部署?
- 项目当中需要包含
data和models这两个文件夹,请下载到当前文件夹下,这是链接:data, models - 使用01_dataset.ipynb 进行数据集的分析文件格式需要设置为这种形式:
dataset ├── label │ ├── img1.bmp │ └── ... └── img ├── img1.bmp └── ... - 使用02_classification.ipynb进行训练
- 使用03_data_update.ipynb进行数据的更新与添加
- 使用
main_test.py文件进行读图测试 - 部署,复制
utils.py、models.py、main.py、models、config.py这5个文件或文件夹,运行main.py来提供预测服务。
训练的原理
为了应对工业环境当中负样本少的特点,我们结合颜色有限空间的特性对我们的训练过程进行了优化,核心的优化方式在于制造负样本
负样本是怎么造出来的?
我们对于一个给定的色彩空间进行随机的生成一些数据,然后判断它是否是给定的正样本附近,如果是在附近,那么我们就把这些点看作是正样本,如果离得比较远,那么就会被当作是负样本。
训练的结果
这样子进行训练,模型就会被约束在我们给定的样本范围内,就像你看到的这样。
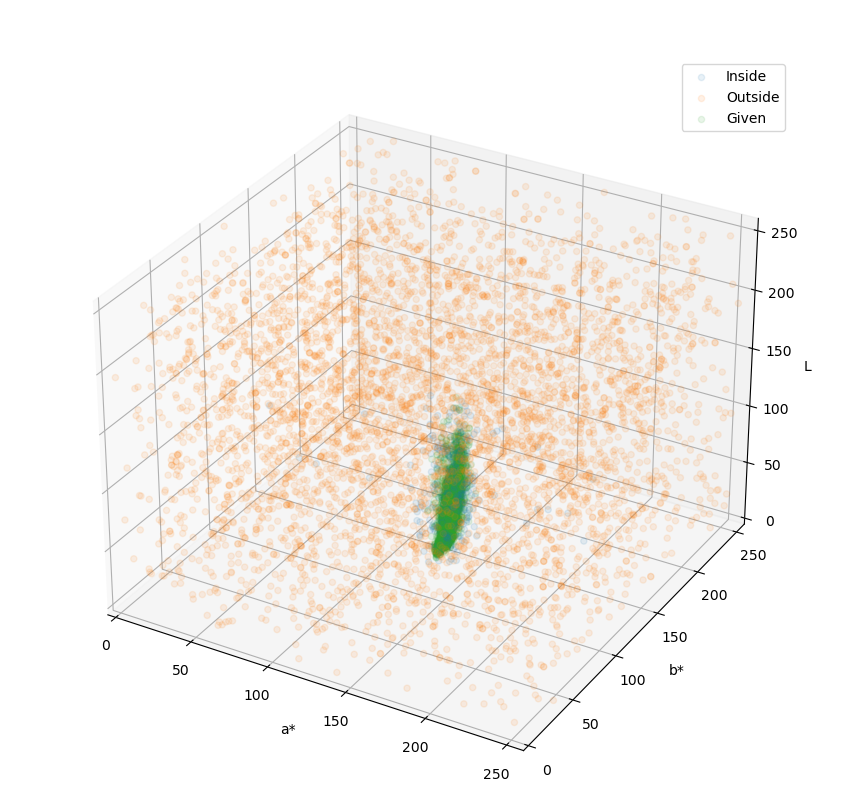
在这里,绿色就是目标的色彩范围,橙色的和蓝色则表明了模型的判定范围,模型认为蓝色的区域就是烟梗,而橙色的区域就不是烟梗。
可以看到,蓝色区域与绿色区域是高度重叠的,并且蓝色比绿色区域要大一些的,这正是我们想要的效果。这表明模型对于烟梗的颜色有适度的宽容,允许色彩有一定的偏差,但大体上是要达到烟梗颜色范围内的。
这样的好处在于,即使出现了新的杂质,只要这些杂质的色彩不在模型的宽容范围内(蓝色范围内),那么都会被判定为杂质。
预测过程的后处理(异色问题)
问题的发现
在摄影过程中,由于相机、镜头和拍摄物体多方面的原因会出现色散边的现象,就像上图这样本来应该黄色的烟梗,边缘却变成了绿色或紫色的。
这是由于不同波长的光折射率不同,到达成像单元的位置会出现细小的偏差,而我们的成像单元又比较的细小,举例来说,这可能使得物体上同样的点发出的红光到了1号像素,而发出的绿光本来应该也射到1号像素却射到了相邻的2号像素,这就导致色彩不对了。
根据资料,一般的解决方案是对于不同波长的光进行折射率补偿,使用抗色散镜头。
镜头的影响
我们现有的镜头包括广角和窄角两个,这两个镜头有着不同的成像效果,如下图所示。
| 视角 | 广角镜头 | 窄角镜头 |
|---|---|---|
| 普通视角 |  |
 |
但是由于条件有限,我们这里就只能用算法的形式硬抗这些误差了。